 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
S$^2$-FPN: Scale-ware Strip Attention Guided Feature Pyramid Network for Real-time Semantic Segmentation
Jun 16, 2022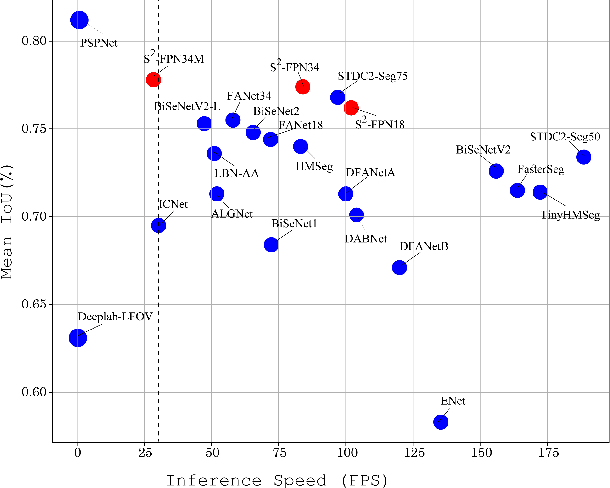
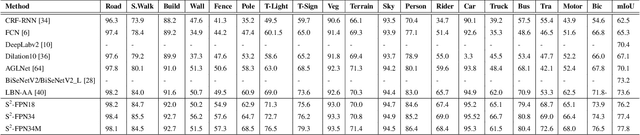
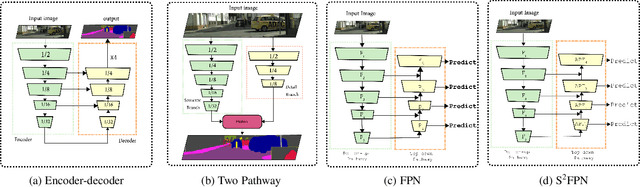
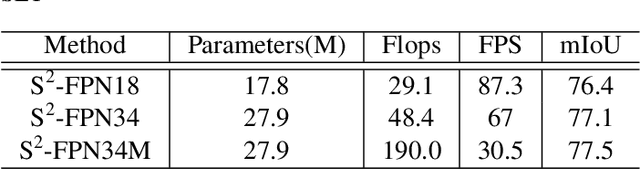
Modern high-performance semantic segmentation methods employ a heavy backbone and dilated convolution to extract the relevant feature. Although extracting features with both contextual and semantic information is critical for the segmentation tasks, it brings a memory footprint and high computation cost for real-time applications. This paper presents a new model to achieve a trade-off between accuracy/speed for real-time road scene semantic segmentation. Specifically, we proposed a lightweight model named Scale-aware Strip Attention Guided Feature Pyramid Network (S$^2$-FPN). Our network consists of three main modules: Attention Pyramid Fusion (APF) module, Scale-aware Strip Attention Module (SSAM), and Global Feature Upsample (GFU) module. APF adopts an attention mechanisms to learn discriminative multi-scale features and help close the semantic gap between different levels. APF uses the scale-aware attention to encode global context with vertical stripping operation and models the long-range dependencies, which helps relate pixels with similar semantic label. In addition, APF employs channel-wise reweighting block (CRB) to emphasize the channel features. Finally, the decoder of S$^2$-FPN then adopts GFU, which is used to fuse features from APF and the encoder. Extensive experiments have been conducted on two challenging semantic segmentation benchmarks, which demonstrate that our approach achieves better accuracy/speed trade-off with different model settings. The proposed models have achieved a results of 76.2\%mIoU/87.3FPS, 77.4\%mIoU/67FPS, and 77.8\%mIoU/30.5FPS on Cityscapes dataset, and 69.6\%mIoU,71.0\% mIoU, and 74.2\% mIoU on Camvid dataset. The code for this work will be made available at \url{https://github.com/mohamedac29/S2-FPN
SPFNet:Subspace Pyramid Fusion Network for Semantic Segmentation
Apr 04, 2022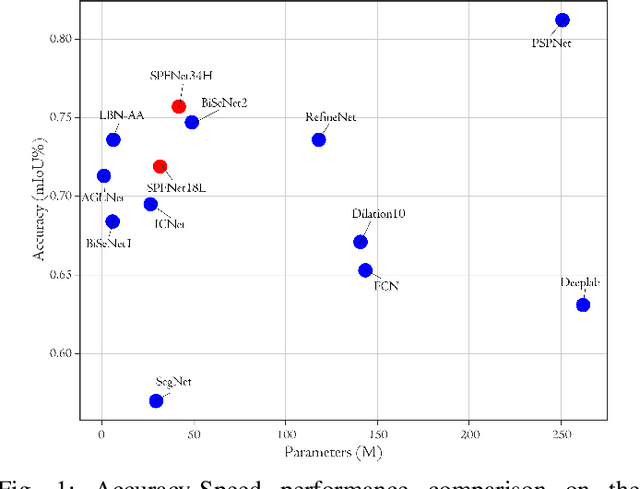

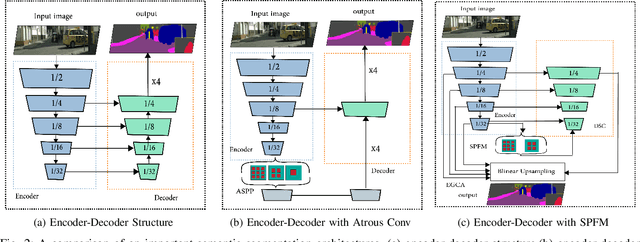
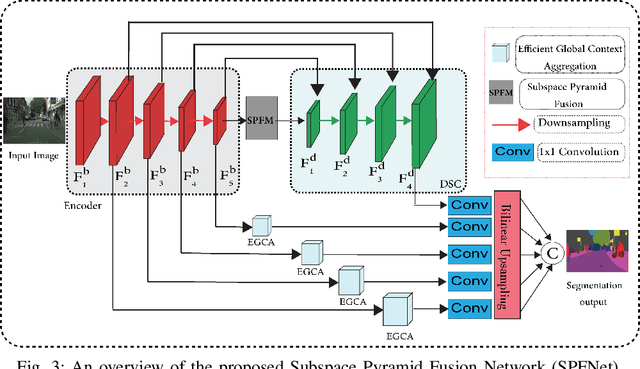
The encoder-decoder structure has significantly improved performance in many vision tasks by fusing low-level and high-level feature maps. However, this approach can hardly extract sufficient context information for pixel-wise segmentation. In addition, extracting similar low-level features at multiple scales could lead to redundant information. To tackle these issues, we propose Subspace Pyramid Fusion Network (SPFNet). Specifically, we combine pyramidal module and context aggregation module to exploit the impact of multi-scale/global context information. At first, we construct a Subspace Pyramid Fusion Module (SPFM) based on Reduced Pyramid Pooling (RPP). Then, we propose the Efficient Global Context Aggregation (EGCA) module to capture discriminative features by fusing multi-level global context features. Finally, we add decoder-based subpixel convolution to retrieve the high-resolution feature maps, which can help select category localization details. SPFM learns separate RPP for each feature subspace to capture multi-scale feature representations, which is more useful for semantic segmentation. EGCA adopts shuffle attention mechanism to enhance communication across different sub-features. Experimental results on two well-known semantic segmentation datasets, including Camvid and Cityscapes, show that our proposed method is competitive with other state-of-the-art methods.
Geometric Multi-Model Fitting by Deep Reinforcement Learning
Sep 22, 2018
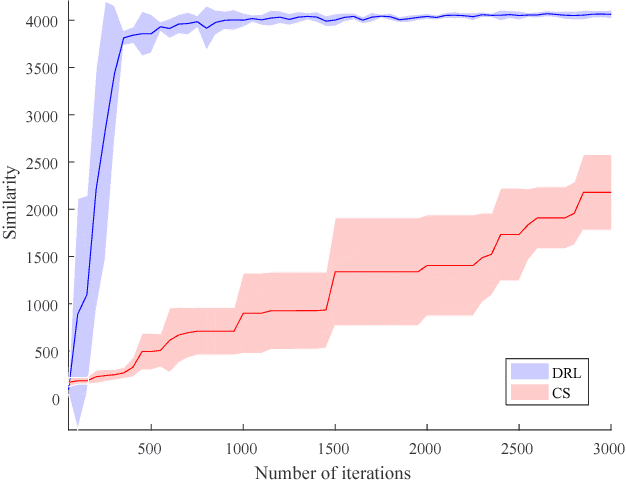
This paper deals with the geometric multi-model fitting from noisy, unstructured point set data (e.g., laser scanned point clouds). We formulate multi-model fitting problem as a sequential decision making process. We then use a deep reinforcement learning algorithm to learn the optimal decisions towards the best fitting result. In this paper, we have compared our method against the state-of-the-art on simulated data. The results demonstrated that our approach significantly reduced the number of fitting iterations.
Traffic Sign Timely Visual Recognizability Evaluation Based on 3D Measurable Point Clouds
Oct 10, 2017

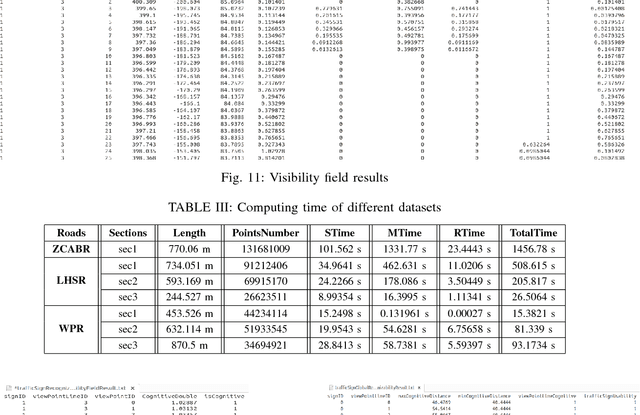

The timely provision of traffic sign information to drivers is essential for the drivers to respond, to ensure safe driving, and to avoid traffic accidents in a timely manner. We proposed a timely visual recognizability quantitative evaluation method for traffic signs in large-scale transportation environments. To achieve this goal, we first address the concept of a visibility field to reflect the visible distribution of three-dimensional (3D) space and construct a traffic sign Visibility Evaluation Model (VEM) to measure the traffic sign visibility for a given viewpoint. Then, based on the VEM, we proposed the concept of the Visual Recognizability Field (VRF) to reflect the visual recognizability distribution in 3D space and established a Visual Recognizability Evaluation Model (VREM) to measure a traffic sign visual recognizability for a given viewpoint. Next, we proposed a Traffic Sign Timely Visual Recognizability Evaluation Model (TSTVREM) by combining VREM, the actual maximum continuous visual recognizable distance, and traffic big data to measure a traffic sign visual recognizability in different lanes. Finally, we presented an automatic algorithm to implement the TSTVREM model through traffic sign and road marking detection and classification, traffic sign environment point cloud segmentation, viewpoints calculation, and TSTVREM model realization. The performance of our method for traffic sign timely visual recognizability evaluation is tested on three road point clouds acquired by a mobile laser scanning system (RIEGL VMX-450) according to Road Traffic Signs and Markings (GB 5768-1999 in China), showing that our method is feasible and efficient.
An Effective Unconstrained Correlation Filter and Its Kernelization for Face Recognition
Mar 25, 2016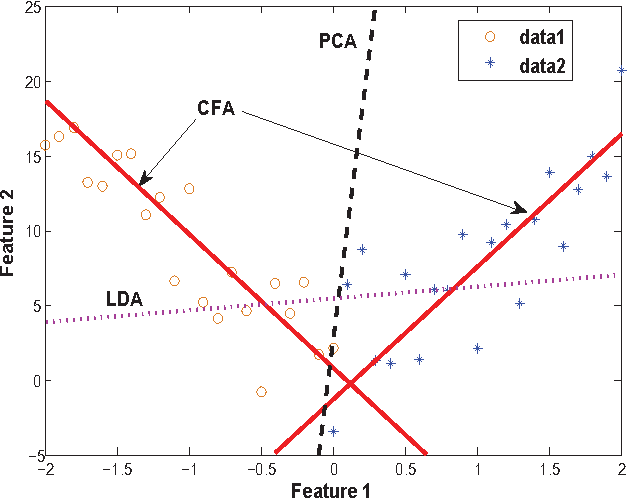
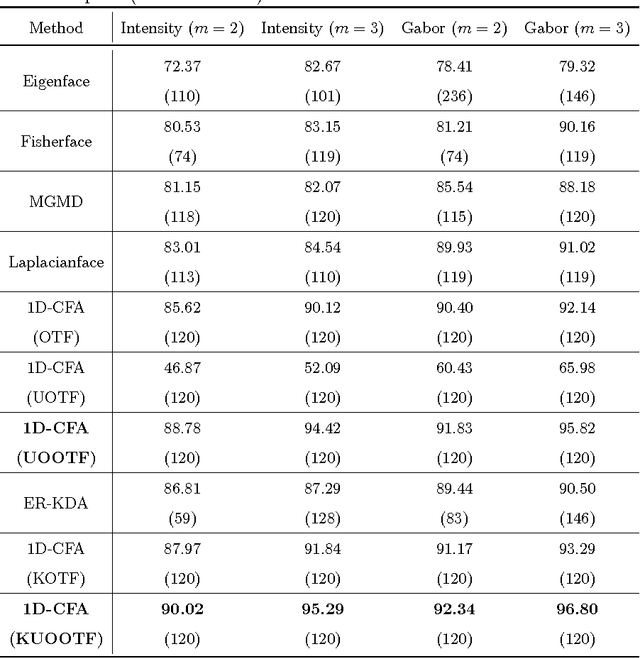
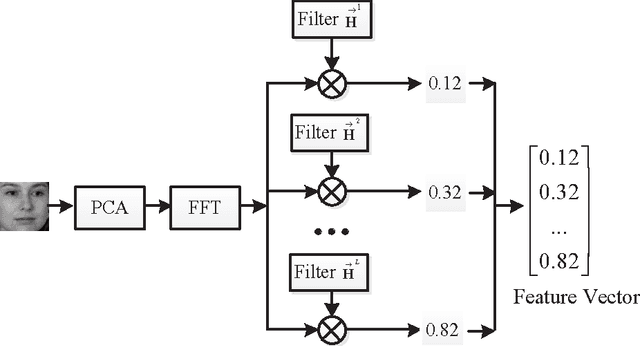
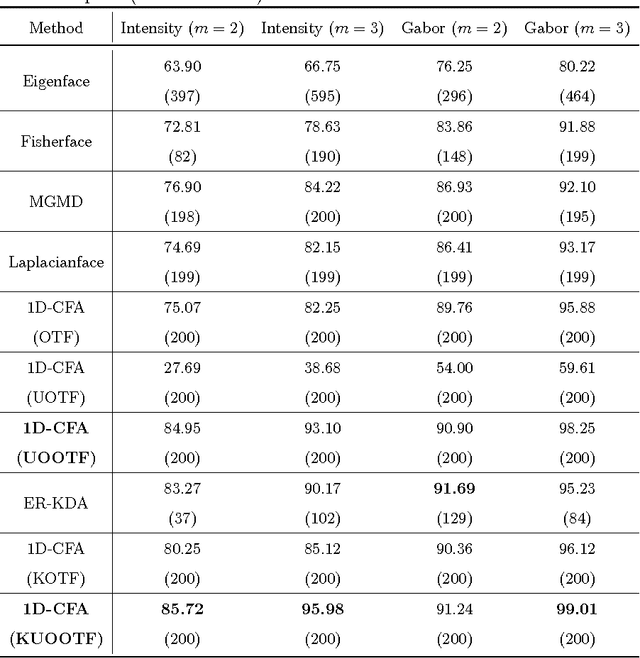
In this paper, an effective unconstrained correlation filter called Uncon- strained Optimal Origin Tradeoff Filter (UOOTF) is presented and applied to robust face recognition. Compared with the conventional correlation filters in Class-dependence Feature Analysis (CFA), UOOTF improves the overall performance for unseen patterns by removing the hard constraints on the origin correlation outputs during the filter design. To handle non-linearly separable distributions between different classes, we further develop a non- linear extension of UOOTF based on the kernel technique. The kernel ex- tension of UOOTF allows for higher flexibility of the decision boundary due to a wider range of non-linearity properties. Experimental results demon- strate the effectiveness of the proposed unconstrained correlation filter and its kernelization in the task of face recognition.