 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMViewRouter: Internalizing Geometric Equivariance via Multi-view Alternating Attention for Combinatorial Routing
May 31, 2026Combinatorial routing problems such as the Traveling Salesman Problem (TSP) and the Capacitated Vehicle Routing Problem (CVRP) are fundamental NP-hard problems with broad real-world applications. While recent deep reinforcement learning methods have shown promising performance, they typically handle geometric symmetries only through data augmentation, resulting in inconsistent decisions and limited generalization. To address this issue, we propose MViewRouter, a multi-view framework that internalizes geometric equivariance as a structural inductive bias to achieve invariant decision-making across routing problem variants. Our approach introduces a Multi-view Alternating Attention (MAA) mechanism that enables parallel processing over the $D_4$ symmetry group, alternating between intra-view relational modeling and inter-view feature alignment. Furthermore, we optimize the policy via Collective Policy Gradient Aggregation (CPGA), leveraging consensus gradients from multiple symmetric views to stabilize training and accelerate convergence. Experiments on TSP and CVRP benchmarks, as well as real-world TSPLIB instances, demonstrate that MViewRouter achieves competitive solution quality and strong zero-shot generalization.
A Context Augmented Multi-Play Multi-Armed Bandit Algorithm for Fast Channel Allocation in Opportunistic Spectrum Access
May 25, 2026We study the restless contextual multi-play multi-armed bandit (MP-MAB) problem for channel allocation in the opportunity spectrum access (OSA) scenario. Most existing MP-MAB methods are impractical for real-world OSA systems as they assume many ideal conditions, incur a heavy computational cost, and most importantly, ignore the impact of channel noise which is directly related to the quality of service. In this study, we embody this impact by modeling channel noise as a perturbation of the arm's reward function in MP-MAB. As there is an implicit correlation between channel state information and channel noise, we take the former as a context for MP-MAB to present the perturbation caused by the latter. We investigate two types of correlation between the context and the perturbation -- linear and nonlinear, and derive two index policies, respectively. These policies learn the correlations through a linear model and a neural network, and use estimated noise value to adjust the upper confidence bound. Numerical experiments demonstrate that the proposed policies can achieve lower regret and select sub-optimal arms in a more reasonable way.
Aligning LLMs with Graph Neural Solvers for Combinatorial Optimization
Mar 28, 2026Recent research has demonstrated the effectiveness of large language models (LLMs) in solving combinatorial optimization problems (COPs) by representing tasks and instances in natural language. However, purely language-based approaches struggle to accurately capture complex relational structures inherent in many COPs, rendering them less effective at addressing medium-sized or larger instances. To address these limitations, we propose AlignOPT, a novel approach that aligns LLMs with graph neural solvers to learn a more generalizable neural COP heuristic. Specifically, AlignOPT leverages the semantic understanding capabilities of LLMs to encode textual descriptions of COPs and their instances, while concurrently exploiting graph neural solvers to explicitly model the underlying graph structures of COP instances. Our approach facilitates a robust integration and alignment between linguistic semantics and structural representations, enabling more accurate and scalable COP solutions. Experimental results demonstrate that AlignOPT achieves state-of-the-art results across diverse COPs, underscoring its effectiveness in aligning semantic and structural representations. In particular, AlignOPT demonstrates strong generalization, effectively extending to previously unseen COP instances.
A scalable neural bundle map for multiphysics prediction in lithium-ion battery across varying configurations
Mar 17, 2026Efficient and accurate prediction of Multiphysics evolution across diverse cell geometries is fundamental to the design, management and safety of lithium-ion batteries. However, existing computational frameworks struggle to capture the coupled electrochemical, thermal, and mechanical dynamics across diverse cell geometries and varying operating conditions. Here, we present a Neural Bundle Map (NBM), a mathematically rigorous framework that reformulates multiphysics evolution as a bundle map over a geometric base manifold. This approach enables the complete decoupling of geometric complexity from underlying physical laws, ensuring strong operator continuity across varying domains. Our framework achieves high-fidelity spatiotemporal predictions with a normalized mean absolute error of less than 1% across varying configurations, while maintaining stability during long-horizon forecasting far beyond the training window and reducing computational costs by two orders of magnitude compared with conventional solvers. Leveraging this capability, we rapidly explored a vast configurational space to identify an optimal battery design that yields a 38% increase in energy density while adhering to thermal safety constraints. Furthermore, the NBM demonstrates remarkable scalability to multi-cell systems through few-shot transfer learning, providing a foundational paradigm for the intelligent design and real-time monitoring of complex energy storage infrastructures.
Knowledge capture, adaptation and composition (KCAC): A framework for cross-task curriculum learning in robotic manipulation
May 15, 2025Reinforcement learning (RL) has demonstrated remarkable potential in robotic manipulation but faces challenges in sample inefficiency and lack of interpretability, limiting its applicability in real world scenarios. Enabling the agent to gain a deeper understanding and adapt more efficiently to diverse working scenarios is crucial, and strategic knowledge utilization is a key factor in this process. This paper proposes a Knowledge Capture, Adaptation, and Composition (KCAC) framework to systematically integrate knowledge transfer into RL through cross-task curriculum learning. KCAC is evaluated using a two block stacking task in the CausalWorld benchmark, a complex robotic manipulation environment. To our knowledge, existing RL approaches fail to solve this task effectively, reflecting deficiencies in knowledge capture. In this work, we redesign the benchmark reward function by removing rigid constraints and strict ordering, allowing the agent to maximize total rewards concurrently and enabling flexible task completion. Furthermore, we define two self-designed sub-tasks and implement a structured cross-task curriculum to facilitate efficient learning. As a result, our KCAC approach achieves a 40 percent reduction in training time while improving task success rates by 10 percent compared to traditional RL methods. Through extensive evaluation, we identify key curriculum design parameters subtask selection, transition timing, and learning rate that optimize learning efficiency and provide conceptual guidance for curriculum based RL frameworks. This work offers valuable insights into curriculum design in RL and robotic learning.
Socially-Aware Autonomous Driving: Inferring Yielding Intentions for Safer Interactions
Apr 28, 2025



Since the emergence of autonomous driving technology, it has advanced rapidly over the past decade. It is becoming increasingly likely that autonomous vehicles (AVs) would soon coexist with human-driven vehicles (HVs) on the roads. Currently, safety and reliable decision-making remain significant challenges, particularly when AVs are navigating lane changes and interacting with surrounding HVs. Therefore, precise estimation of the intentions of surrounding HVs can assist AVs in making more reliable and safe lane change decision-making. This involves not only understanding their current behaviors but also predicting their future motions without any direct communication. However, distinguishing between the passing and yielding intentions of surrounding HVs still remains ambiguous. To address the challenge, we propose a social intention estimation algorithm rooted in Directed Acyclic Graph (DAG), coupled with a decision-making framework employing Deep Reinforcement Learning (DRL) algorithms. To evaluate the method's performance, the proposed framework can be tested and applied in a lane-changing scenario within a simulated environment. Furthermore, the experiment results demonstrate how our approach enhances the ability of AVs to navigate lane changes safely and efficiently on roads.
FluentLip: A Phonemes-Based Two-stage Approach for Audio-Driven Lip Synthesis with Optical Flow Consistency
Apr 06, 2025Generating consecutive images of lip movements that align with a given speech in audio-driven lip synthesis is a challenging task. While previous studies have made strides in synchronization and visual quality, lip intelligibility and video fluency remain persistent challenges. This work proposes FluentLip, a two-stage approach for audio-driven lip synthesis, incorporating three featured strategies. To improve lip synchronization and intelligibility, we integrate a phoneme extractor and encoder to generate a fusion of audio and phoneme information for multimodal learning. Additionally, we employ optical flow consistency loss to ensure natural transitions between image frames. Furthermore, we incorporate a diffusion chain during the training of Generative Adversarial Networks (GANs) to improve both stability and efficiency. We evaluate our proposed FluentLip through extensive experiments, comparing it with five state-of-the-art (SOTA) approaches across five metrics, including a proposed metric called Phoneme Error Rate (PER) that evaluates lip pose intelligibility and video fluency. The experimental results demonstrate that our FluentLip approach is highly competitive, achieving significant improvements in smoothness and naturalness. In particular, it outperforms these SOTA approaches by approximately $\textbf{16.3%}$ in Fr\'echet Inception Distance (FID) and $\textbf{35.2%}$ in PER.
DualOpt: A Dual Divide-and-Optimize Algorithm for the Large-scale Traveling Salesman Problem
Jan 15, 2025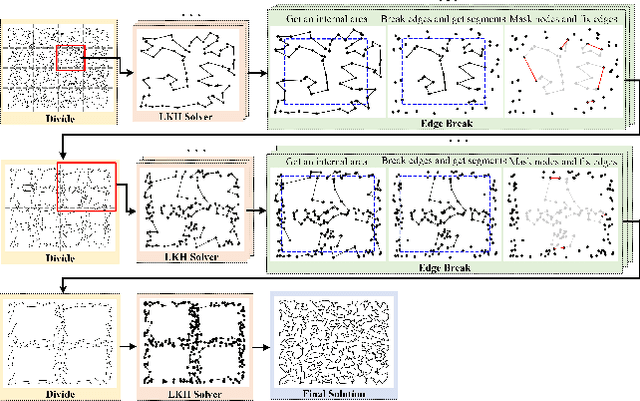

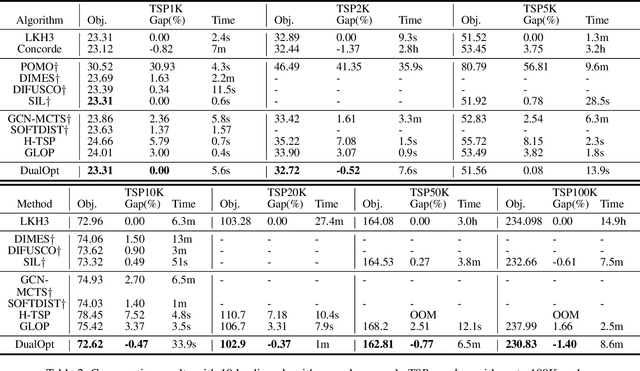
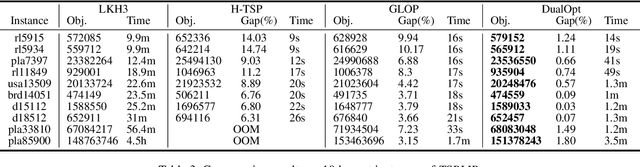
This paper proposes a dual divide-and-optimize algorithm (DualOpt) for solving the large-scale traveling salesman problem (TSP). DualOpt combines two complementary strategies to improve both solution quality and computational efficiency. The first strategy is a grid-based divide-and-conquer procedure that partitions the TSP into smaller sub-problems, solving them in parallel and iteratively refining the solution by merging nodes and partial routes. The process continues until only one grid remains, yielding a high-quality initial solution. The second strategy involves a path-based divide-and-optimize procedure that further optimizes the solution by dividing it into sub-paths, optimizing each using a neural solver, and merging them back to progressively improve the overall solution. Extensive experiments conducted on two groups of TSP benchmark instances, including randomly generated instances with up to 100,000 nodes and real-world datasets from TSPLIB, demonstrate the effectiveness of DualOpt. The proposed DualOpt achieves highly competitive results compared to 10 state-of-the-art algorithms in the literature. In particular, DualOpt achieves an improvement gap up to 1.40% for the largest instance TSP100K with a remarkable 104x speed-up over the leading heuristic solver LKH3. Additionally, DualOpt demonstrates strong generalization on TSPLIB benchmarks, confirming its capability to tackle diverse real-world TSP applications.
Transitive Vision-Language Prompt Learning for Domain Generalization
Apr 29, 2024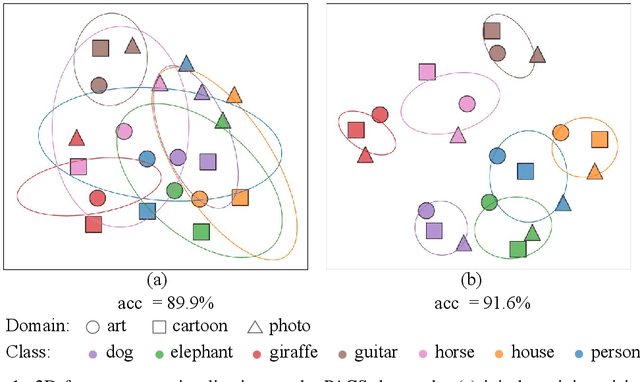
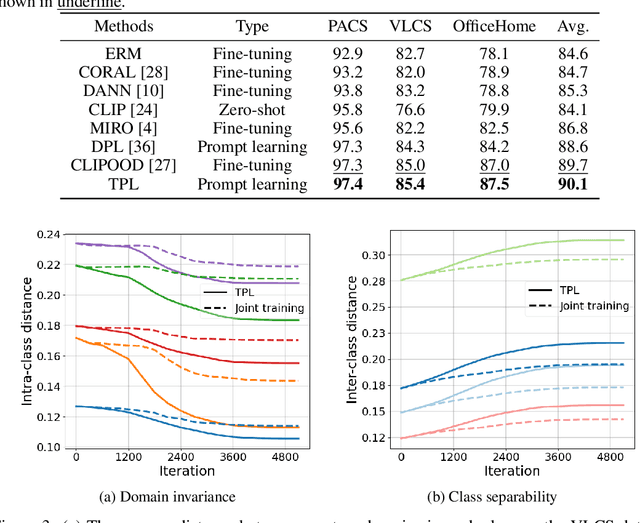
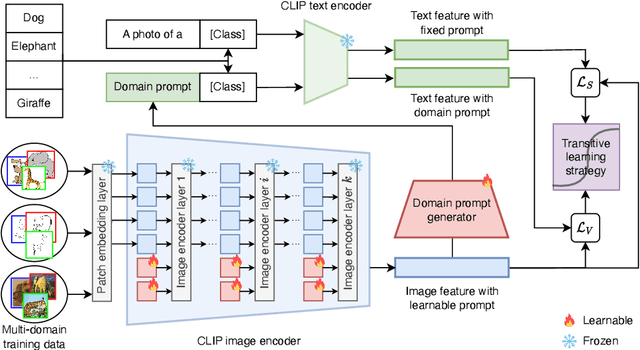

The vision-language pre-training has enabled deep models to make a huge step forward in generalizing across unseen domains. The recent learning method based on the vision-language pre-training model is a great tool for domain generalization and can solve this problem to a large extent. However, there are still some issues that an advancement still suffers from trading-off between domain invariance and class separability, which are crucial in current DG problems. However, there are still some issues that an advancement still suffers from trading-off between domain invariance and class separability, which are crucial in current DG problems. In this paper, we introduce a novel prompt learning strategy that leverages deep vision prompts to address domain invariance while utilizing language prompts to ensure class separability, coupled with adaptive weighting mechanisms to balance domain invariance and class separability. Extensive experiments demonstrate that deep vision prompts effectively extract domain-invariant features, significantly improving the generalization ability of deep models and achieving state-of-the-art performance on three datasets.
Dynamically Anchored Prompting for Task-Imbalanced Continual Learning
Apr 23, 2024



Existing continual learning literature relies heavily on a strong assumption that tasks arrive with a balanced data stream, which is often unrealistic in real-world applications. In this work, we explore task-imbalanced continual learning (TICL) scenarios where the distribution of task data is non-uniform across the whole learning process. We find that imbalanced tasks significantly challenge the capability of models to control the trade-off between stability and plasticity from the perspective of recent prompt-based continual learning methods. On top of the above finding, we propose Dynamically Anchored Prompting (DAP), a prompt-based method that only maintains a single general prompt to adapt to the shifts within a task stream dynamically. This general prompt is regularized in the prompt space with two specifically designed prompt anchors, called boosting anchor and stabilizing anchor, to balance stability and plasticity in TICL. Remarkably, DAP achieves this balance by only storing a prompt across the data stream, therefore offering a substantial advantage in rehearsal-free CL. Extensive experiments demonstrate that the proposed DAP results in 4.5% to 15% absolute improvements over state-of-the-art methods on benchmarks under task-imbalanced settings. Our code is available at https://github.com/chenxing6666/DAP