 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairGC: Fairness-aware Graph Condensation
Mar 30, 2026Graph condensation (GC) has become a vital strategy for scaling Graph Neural Networks by compressing massive datasets into small, synthetic node sets. While current GC methods effectively maintain predictive accuracy, they are primarily designed for utility and often ignore fairness constraints. Because these techniques are bias-blind, they frequently capture and even amplify demographic disparities found in the original data. This leads to synthetic proxies that are unsuitable for sensitive applications like credit scoring or social recommendations. To solve this problem, we introduce FairGC, a unified framework that embeds fairness directly into the graph distillation process. Our approach consists of three key components. First, a Distribution-Preserving Condensation module synchronizes the joint distributions of labels and sensitive attributes to stop bias from spreading. Second, a Spectral Encoding module uses Laplacian eigen-decomposition to preserve essential global structural patterns. Finally, a Fairness-Enhanced Neural Architecture employs multi-domain fusion and a label-smoothing curriculum to produce equitable predictions. Rigorous evaluations on four real-world datasets, show that FairGC provides a superior balance between accuracy and fairness. Our results confirm that FairGC significantly reduces disparity in Statistical Parity and Equal Opportunity compared to existing state-of-the-art condensation models. The codes are available at https://github.com/LuoRenqiang/FairGC.
Multimodal Emotion Regression with Multi-Objective Optimization and VAD-Aware Audio Modeling for the 10th ABAW EMI Track
Mar 14, 2026We participated in the 10th ABAW Challenge, focusing on the Emotional Mimicry Intensity (EMI) Estimation track on the Hume-Vidmimic2 dataset. This task aims to predict six continuous emotion dimensions: Admiration, Amusement, Determination, Empathic Pain, Excitement, and Joy. Through systematic multimodal exploration of pretrained high-level features, we found that, under our pretrained feature setting, direct feature concatenation outperformed the more complex fusion strategies we tested. This empirical finding motivated us to design a systematic approach built upon three core principles: (i) preserving modality-specific attributes through feature-level concatenation; (ii) improving training stability and metric alignment via multi-objective optimization; and (iii) enriching acoustic representations with a VAD-inspired latent prior. Our final framework integrates concatenation-based multimodal fusion, a shared six-dimensional regression head, multi-objective optimization with MSE, Pearson-correlation, and auxiliary branch supervision, EMA for parameter stabilization, and a VAD-inspired latent prior for the acoustic branch. On the official validation set, the proposed scheme achieved our best mean Pearson Correlation Coefficient of 0.478567.
Stealthy Dual-Trigger Backdoors: Attacking Prompt Tuning in LM-Empowered Graph Foundation Models
Oct 16, 2025The emergence of graph foundation models (GFMs), particularly those incorporating language models (LMs), has revolutionized graph learning and demonstrated remarkable performance on text-attributed graphs (TAGs). However, compared to traditional GNNs, these LM-empowered GFMs introduce unique security vulnerabilities during the unsecured prompt tuning phase that remain understudied in current research. Through empirical investigation, we reveal a significant performance degradation in traditional graph backdoor attacks when operating in attribute-inaccessible constrained TAG systems without explicit trigger node attribute optimization. To address this, we propose a novel dual-trigger backdoor attack framework that operates at both text-level and struct-level, enabling effective attacks without explicit optimization of trigger node text attributes through the strategic utilization of a pre-established text pool. Extensive experimental evaluations demonstrate that our attack maintains superior clean accuracy while achieving outstanding attack success rates, including scenarios with highly concealed single-trigger nodes. Our work highlights critical backdoor risks in web-deployed LM-empowered GFMs and contributes to the development of more robust supervision mechanisms for open-source platforms in the era of foundation models.
CrashFixer: A crash resolution agent for the Linux kernel
Apr 29, 2025

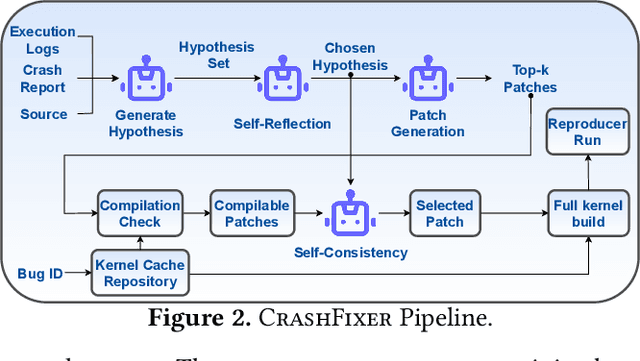
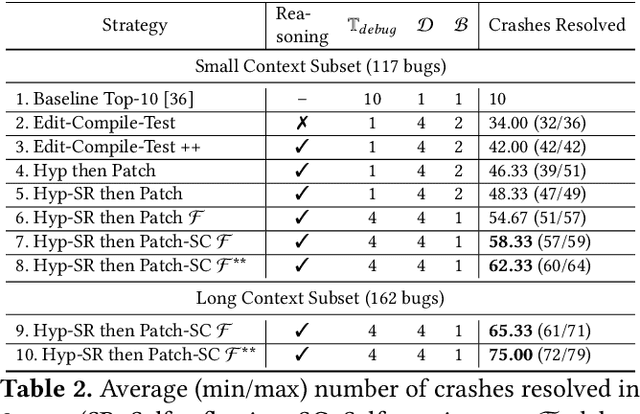
Code large language models (LLMs) have shown impressive capabilities on a multitude of software engineering tasks. In particular, they have demonstrated remarkable utility in the task of code repair. However, common benchmarks used to evaluate the performance of code LLMs are often limited to small-scale settings. In this work, we build upon kGym, which shares a benchmark for system-level Linux kernel bugs and a platform to run experiments on the Linux kernel. This paper introduces CrashFixer, the first LLM-based software repair agent that is applicable to Linux kernel bugs. Inspired by the typical workflow of a kernel developer, we identify the key capabilities an expert developer leverages to resolve a kernel crash. Using this as our guide, we revisit the kGym platform and identify key system improvements needed to practically run LLM-based agents at the scale of the Linux kernel (50K files and 20M lines of code). We implement these changes by extending kGym to create an improved platform - called kGymSuite, which will be open-sourced. Finally, the paper presents an evaluation of various repair strategies for such complex kernel bugs and showcases the value of explicitly generating a hypothesis before attempting to fix bugs in complex systems such as the Linux kernel. We also evaluated CrashFixer's capabilities on still open bugs, and found at least two patch suggestions considered plausible to resolve the reported bug.
Improving Complex Reasoning with Dynamic Prompt Corruption: A soft prompt Optimization Approach
Mar 17, 2025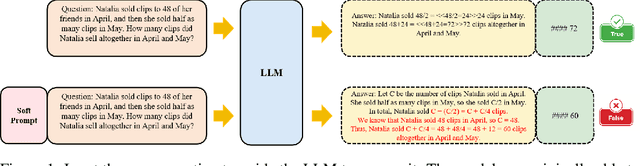

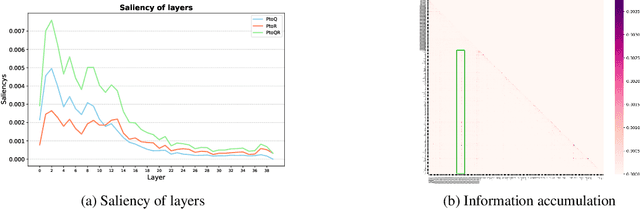

Prompt-tuning (PT) for large language models (LLMs) can facilitate the performance on various conventional NLP tasks with significantly fewer trainable parameters. However, our investigation reveals that PT provides limited improvement and may even degrade the primitive performance of LLMs on complex reasoning tasks. Such a phenomenon suggests that soft prompts can positively impact certain instances while negatively affecting others, particularly during the later phases of reasoning. To address these challenges, We first identify an information accumulation within the soft prompts. Through detailed analysis, we demonstrate that this phenomenon is often accompanied by erroneous information flow patterns in the deeper layers of the model, which ultimately lead to incorrect reasoning outcomes. we propose a novel method called \textbf{D}ynamic \textbf{P}rompt \textbf{C}orruption (DPC) to take better advantage of soft prompts in complex reasoning tasks, which dynamically adjusts the influence of soft prompts based on their impact on the reasoning process. Specifically, DPC consists of two stages: Dynamic Trigger and Dynamic Corruption. First, Dynamic Trigger measures the impact of soft prompts, identifying whether beneficial or detrimental. Then, Dynamic Corruption mitigates the negative effects of soft prompts by selectively masking key tokens that interfere with the reasoning process. We validate the proposed approach through extensive experiments on various LLMs and reasoning tasks, including GSM8K, MATH, and AQuA. Experimental results demonstrate that DPC can consistently enhance the performance of PT, achieving 4\%-8\% accuracy gains compared to vanilla prompt tuning, highlighting the effectiveness of our approach and its potential to enhance complex reasoning in LLMs.
NeRF-Det++: Incorporating Semantic Cues and Perspective-aware Depth Supervision for Indoor Multi-View 3D Detection
Feb 22, 2024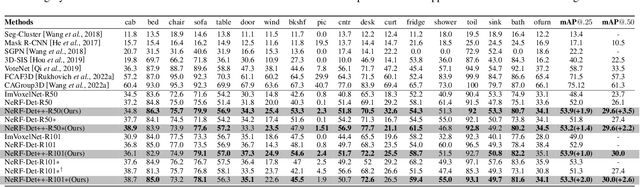
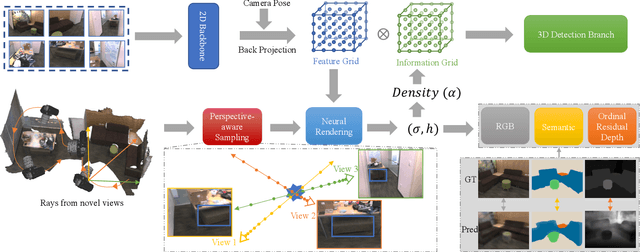
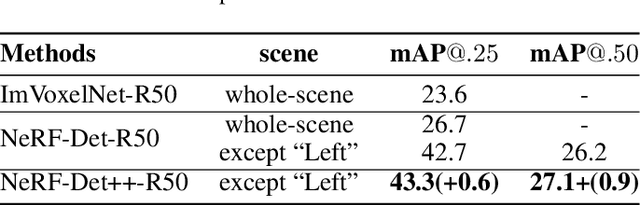

NeRF-Det has achieved impressive performance in indoor multi-view 3D detection by innovatively utilizing NeRF to enhance representation learning. Despite its notable performance, we uncover three decisive shortcomings in its current design, including semantic ambiguity, inappropriate sampling, and insufficient utilization of depth supervision. To combat the aforementioned problems, we present three corresponding solutions: 1) Semantic Enhancement. We project the freely available 3D segmentation annotations onto the 2D plane and leverage the corresponding 2D semantic maps as the supervision signal, significantly enhancing the semantic awareness of multi-view detectors. 2) Perspective-aware Sampling. Instead of employing the uniform sampling strategy, we put forward the perspective-aware sampling policy that samples densely near the camera while sparsely in the distance, more effectively collecting the valuable geometric clues. 3)Ordinal Residual Depth Supervision. As opposed to directly regressing the depth values that are difficult to optimize, we divide the depth range of each scene into a fixed number of ordinal bins and reformulate the depth prediction as the combination of the classification of depth bins as well as the regression of the residual depth values, thereby benefiting the depth learning process. The resulting algorithm, NeRF-Det++, has exhibited appealing performance in the ScanNetV2 and ARKITScenes datasets. Notably, in ScanNetV2, NeRF-Det++ outperforms the competitive NeRF-Det by +1.9% in mAP@0.25 and +3.5% in mAP@0.50$. The code will be publicly at https://github.com/mrsempress/NeRF-Detplusplus.
Towards Head Computed Tomography Image Reconstruction Standardization with Deep Learning Assisted Automatic Detection
Jul 31, 2023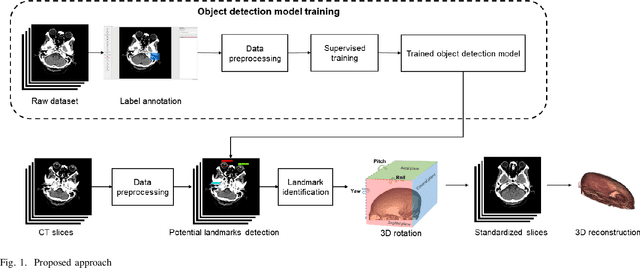
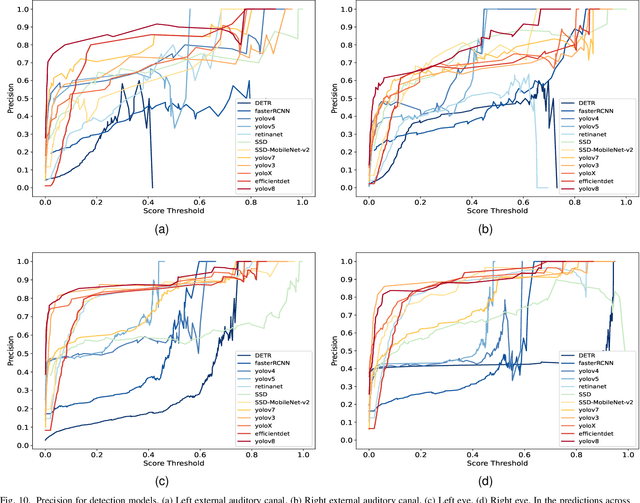
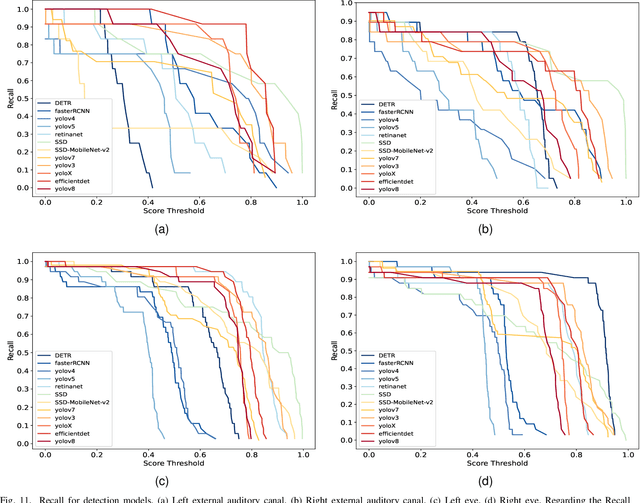
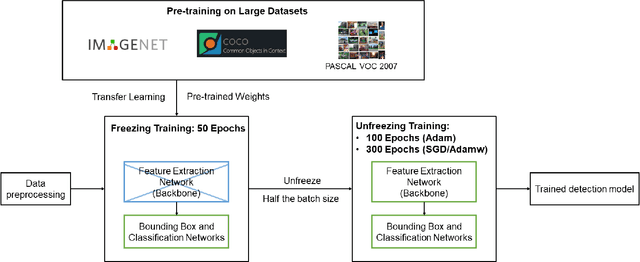
Three-dimensional (3D) reconstruction of head Computed Tomography (CT) images elucidates the intricate spatial relationships of tissue structures, thereby assisting in accurate diagnosis. Nonetheless, securing an optimal head CT scan without deviation is challenging in clinical settings, owing to poor positioning by technicians, patient's physical constraints, or CT scanner tilt angle restrictions. Manual formatting and reconstruction not only introduce subjectivity but also strain time and labor resources. To address these issues, we propose an efficient automatic head CT images 3D reconstruction method, improving accuracy and repeatability, as well as diminishing manual intervention. Our approach employs a deep learning-based object detection algorithm, identifying and evaluating orbitomeatal line landmarks to automatically reformat the images prior to reconstruction. Given the dearth of existing evaluations of object detection algorithms in the context of head CT images, we compared ten methods from both theoretical and experimental perspectives. By exploring their precision, efficiency, and robustness, we singled out the lightweight YOLOv8 as the aptest algorithm for our task, with an mAP of 92.91% and impressive robustness against class imbalance. Our qualitative evaluation of standardized reconstruction results demonstrates the clinical practicability and validity of our method.
Shuffled Differentially Private Federated Learning for Time Series Data Analytics
Jul 30, 2023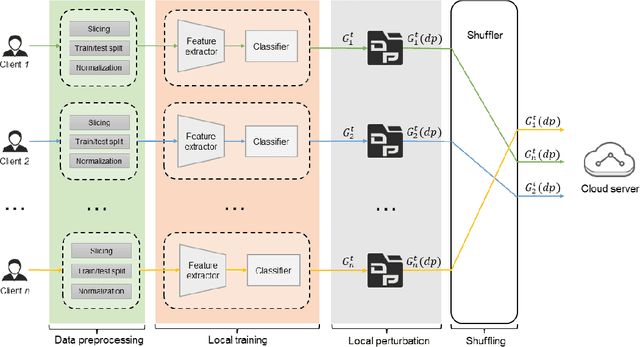
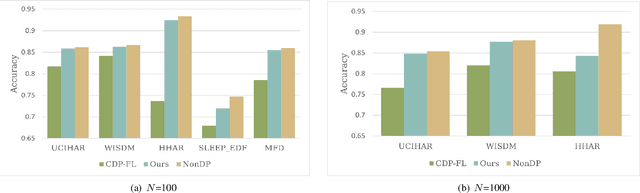
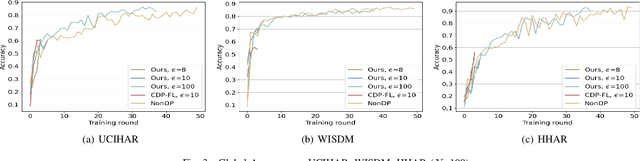
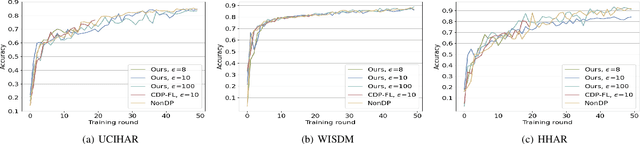
Trustworthy federated learning aims to achieve optimal performance while ensuring clients' privacy. Existing privacy-preserving federated learning approaches are mostly tailored for image data, lacking applications for time series data, which have many important applications, like machine health monitoring, human activity recognition, etc. Furthermore, protective noising on a time series data analytics model can significantly interfere with temporal-dependent learning, leading to a greater decline in accuracy. To address these issues, we develop a privacy-preserving federated learning algorithm for time series data. Specifically, we employ local differential privacy to extend the privacy protection trust boundary to the clients. We also incorporate shuffle techniques to achieve a privacy amplification, mitigating the accuracy decline caused by leveraging local differential privacy. Extensive experiments were conducted on five time series datasets. The evaluation results reveal that our algorithm experienced minimal accuracy loss compared to non-private federated learning in both small and large client scenarios. Under the same level of privacy protection, our algorithm demonstrated improved accuracy compared to the centralized differentially private federated learning in both scenarios.
Neural Collapse Inspired Federated Learning with Non-iid Data
Mar 31, 2023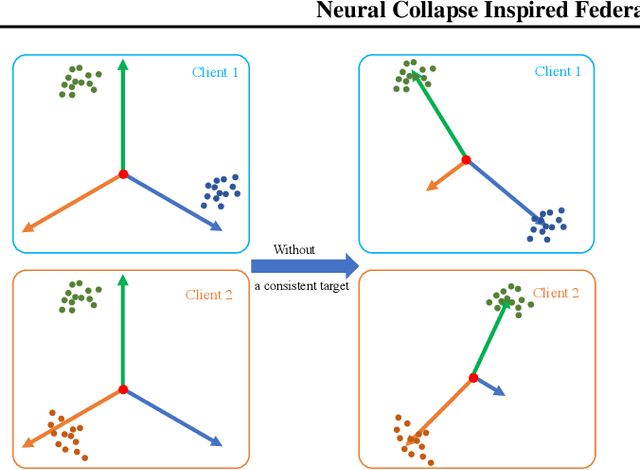
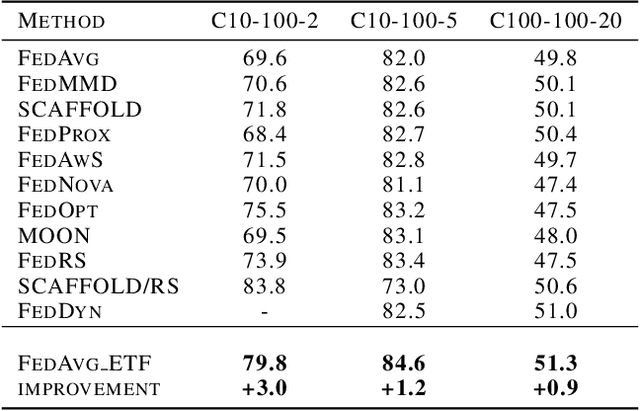
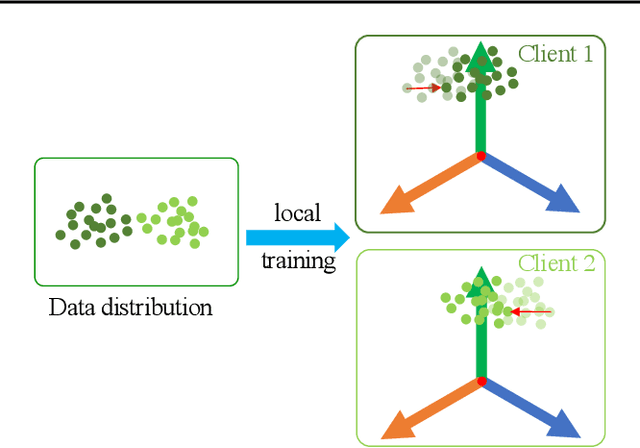
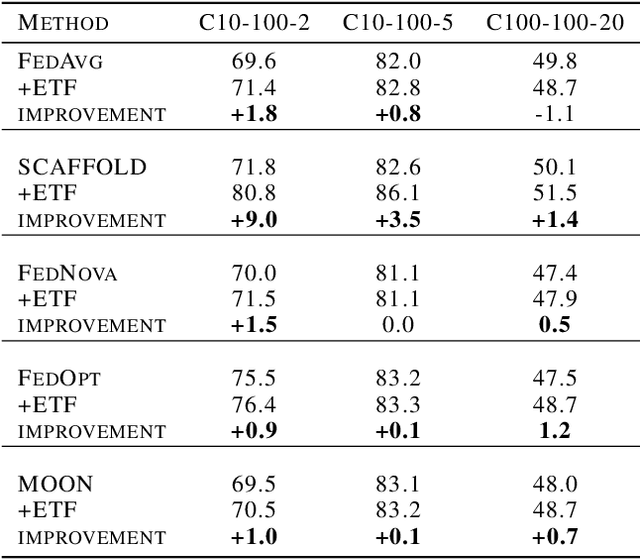
One of the challenges in federated learning is the non-independent and identically distributed (non-iid) characteristics between heterogeneous devices, which cause significant differences in local updates and affect the performance of the central server. Although many studies have been proposed to address this challenge, they only focus on local training and aggregation processes to smooth the changes and fail to achieve high performance with deep learning models. Inspired by the phenomenon of neural collapse, we force each client to be optimized toward an optimal global structure for classification. Specifically, we initialize it as a random simplex Equiangular Tight Frame (ETF) and fix it as the unit optimization target of all clients during the local updating. After guaranteeing all clients are learning to converge to the global optimum, we propose to add a global memory vector for each category to remedy the parameter fluctuation caused by the bias of the intra-class condition distribution among clients. Our experimental results show that our method can improve the performance with faster convergence speed on different-size datasets.
Self-supervised and Weakly Supervised Contrastive Learning for Frame-wise Action Representations
Dec 23, 2022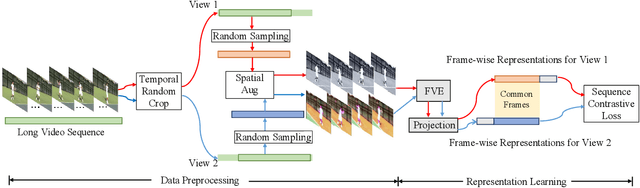
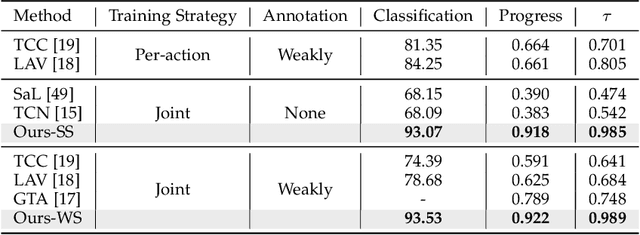
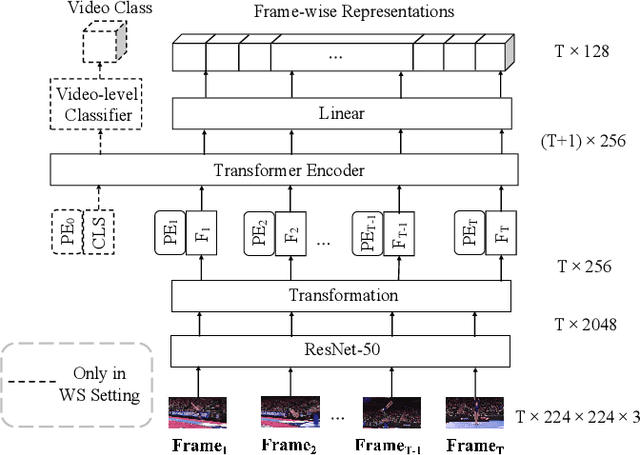
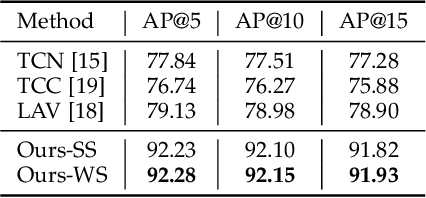
Previous work on action representation learning focused on global representations for short video clips. In contrast, many practical applications, such as video alignment, strongly demand learning the intensive representation of long videos. In this paper, we introduce a new framework of contrastive action representation learning (CARL) to learn frame-wise action representation in a self-supervised or weakly-supervised manner, especially for long videos. Specifically, we introduce a simple but effective video encoder that considers both spatial and temporal context by combining convolution and transformer. Inspired by the recent massive progress in self-supervised learning, we propose a new sequence contrast loss (SCL) applied to two related views obtained by expanding a series of spatio-temporal data in two versions. One is the self-supervised version that optimizes embedding space by minimizing KL-divergence between sequence similarity of two augmented views and prior Gaussian distribution of timestamp distance. The other is the weakly-supervised version that builds more sample pairs among videos using video-level labels by dynamic time wrapping (DTW). Experiments on FineGym, PennAction, and Pouring datasets show that our method outperforms previous state-of-the-art by a large margin for downstream fine-grained action classification and even faster inference. Surprisingly, although without training on paired videos like in previous works, our self-supervised version also shows outstanding performance in video alignment and fine-grained frame retrieval tasks.