 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMCC-ReID: Cross-Modality Clothing-Change Person Re-Identification
Apr 03, 2026Person Re-Identification (ReID) faces severe challenges from modality discrepancy and clothing variation in long-term surveillance scenario. While existing studies have made significant progress in either Visible-Infrared ReID (VI-ReID) or Clothing-Change ReID (CC-ReID), real-world surveillance system often face both challenges simultaneously. To address this overlooked yet realistic problem, we define a new task, termed Cross-Modality Clothing-Change Re-Identification (CMCC-ReID), which targets pedestrian matching across variations in both modality and clothing. To advance research in this direction, we construct a new benchmark SYSU-CMCC, where each identity is captured in both visible and infrared domains with distinct outfits, reflecting the dual heterogeneity of long-term surveillance. To tackle CMCC-ReID, we propose a Progressive Identity Alignment Network (PIA) that progressively mitigates the issues of clothing variation and modality discrepancy. Specifically, a Dual-Branch Disentangling Learning (DBDL) module separates identity-related cues from clothing-related factors to achieve clothing-agnostic representation, and a Bi-Directional Prototype Learning (BPL) module performs intra-modality and inter-modality contrast in the embedding space to bridge the modality gap while further suppressing clothing interference. Extensive experiments on the SYSU-CMCC dataset demonstrate that PIA establishes a strong baseline for this new task and significantly outperforms existing methods.
WarpGAN: Warping-Guided 3D GAN Inversion with Style-Based Novel View Inpainting
Nov 11, 20253D GAN inversion projects a single image into the latent space of a pre-trained 3D GAN to achieve single-shot novel view synthesis, which requires visible regions with high fidelity and occluded regions with realism and multi-view consistency. However, existing methods focus on the reconstruction of visible regions, while the generation of occluded regions relies only on the generative prior of 3D GAN. As a result, the generated occluded regions often exhibit poor quality due to the information loss caused by the low bit-rate latent code. To address this, we introduce the warping-and-inpainting strategy to incorporate image inpainting into 3D GAN inversion and propose a novel 3D GAN inversion method, WarpGAN. Specifically, we first employ a 3D GAN inversion encoder to project the single-view image into a latent code that serves as the input to 3D GAN. Then, we perform warping to a novel view using the depth map generated by 3D GAN. Finally, we develop a novel SVINet, which leverages the symmetry prior and multi-view image correspondence w.r.t. the same latent code to perform inpainting of occluded regions in the warped image. Quantitative and qualitative experiments demonstrate that our method consistently outperforms several state-of-the-art methods.
FATE: A Prompt-Tuning-Based Semi-Supervised Learning Framework for Extremely Limited Labeled Data
Apr 14, 2025Semi-supervised learning (SSL) has achieved significant progress by leveraging both labeled data and unlabeled data. Existing SSL methods overlook a common real-world scenario when labeled data is extremely scarce, potentially as limited as a single labeled sample in the dataset. General SSL approaches struggle to train effectively from scratch under such constraints, while methods utilizing pre-trained models often fail to find an optimal balance between leveraging limited labeled data and abundant unlabeled data. To address this challenge, we propose Firstly Adapt, Then catEgorize (FATE), a novel SSL framework tailored for scenarios with extremely limited labeled data. At its core, the two-stage prompt tuning paradigm FATE exploits unlabeled data to compensate for scarce supervision signals, then transfers to downstream tasks. Concretely, FATE first adapts a pre-trained model to the feature distribution of downstream data using volumes of unlabeled samples in an unsupervised manner. It then applies an SSL method specifically designed for pre-trained models to complete the final classification task. FATE is designed to be compatible with both vision and vision-language pre-trained models. Extensive experiments demonstrate that FATE effectively mitigates challenges arising from the scarcity of labeled samples in SSL, achieving an average performance improvement of 33.74% across seven benchmarks compared to state-of-the-art SSL methods. Code is available at https://anonymous.4open.science/r/Semi-supervised-learning-BA72.
Mind the Gap: Confidence Discrepancy Can Guide Federated Semi-Supervised Learning Across Pseudo-Mismatch
Mar 17, 2025Federated Semi-Supervised Learning (FSSL) aims to leverage unlabeled data across clients with limited labeled data to train a global model with strong generalization ability. Most FSSL methods rely on consistency regularization with pseudo-labels, converting predictions from local or global models into hard pseudo-labels as supervisory signals. However, we discover that the quality of pseudo-label is largely deteriorated by data heterogeneity, an intrinsic facet of federated learning. In this paper, we study the problem of FSSL in-depth and show that (1) heterogeneity exacerbates pseudo-label mismatches, further degrading model performance and convergence, and (2) local and global models' predictive tendencies diverge as heterogeneity increases. Motivated by these findings, we propose a simple and effective method called Semi-supervised Aggregation for Globally-Enhanced Ensemble (SAGE), that can flexibly correct pseudo-labels based on confidence discrepancies. This strategy effectively mitigates performance degradation caused by incorrect pseudo-labels and enhances consensus between local and global models. Experimental results demonstrate that SAGE outperforms existing FSSL methods in both performance and convergence. Our code is available at https://github.com/Jay-Codeman/SAGE
Classifying Long-tailed and Label-noise Data via Disentangling and Unlearning
Mar 14, 2025


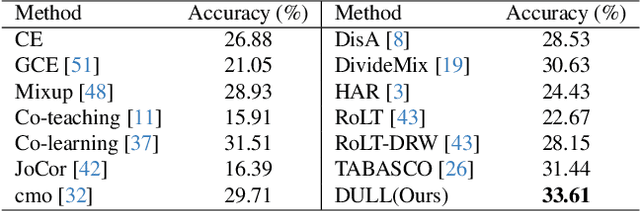
In real-world datasets, the challenges of long-tailed distributions and noisy labels often coexist, posing obstacles to the model training and performance. Existing studies on long-tailed noisy label learning (LTNLL) typically assume that the generation of noisy labels is independent of the long-tailed distribution, which may not be true from a practical perspective. In real-world situaiton, we observe that the tail class samples are more likely to be mislabeled as head, exacerbating the original degree of imbalance. We call this phenomenon as ``tail-to-head (T2H)'' noise. T2H noise severely degrades model performance by polluting the head classes and forcing the model to learn the tail samples as head. To address this challenge, we investigate the dynamic misleading process of the nosiy labels and propose a novel method called Disentangling and Unlearning for Long-tailed and Label-noisy data (DULL). It first employs the Inner-Feature Disentangling (IFD) to disentangle feature internally. Based on this, the Inner-Feature Partial Unlearning (IFPU) is then applied to weaken and unlearn incorrect feature regions correlated to wrong classes. This method prevents the model from being misled by noisy labels, enhancing the model's robustness against noise. To provide a controlled experimental environment, we further propose a new noise addition algorithm to simulate T2H noise. Extensive experiments on both simulated and real-world datasets demonstrate the effectiveness of our proposed method.
CAPT: Class-Aware Prompt Tuning for Federated Long-Tailed Learning with Vision-Language Model
Mar 10, 2025Effectively handling the co-occurrence of non-IID data and long-tailed distributions remains a critical challenge in federated learning. While fine-tuning vision-language models (VLMs) like CLIP has shown to be promising in addressing non-IID data challenges, this approach leads to severe degradation of tail classes in federated long-tailed scenarios. Under the composite effects of strong non-IID data distribution and long-tailed class imbalances, VLM fine-tuning may even fail to yield any improvement. To address this issue, we propose Class-Aware Prompt Learning for Federated Long-tailed Learning (CAPT), a novel framework that leverages a pre-trained VLM to effectively handle both data heterogeneity and long-tailed distributions. CAPT introduces a dual-prompt mechanism that synergizes general and class-aware prompts, enabling the framework to capture global trends while preserving class-specific knowledge. To better aggregate and share knowledge across clients, we introduce a heterogeneity-aware client clustering strategy that groups clients based on their data distributions, enabling efficient collaboration and knowledge sharing. Extensive experiments on various long-tailed datasets with different levels of data heterogeneity demonstrate that CAPT significantly improves tail class performance without compromising overall accuracy, outperforming state-of-the-art methods in federated long-tailed learning scenarios.
You Are Your Own Best Teacher: Achieving Centralized-level Performance in Federated Learning under Heterogeneous and Long-tailed Data
Mar 10, 2025Data heterogeneity, stemming from local non-IID data and global long-tailed distributions, is a major challenge in federated learning (FL), leading to significant performance gaps compared to centralized learning. Previous research found that poor representations and biased classifiers are the main problems and proposed neural-collapse-inspired synthetic simplex ETF to help representations be closer to neural collapse optima. However, we find that the neural-collapse-inspired methods are not strong enough to reach neural collapse and still have huge gaps to centralized training. In this paper, we rethink this issue from a self-bootstrap perspective and propose FedYoYo (You Are Your Own Best Teacher), introducing Augmented Self-bootstrap Distillation (ASD) to improve representation learning by distilling knowledge between weakly and strongly augmented local samples, without needing extra datasets or models. We further introduce Distribution-aware Logit Adjustment (DLA) to balance the self-bootstrap process and correct biased feature representations. FedYoYo nearly eliminates the performance gap, achieving centralized-level performance even under mixed heterogeneity. It enhances local representation learning, reducing model drift and improving convergence, with feature prototypes closer to neural collapse optimality. Extensive experiments show FedYoYo achieves state-of-the-art results, even surpassing centralized logit adjustment methods by 5.4\% under global long-tailed settings.
Uncertainty-Aware Label Refinement on Hypergraphs for Personalized Federated Facial Expression Recognition
Jan 03, 2025



Most facial expression recognition (FER) models are trained on large-scale expression data with centralized learning. Unfortunately, collecting a large amount of centralized expression data is difficult in practice due to privacy concerns of facial images. In this paper, we investigate FER under the framework of personalized federated learning, which is a valuable and practical decentralized setting for real-world applications. To this end, we develop a novel uncertainty-Aware label refineMent on hYpergraphs (AMY) method. For local training, each local model consists of a backbone, an uncertainty estimation (UE) block, and an expression classification (EC) block. In the UE block, we leverage a hypergraph to model complex high-order relationships between expression samples and incorporate these relationships into uncertainty features. A personalized uncertainty estimator is then introduced to estimate reliable uncertainty weights of samples in the local client. In the EC block, we perform label propagation on the hypergraph, obtaining high-quality refined labels for retraining an expression classifier. Based on the above, we effectively alleviate heterogeneous sample uncertainty across clients and learn a robust personalized FER model in each client. Experimental results on two challenging real-world facial expression databases show that our proposed method consistently outperforms several state-of-the-art methods. This indicates the superiority of hypergraph modeling for uncertainty estimation and label refinement on the personalized federated FER task. The source code will be released at https://github.com/mobei1006/AMY.
Augmentation Matters: A Mix-Paste Method for X-Ray Prohibited Item Detection under Noisy Annotations
Jan 03, 2025



Automatic X-ray prohibited item detection is vital for public safety. Existing deep learning-based methods all assume that the annotations of training X-ray images are correct. However, obtaining correct annotations is extremely hard if not impossible for large-scale X-ray images, where item overlapping is ubiquitous.As a result, X-ray images are easily contaminated with noisy annotations, leading to performance deterioration of existing methods.In this paper, we address the challenging problem of training a robust prohibited item detector under noisy annotations (including both category noise and bounding box noise) from a novel perspective of data augmentation, and propose an effective label-aware mixed patch paste augmentation method (Mix-Paste). Specifically, for each item patch, we mix several item patches with the same category label from different images and replace the original patch in the image with the mixed patch. In this way, the probability of containing the correct prohibited item within the generated image is increased. Meanwhile, the mixing process mimics item overlapping, enabling the model to learn the characteristics of X-ray images. Moreover, we design an item-based large-loss suppression (LLS) strategy to suppress the large losses corresponding to potentially positive predictions of additional items due to the mixing operation. We show the superiority of our method on X-ray datasets under noisy annotations. In addition, we evaluate our method on the noisy MS-COCO dataset to showcase its generalization ability. These results clearly indicate the great potential of data augmentation to handle noise annotations. The source code is released at https://github.com/wscds/Mix-Paste.
Video-to-Task Learning via Motion-Guided Attention for Few-Shot Action Recognition
Nov 18, 2024



In recent years, few-shot action recognition has achieved remarkable performance through spatio-temporal relation modeling. Although a wide range of spatial and temporal alignment modules have been proposed, they primarily address spatial or temporal misalignments at the video level, while the spatio-temporal relationships across different videos at the task level remain underexplored. Recent studies utilize class prototypes to learn task-specific features but overlook the spatio-temporal relationships across different videos at the task level, especially in the spatial dimension, where these relationships provide rich information. In this paper, we propose a novel Dual Motion-Guided Attention Learning method (called DMGAL) for few-shot action recognition, aiming to learn the spatio-temporal relationships from the video-specific to the task-specific level. To achieve this, we propose a carefully designed Motion-Guided Attention (MGA) method to identify and correlate motion-related region features from the video level to the task level. Specifically, the Self Motion-Guided Attention module (S-MGA) achieves spatio-temporal relation modeling at the video level by identifying and correlating motion-related region features between different frames within a video. The Cross Motion-Guided Attention module (C-MGA) identifies and correlates motion-related region features between frames of different videos within a specific task to achieve spatio-temporal relationships at the task level. This approach enables the model to construct class prototypes that fully incorporate spatio-temporal relationships from the video-specific level to the task-specific level. We validate the effectiveness of our DMGAL method by employing both fully fine-tuning and adapter-tuning paradigms. The models developed using these paradigms are termed DMGAL-FT and DMGAL-Adapter, respectively.