 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Step Length Confounding in LLM Reasoning Data Selection
Apr 08, 2026Large reasoning models have recently demonstrated strong performance on complex tasks that require long chain-of-thought reasoning, through supervised fine-tuning on large-scale and high-quality datasets. To construct such datasets, existing pipelines generate long reasoning data from more capable Large Language Models (LLMs) and apply manually heuristic or naturalness-based selection methods to filter high-quality samples. Despite the proven effectiveness of naturalness-based data selection, which ranks data by the average log probability assigned by LLMs, our analysis shows that, when applied to LLM reasoning datasets, it systematically prefers samples with longer reasoning steps (i.e., more tokens per step) rather than higher-quality ones, a phenomenon we term step length confounding. Through quantitative analysis, we attribute this phenomenon to low-probability first tokens in reasoning steps; longer steps dilute their influence, thereby inflating the average log probabilities. To address this issue, we propose two variant methods: ASLEC-DROP, which drops first-token probabilities when computing average log probability, and ASLEC-CASL, which applies a causal debiasing regression to remove the first tokens' confounding effect. Experiments across four LLMs and five evaluation benchmarks demonstrate the effectiveness of our approach in mitigating the step length confounding problem.
Reasoning Fails Where Step Flow Breaks
Apr 08, 2026Large reasoning models (LRMs) that generate long chains of thought now perform well on multi-step math, science, and coding tasks. However, their behavior is still unstable and hard to interpret, and existing analysis tools struggle with such long, structured reasoning traces. We introduce Step-Saliency, which pools attention--gradient scores into step-to-step maps along the question--thinking--summary trajectory. Across several models, Step-Saliency reveals two recurring information-flow failures: Shallow Lock-in, where shallow layers over-focus on the current step and barely use earlier context, and Deep Decay, where deep layers gradually lose saliency on the thinking segment and the summary increasingly attends to itself and the last few steps. Motivated by these patterns, we propose StepFlow, a saliency-inspired test-time intervention that adjusts shallow saliency patterns measured by Step-Saliency via Odds-Equal Bridge and adds a small step-level residual in deep layers via Step Momentum Injection. StepFlow improves accuracy on math, science, and coding tasks across multiple LRMs without retraining, indicating that repairing information flow can recover part of their missing reasoning performance.
ART: Attention Replacement Technique to Improve Factuality in LLMs
Apr 07, 2026Hallucination in large language models (LLMs) continues to be a significant issue, particularly in tasks like question answering, where models often generate plausible yet incorrect or irrelevant information. Although various methods have been proposed to mitigate hallucinations, the relationship between attention patterns and hallucinations has not been fully explored. In this paper, we analyze the distribution of attention scores across each layer and attention head of LLMs, revealing a common and intriguing phenomenon: shallow layers of LLMs primarily rely on uniform attention patterns, where the model distributes its attention evenly across the entire sequence. This uniform attention pattern can lead to hallucinations, as the model fails to focus on the most relevant information. To mitigate this issue, we propose a training-free method called Attention Replacement Technique (ART), which replaces these uniform attention patterns in the shallow layers with local attention patterns. This change directs the model to focus more on the relevant contexts, thus reducing hallucinations. Through extensive experiments, ART demonstrates significant reductions in hallucinations across multiple LLM architectures, proving its effectiveness and generalizability without requiring fine-tuning or additional training data.
Hallucination Begins Where Saliency Drops
Jan 28, 2026Recent studies have examined attention dynamics in large vision-language models (LVLMs) to detect hallucinations. However, existing approaches remain limited in reliably distinguishing hallucinated from factually grounded outputs, as they rely solely on forward-pass attention patterns and neglect gradient-based signals that reveal how token influence propagates through the network. To bridge this gap, we introduce LVLMs-Saliency, a gradient-aware diagnostic framework that quantifies the visual grounding strength of each output token by fusing attention weights with their input gradients. Our analysis uncovers a decisive pattern: hallucinations frequently arise when preceding output tokens exhibit low saliency toward the prediction of the next token, signaling a breakdown in contextual memory retention. Leveraging this insight, we propose a dual-mechanism inference-time framework to mitigate hallucinations: (1) Saliency-Guided Rejection Sampling (SGRS), which dynamically filters candidate tokens during autoregressive decoding by rejecting those whose saliency falls below a context-adaptive threshold, thereby preventing coherence-breaking tokens from entering the output sequence; and (2) Local Coherence Reinforcement (LocoRE), a lightweight, plug-and-play module that strengthens attention from the current token to its most recent predecessors, actively counteracting the contextual forgetting behavior identified by LVLMs-Saliency. Extensive experiments across multiple LVLMs demonstrate that our method significantly reduces hallucination rates while preserving fluency and task performance, offering a robust and interpretable solution for enhancing model reliability. Code is available at: https://github.com/zhangbaijin/LVLMs-Saliency
Context Tokens are Anchors: Understanding the Repetition Curse in dMLLMs from an Information Flow Perspective
Jan 28, 2026Recent diffusion-based Multimodal Large Language Models (dMLLMs) suffer from high inference latency and therefore rely on caching techniques to accelerate decoding. However, the application of cache mechanisms often introduces undesirable repetitive text generation, a phenomenon we term the \textbf{Repeat Curse}. To better investigate underlying mechanism behind this issue, we analyze repetition generation through the lens of information flow. Our work reveals three key findings: (1) context tokens aggregate semantic information as anchors and guide the final predictions; (2) as information propagates across layers, the entropy of context tokens converges in deeper layers, reflecting the model's growing prediction certainty; (3) Repetition is typically linked to disruptions in the information flow of context tokens and to the inability of their entropy to converge in deeper layers. Based on these insights, we present \textbf{CoTA}, a plug-and-play method for mitigating repetition. CoTA enhances the attention of context tokens to preserve intrinsic information flow patterns, while introducing a penalty term to the confidence score during decoding to avoid outputs driven by uncertain context tokens. With extensive experiments, CoTA demonstrates significant effectiveness in alleviating repetition and achieves consistent performance improvements on general tasks. Code is available at https://github.com/ErikZ719/CoTA
Efficient Reasoning Through Suppression of Self-Affirmation Reflections in Large Reasoning Models
Jun 14, 2025
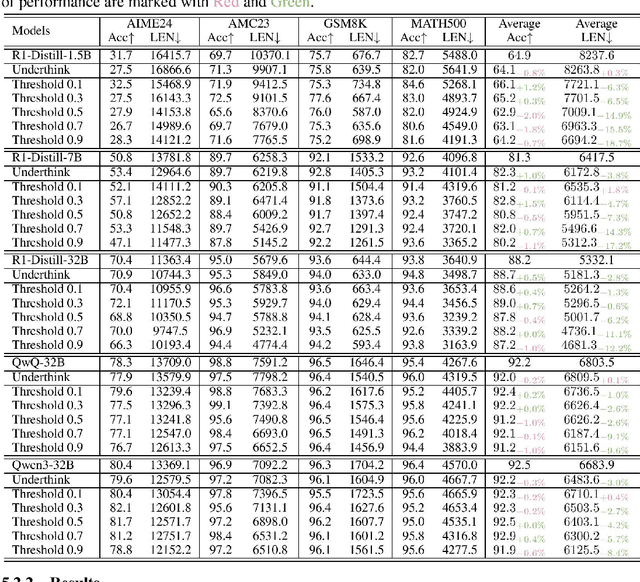
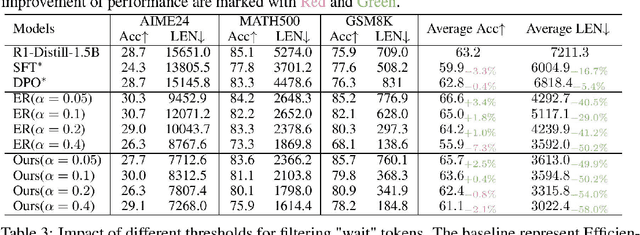
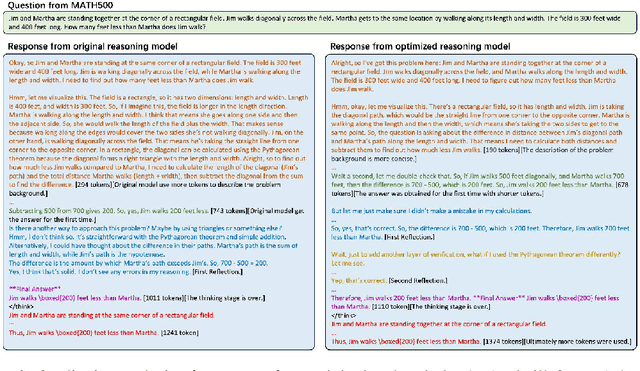
While recent advances in large reasoning models have demonstrated remarkable performance, efficient reasoning remains critical due to the rapid growth of output length. Existing optimization approaches highlights a tendency toward "overthinking", yet lack fine-grained analysis. In this work, we focus on Self-Affirmation Reflections: redundant reflective steps that affirm prior content and often occurs after the already correct reasoning steps. Observations of both original and optimized reasoning models reveal pervasive self-affirmation reflections. Notably, these reflections sometimes lead to longer outputs in optimized models than their original counterparts. Through detailed analysis, we uncover an intriguing pattern: compared to other reflections, the leading words (i.e., the first word of sentences) in self-affirmation reflections exhibit a distinct probability bias. Motivated by this insight, we can locate self-affirmation reflections and conduct a train-free experiment demonstrating that suppressing self-affirmation reflections reduces output length without degrading accuracy across multiple models (R1-Distill-Models, QwQ-32B, and Qwen3-32B). Furthermore, we also improve current train-based method by explicitly suppressing such reflections. In our experiments, we achieve length compression of 18.7\% in train-free settings and 50.2\% in train-based settings for R1-Distill-Qwen-1.5B. Moreover, our improvements are simple yet practical and can be directly applied to existing inference frameworks, such as vLLM. We believe that our findings will provide community insights for achieving more precise length compression and step-level efficient reasoning.
Improving Complex Reasoning with Dynamic Prompt Corruption: A soft prompt Optimization Approach
Mar 17, 2025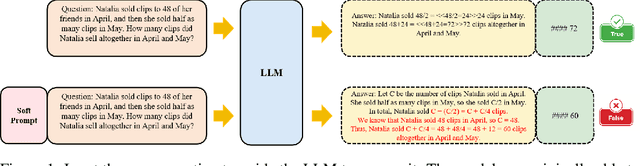

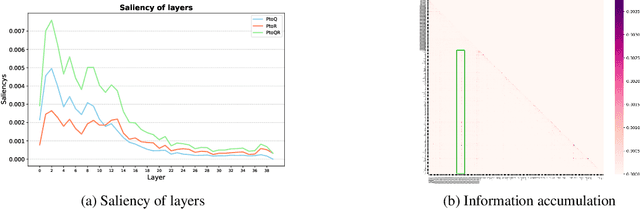

Prompt-tuning (PT) for large language models (LLMs) can facilitate the performance on various conventional NLP tasks with significantly fewer trainable parameters. However, our investigation reveals that PT provides limited improvement and may even degrade the primitive performance of LLMs on complex reasoning tasks. Such a phenomenon suggests that soft prompts can positively impact certain instances while negatively affecting others, particularly during the later phases of reasoning. To address these challenges, We first identify an information accumulation within the soft prompts. Through detailed analysis, we demonstrate that this phenomenon is often accompanied by erroneous information flow patterns in the deeper layers of the model, which ultimately lead to incorrect reasoning outcomes. we propose a novel method called \textbf{D}ynamic \textbf{P}rompt \textbf{C}orruption (DPC) to take better advantage of soft prompts in complex reasoning tasks, which dynamically adjusts the influence of soft prompts based on their impact on the reasoning process. Specifically, DPC consists of two stages: Dynamic Trigger and Dynamic Corruption. First, Dynamic Trigger measures the impact of soft prompts, identifying whether beneficial or detrimental. Then, Dynamic Corruption mitigates the negative effects of soft prompts by selectively masking key tokens that interfere with the reasoning process. We validate the proposed approach through extensive experiments on various LLMs and reasoning tasks, including GSM8K, MATH, and AQuA. Experimental results demonstrate that DPC can consistently enhance the performance of PT, achieving 4\%-8\% accuracy gains compared to vanilla prompt tuning, highlighting the effectiveness of our approach and its potential to enhance complex reasoning in LLMs.
Seeing Clearly by Layer Two: Enhancing Attention Heads to Alleviate Hallucination in LVLMs
Nov 15, 2024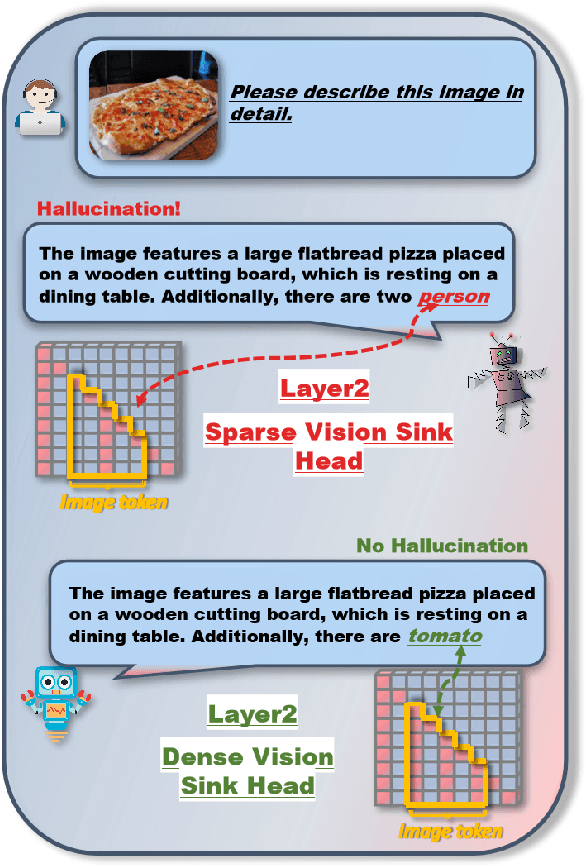
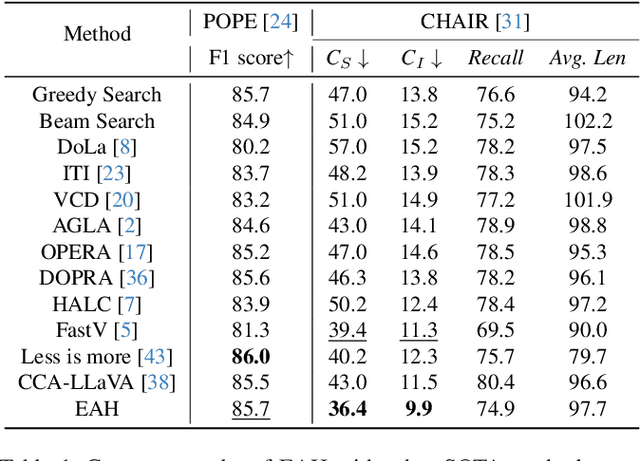
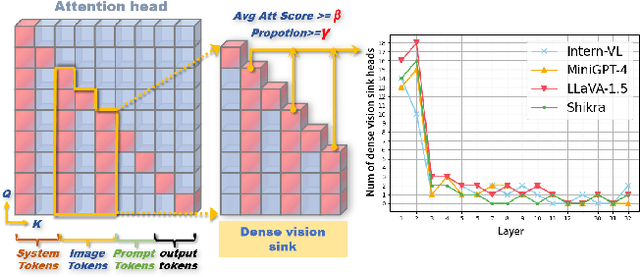
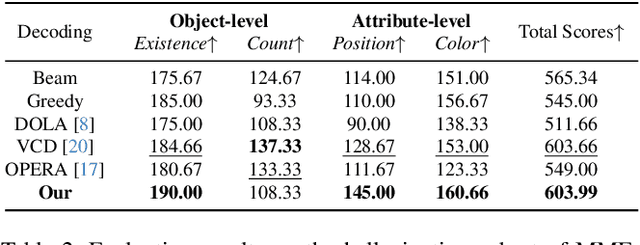
The hallucination problem in multimodal large language models (MLLMs) remains a common issue. Although image tokens occupy a majority of the input sequence of MLLMs, there is limited research to explore the relationship between image tokens and hallucinations. In this paper, we analyze the distribution of attention scores for image tokens across each layer and head of the model, revealing an intriguing and common phenomenon: most hallucinations are closely linked to the pattern of attention sinks in the self-attention matrix of image tokens, where shallow layers exhibit dense attention sinks and deeper layers show sparse attention sinks. We further analyze the attention heads of different layers and find that heads with high-density attention sink in the image part play a positive role in alleviating hallucinations. In this paper, we propose a training-free method named \textcolor{red}{\textbf{E}}nhancing \textcolor{red}{\textbf{A}}ttention \textcolor{red}{\textbf{H}}eads (EAH), an approach designed to enhance the convergence of image tokens attention sinks in the shallow layers. EAH identifies the attention head that shows the vision sink in a shallow layer and extracts its attention matrix. This attention map is then broadcast to other heads in the layer, thereby strengthening the layer to pay more attention to the image itself. With extensive experiments, EAH shows significant hallucination-mitigating performance on different MLLMs and metrics, proving its effectiveness and generality.
Instance-adaptive Zero-shot Chain-of-Thought Prompting
Sep 30, 2024



Zero-shot Chain-of-Thought (CoT) prompting emerges as a simple and effective strategy for enhancing the performance of large language models (LLMs) in real-world reasoning tasks. Nonetheless, the efficacy of a singular, task-level prompt uniformly applied across the whole of instances is inherently limited since one prompt cannot be a good partner for all, a more appropriate approach should consider the interaction between the prompt and each instance meticulously. This work introduces an instance-adaptive prompting algorithm as an alternative zero-shot CoT reasoning scheme by adaptively differentiating good and bad prompts. Concretely, we first employ analysis on LLMs through the lens of information flow to detect the mechanism under zero-shot CoT reasoning, in which we discover that information flows from question to prompt and question to rationale jointly influence the reasoning results most. We notice that a better zero-shot CoT reasoning needs the prompt to obtain semantic information from the question then the rationale aggregates sufficient information from the question directly and via the prompt indirectly. On the contrary, lacking any of those would probably lead to a bad one. Stem from that, we further propose an instance-adaptive prompting strategy (IAP) for zero-shot CoT reasoning. Experiments conducted with LLaMA-2, LLaMA-3, and Qwen on math, logic, and commonsense reasoning tasks (e.g., GSM8K, MMLU, Causal Judgement) obtain consistent improvement, demonstrating that the instance-adaptive zero-shot CoT prompting performs better than other task-level methods with some curated prompts or sophisticated procedures, showing the significance of our findings in the zero-shot CoT reasoning mechanism.
From Redundancy to Relevance: Enhancing Explainability in Multimodal Large Language Models
Jun 04, 2024



Recently, multimodal large language models have exploded with an endless variety, most of the popular Large Vision Language Models (LVLMs) depend on sequential visual representation, where images are converted into hundreds or thousands of tokens before being input into the Large Language Model (LLM) along with language prompts. The black-box design hinders the interpretability of visual-language models, especially regarding more complex reasoning tasks. To explore the interaction process between image and text in complex reasoning tasks, we introduce the information flow method to visualize the interaction mechanism. By analyzing the dynamic flow of the information flow, we find that the information flow appears to converge in the shallow layer. Further investigation revealed a redundancy of the image token in the shallow layer. Consequently, a truncation strategy was introduced to aggregate image tokens within these shallow layers. This approach has been validated through experiments across multiple models, yielding consistent improvements.