 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBacktracking When It Strays: Mitigating Dual Exposure Biases in LLM Reasoning Distillation
May 19, 2026Large language models (LLMs) have achieved remarkable success in complex reasoning tasks via long chain-of-thought (CoT), yet their immense computational overhead hinders real-world deployment. LLM reasoning distillation addresses this by transferring reasoning capabilities from formidable teacher models to compact student models. However, existing distillation paradigms face a fundamental dilemma. Typical off-policy distillation strictly utilizes teacher-generated golden trajectories, suffering from an exposure bias due to the mismatch between training distributions and student-generated inference contexts, which leads to error cascades in long CoT reasoning. To address this, on-policy distillation allows students to explore their own trajectories, but we demonstrate that it inherently introduces a reciprocal reversed exposure bias: the teacher model also struggles to provide positive guidance when conditioned on student-generated sub-optimal contexts. To resolve this dual exposure biases problem, we propose Monitoring Trajectories and Backtracking when it strays (MOTAB), a new LLM reasoning distillation pipeline. Specifically, MOTAB dynamically monitors the student's on-policy generation against an adaptive safety boundary. When the generation strays and exceeds this threshold, MOTAB backtracks to the last safe state and leverages teacher intervention to correct the course. This approach inherently tolerates minor student errors to mitigate exposure bias, while preventing sub-optimal contexts to circumvent reversed exposure bias. Extensive experiments on the LIMO-v2 and AceReason datasets demonstrate that MOTAB effectively alleviates the dual exposure biases, yielding a roughly 3% average performance improvement in reasoning tasks.
Are Rationales Necessary and Sufficient? Tuning LLMs for Explainable Misinformation Detection
May 19, 2026The rapid spread of misinformation on social media platforms has become a formidable challenge. To mitigate its proliferation, Misinformation Detection (MD) has emerged as a critical research topic. Traditional MD approaches based on small models typically perform binary classification through a black-box process. Recently, the rise of Large Language Models (LLMs) has enabled explainable MD, where models generate rationales that explain their decisions, thereby enhancing transparency. Existing explainable MD methods primarily focus on crafting sophisticated prompts to elicit rationales from off-the-shelf LLMs. In this work, we propose a pipeline to fine-tune a dedicated LLM specifically for explainable MD. Our pipeline begins by collecting large-scale fact-checked articles, and then uses multiple strong LLMs to produce veracity predictions and rationales. To ensure high-quality training data, we leverage a filtering strategy that selects only the correct instances for fine-tuning. While this pipeline is intuitive and prevalent, our experiments reveal that naive filtering based solely on label correctness is insufficient in practice and suffers from two critical limitations: (1) Coarse-grained labels cause insufficient rationales: Rationales filtered solely based on binary labels are insufficient to adequately support their decisions; (2) Over-verification behavior causes unnecessary rationales: Stronger LLMs tend to exhibit over-verification behavior, producing excessively verbose and unnecessary rationales. To address these issues, we introduce LONSREX, a novel data synthesis pipeline to Locate Necessary and Sufficient Rationales for Explainable MD. Specifically, we propose a metric that quantifies the contribution of each verification step to the final prediction, thereby evaluating its necessity and sufficiency. Experimental results demonstrate the effectiveness of LONSREX.
On the Step Length Confounding in LLM Reasoning Data Selection
Apr 08, 2026Large reasoning models have recently demonstrated strong performance on complex tasks that require long chain-of-thought reasoning, through supervised fine-tuning on large-scale and high-quality datasets. To construct such datasets, existing pipelines generate long reasoning data from more capable Large Language Models (LLMs) and apply manually heuristic or naturalness-based selection methods to filter high-quality samples. Despite the proven effectiveness of naturalness-based data selection, which ranks data by the average log probability assigned by LLMs, our analysis shows that, when applied to LLM reasoning datasets, it systematically prefers samples with longer reasoning steps (i.e., more tokens per step) rather than higher-quality ones, a phenomenon we term step length confounding. Through quantitative analysis, we attribute this phenomenon to low-probability first tokens in reasoning steps; longer steps dilute their influence, thereby inflating the average log probabilities. To address this issue, we propose two variant methods: ASLEC-DROP, which drops first-token probabilities when computing average log probability, and ASLEC-CASL, which applies a causal debiasing regression to remove the first tokens' confounding effect. Experiments across four LLMs and five evaluation benchmarks demonstrate the effectiveness of our approach in mitigating the step length confounding problem.
Through the Lens of Contrast: Self-Improving Visual Reasoning in VLMs
Mar 03, 2026Reasoning has emerged as a key capability of large language models. In linguistic tasks, this capability can be enhanced by self-improving techniques that refine reasoning paths for subsequent finetuning. However, extending these language-based self-improving approaches to vision language models (VLMs) presents a unique challenge:~visual hallucinations in reasoning paths cannot be effectively verified or rectified. Our solution starts with a key observation about visual contrast: when presented with a contrastive VQA pair, i.e., two visually similar images with synonymous questions, VLMs identify relevant visual cues more precisely. Motivated by this observation, we propose Visual Contrastive Self-Taught Reasoner (VC-STaR), a novel self-improving framework that leverages visual contrast to mitigate hallucinations in model-generated rationales. We collect a diverse suite of VQA datasets, curate contrastive pairs according to multi-modal similarity, and generate rationales using VC-STaR. Consequently, we obtain a new visual reasoning dataset, VisCoR-55K, which is then used to boost the reasoning capability of various VLMs through supervised finetuning. Extensive experiments show that VC-STaR not only outperforms existing self-improving approaches but also surpasses models finetuned on the SoTA visual reasoning datasets, demonstrating that the inherent contrastive ability of VLMs can bootstrap their own visual reasoning. Project at: https://github.com/zhiyupan42/VC-STaR.
Distribution-Aligned Sequence Distillation for Superior Long-CoT Reasoning
Jan 14, 2026In this report, we introduce DASD-4B-Thinking, a lightweight yet highly capable, fully open-source reasoning model. It achieves SOTA performance among open-source models of comparable scale across challenging benchmarks in mathematics, scientific reasoning, and code generation -- even outperforming several larger models. We begin by critically reexamining a widely adopted distillation paradigm in the community: SFT on teacher-generated responses, also known as sequence-level distillation. Although a series of recent works following this scheme have demonstrated remarkable efficiency and strong empirical performance, they are primarily grounded in the SFT perspective. Consequently, these approaches focus predominantly on designing heuristic rules for SFT data filtering, while largely overlooking the core principle of distillation itself -- enabling the student model to learn the teacher's full output distribution so as to inherit its generalization capability. Specifically, we identify three critical limitations in current practice: i) Inadequate representation of the teacher's sequence-level distribution; ii) Misalignment between the teacher's output distribution and the student's learning capacity; and iii) Exposure bias arising from teacher-forced training versus autoregressive inference. In summary, these shortcomings reflect a systemic absence of explicit teacher-student interaction throughout the distillation process, leaving the essence of distillation underexploited. To address these issues, we propose several methodological innovations that collectively form an enhanced sequence-level distillation training pipeline. Remarkably, DASD-4B-Thinking obtains competitive results using only 448K training samples -- an order of magnitude fewer than those employed by most existing open-source efforts. To support community research, we publicly release our models and the training dataset.
Where Did This Sentence Come From? Tracing Provenance in LLM Reasoning Distillation
Dec 24, 2025Reasoning distillation has attracted increasing attention. It typically leverages a large teacher model to generate reasoning paths, which are then used to fine-tune a student model so that it mimics the teacher's behavior in training contexts. However, previous approaches have lacked a detailed analysis of the origins of the distilled model's capabilities. It remains unclear whether the student can maintain consistent behaviors with the teacher in novel test-time contexts, or whether it regresses to its original output patterns, raising concerns about the generalization of distillation models. To analyse this question, we introduce a cross-model Reasoning Distillation Provenance Tracing framework. For each action (e.g., a sentence) produced by the distilled model, we obtain the predictive probabilities assigned by the teacher, the original student, and the distilled model under the same context. By comparing these probabilities, we classify each action into different categories. By systematically disentangling the provenance of each action, we experimentally demonstrate that, in test-time contexts, the distilled model can indeed generate teacher-originated actions, which correlate with and plausibly explain observed performance on distilled model. Building on this analysis, we further propose a teacher-guided data selection method. Unlike prior approach that rely on heuristics, our method directly compares teacher-student divergences on the training data, providing a principled selection criterion. We validate the effectiveness of our approach across multiple representative teacher models and diverse student models. The results highlight the utility of our provenance-tracing framework and underscore its promise for reasoning distillation. We hope to share Reasoning Distillation Provenance Tracing and our insights into reasoning distillation with the community.
Enhancing Large Language Models with Reward-guided Tree Search for Knowledge Graph Question and Answering
May 18, 2025Recently, large language models (LLMs) have demonstrated impressive performance in Knowledge Graph Question Answering (KGQA) tasks, which aim to find answers based on knowledge graphs (KGs) for natural language questions. Existing LLMs-based KGQA methods typically follow the Graph Retrieval-Augmented Generation (GraphRAG) paradigm, which first retrieves reasoning paths from the large KGs, and then generates the answers based on them. However, these methods emphasize the exploration of new optimal reasoning paths in KGs while ignoring the exploitation of historical reasoning paths, which may lead to sub-optimal reasoning paths. Additionally, the complex semantics contained in questions may lead to the retrieval of inaccurate reasoning paths. To address these issues, this paper proposes a novel and training-free framework for KGQA tasks called Reward-guided Tree Search on Graph (RTSoG). RTSoG decomposes an original question into a series of simpler and well-defined sub-questions to handle the complex semantics. Then, a Self-Critic Monte Carlo Tree Search (SC-MCTS) guided by a reward model is introduced to iteratively retrieve weighted reasoning paths as contextual knowledge. Finally, it stacks the weighted reasoning paths according to their weights to generate the final answers. Extensive experiments on four datasets demonstrate the effectiveness of RTSoG. Notably, it achieves 8.7\% and 7.0\% performance improvement over the state-of-the-art method on the GrailQA and the WebQSP respectively.
Don't Take Things Out of Context: Attention Intervention for Enhancing Chain-of-Thought Reasoning in Large Language Models
Mar 14, 2025Few-shot Chain-of-Thought (CoT) significantly enhances the reasoning capabilities of large language models (LLMs), functioning as a whole to guide these models in generating reasoning steps toward final answers. However, we observe that isolated segments, words, or tokens within CoT demonstrations can unexpectedly disrupt the generation process of LLMs. The model may overly concentrate on certain local information present in the demonstration, introducing irrelevant noise into the reasoning process and potentially leading to incorrect answers. In this paper, we investigate the underlying mechanism of CoT through dynamically tracing and manipulating the inner workings of LLMs at each output step, which demonstrates that tokens exhibiting specific attention characteristics are more likely to induce the model to take things out of context; these tokens directly attend to the hidden states tied with prediction, without substantial integration of non-local information. Building upon these insights, we propose a Few-shot Attention Intervention method (FAI) that dynamically analyzes the attention patterns of demonstrations to accurately identify these tokens and subsequently make targeted adjustments to the attention weights to effectively suppress their distracting effect on LLMs. Comprehensive experiments across multiple benchmarks demonstrate consistent improvements over baseline methods, with a remarkable 5.91% improvement on the AQuA dataset, further highlighting the effectiveness of FAI.
Seeing Clearly by Layer Two: Enhancing Attention Heads to Alleviate Hallucination in LVLMs
Nov 15, 2024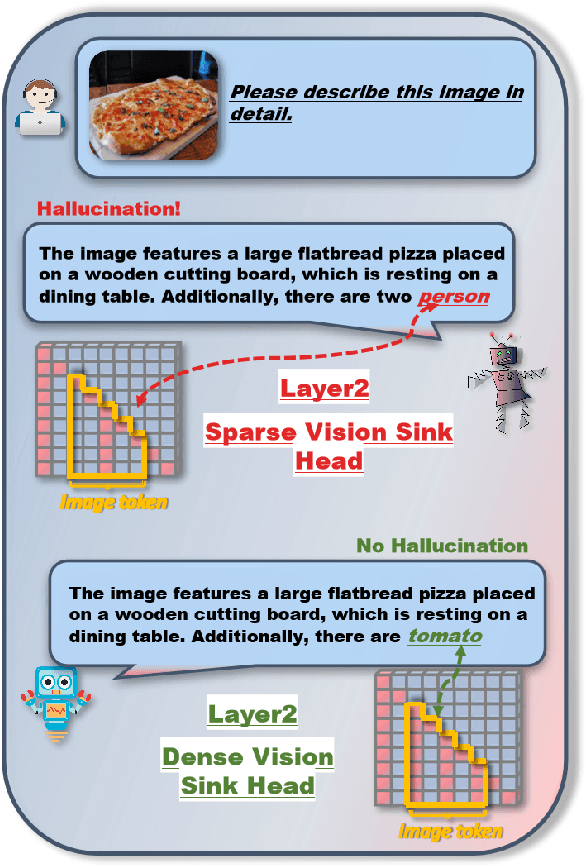
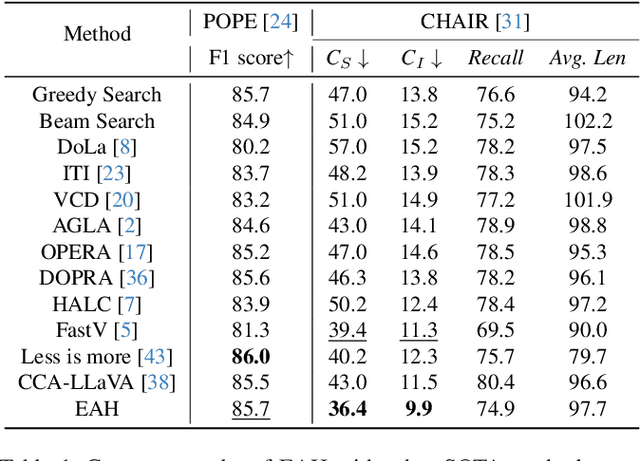
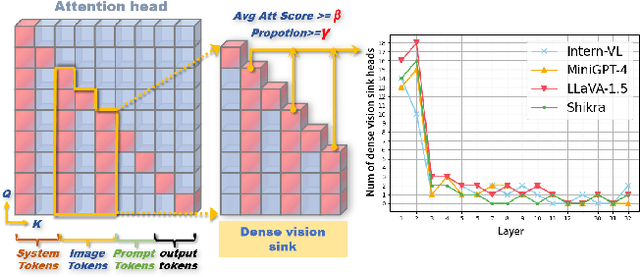
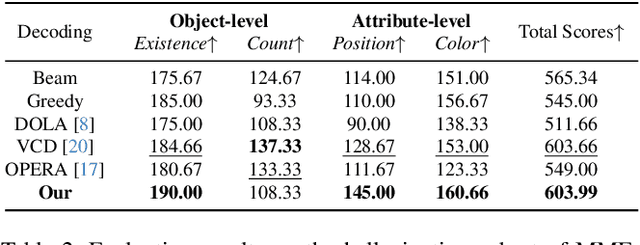
The hallucination problem in multimodal large language models (MLLMs) remains a common issue. Although image tokens occupy a majority of the input sequence of MLLMs, there is limited research to explore the relationship between image tokens and hallucinations. In this paper, we analyze the distribution of attention scores for image tokens across each layer and head of the model, revealing an intriguing and common phenomenon: most hallucinations are closely linked to the pattern of attention sinks in the self-attention matrix of image tokens, where shallow layers exhibit dense attention sinks and deeper layers show sparse attention sinks. We further analyze the attention heads of different layers and find that heads with high-density attention sink in the image part play a positive role in alleviating hallucinations. In this paper, we propose a training-free method named \textcolor{red}{\textbf{E}}nhancing \textcolor{red}{\textbf{A}}ttention \textcolor{red}{\textbf{H}}eads (EAH), an approach designed to enhance the convergence of image tokens attention sinks in the shallow layers. EAH identifies the attention head that shows the vision sink in a shallow layer and extracts its attention matrix. This attention map is then broadcast to other heads in the layer, thereby strengthening the layer to pay more attention to the image itself. With extensive experiments, EAH shows significant hallucination-mitigating performance on different MLLMs and metrics, proving its effectiveness and generality.
Instance-adaptive Zero-shot Chain-of-Thought Prompting
Sep 30, 2024



Zero-shot Chain-of-Thought (CoT) prompting emerges as a simple and effective strategy for enhancing the performance of large language models (LLMs) in real-world reasoning tasks. Nonetheless, the efficacy of a singular, task-level prompt uniformly applied across the whole of instances is inherently limited since one prompt cannot be a good partner for all, a more appropriate approach should consider the interaction between the prompt and each instance meticulously. This work introduces an instance-adaptive prompting algorithm as an alternative zero-shot CoT reasoning scheme by adaptively differentiating good and bad prompts. Concretely, we first employ analysis on LLMs through the lens of information flow to detect the mechanism under zero-shot CoT reasoning, in which we discover that information flows from question to prompt and question to rationale jointly influence the reasoning results most. We notice that a better zero-shot CoT reasoning needs the prompt to obtain semantic information from the question then the rationale aggregates sufficient information from the question directly and via the prompt indirectly. On the contrary, lacking any of those would probably lead to a bad one. Stem from that, we further propose an instance-adaptive prompting strategy (IAP) for zero-shot CoT reasoning. Experiments conducted with LLaMA-2, LLaMA-3, and Qwen on math, logic, and commonsense reasoning tasks (e.g., GSM8K, MMLU, Causal Judgement) obtain consistent improvement, demonstrating that the instance-adaptive zero-shot CoT prompting performs better than other task-level methods with some curated prompts or sophisticated procedures, showing the significance of our findings in the zero-shot CoT reasoning mechanism.