 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualOpt: A Dual Divide-and-Optimize Algorithm for the Large-scale Traveling Salesman Problem
Jan 15, 2025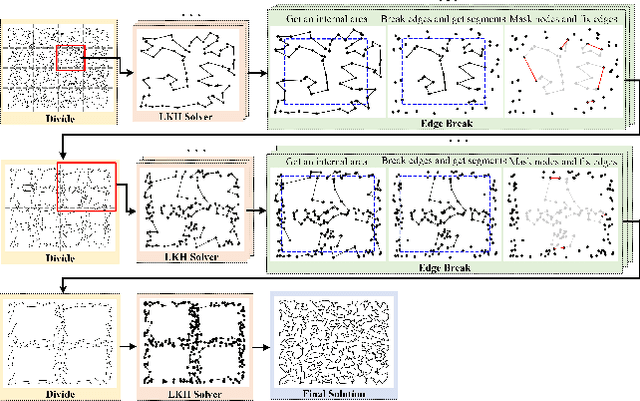

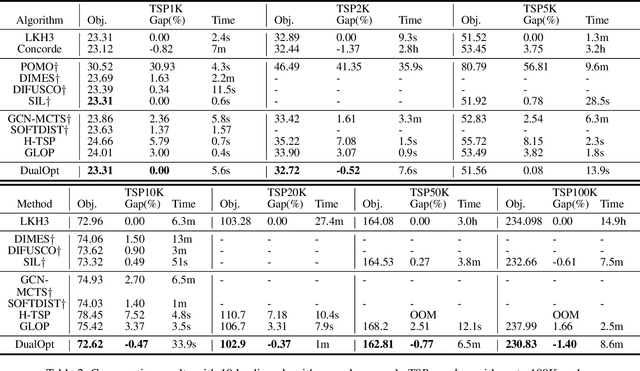
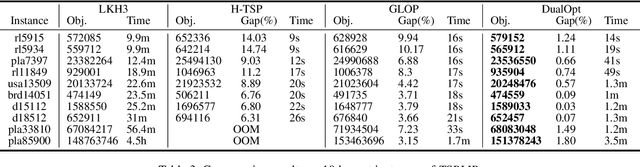
This paper proposes a dual divide-and-optimize algorithm (DualOpt) for solving the large-scale traveling salesman problem (TSP). DualOpt combines two complementary strategies to improve both solution quality and computational efficiency. The first strategy is a grid-based divide-and-conquer procedure that partitions the TSP into smaller sub-problems, solving them in parallel and iteratively refining the solution by merging nodes and partial routes. The process continues until only one grid remains, yielding a high-quality initial solution. The second strategy involves a path-based divide-and-optimize procedure that further optimizes the solution by dividing it into sub-paths, optimizing each using a neural solver, and merging them back to progressively improve the overall solution. Extensive experiments conducted on two groups of TSP benchmark instances, including randomly generated instances with up to 100,000 nodes and real-world datasets from TSPLIB, demonstrate the effectiveness of DualOpt. The proposed DualOpt achieves highly competitive results compared to 10 state-of-the-art algorithms in the literature. In particular, DualOpt achieves an improvement gap up to 1.40% for the largest instance TSP100K with a remarkable 104x speed-up over the leading heuristic solver LKH3. Additionally, DualOpt demonstrates strong generalization on TSPLIB benchmarks, confirming its capability to tackle diverse real-world TSP applications.
H-TSP: Hierarchically Solving the Large-Scale Travelling Salesman Problem
Apr 19, 2023



We propose an end-to-end learning framework based on hierarchical reinforcement learning, called H-TSP, for addressing the large-scale Travelling Salesman Problem (TSP). The proposed H-TSP constructs a solution of a TSP instance starting from the scratch relying on two components: the upper-level policy chooses a small subset of nodes (up to 200 in our experiment) from all nodes that are to be traversed, while the lower-level policy takes the chosen nodes as input and outputs a tour connecting them to the existing partial route (initially only containing the depot). After jointly training the upper-level and lower-level policies, our approach can directly generate solutions for the given TSP instances without relying on any time-consuming search procedures. To demonstrate effectiveness of the proposed approach, we have conducted extensive experiments on randomly generated TSP instances with different numbers of nodes. We show that H-TSP can achieve comparable results (gap 3.42% vs. 7.32%) as SOTA search-based approaches, and more importantly, we reduce the time consumption up to two orders of magnitude (3.32s vs. 395.85s). To the best of our knowledge, H-TSP is the first end-to-end deep reinforcement learning approach that can scale to TSP instances of up to 10000 nodes. Although there are still gaps to SOTA results with respect to solution quality, we believe that H-TSP will be useful for practical applications, particularly those that are time-sensitive e.g., on-call routing and ride hailing service.
Pointerformer: Deep Reinforced Multi-Pointer Transformer for the Traveling Salesman Problem
Apr 19, 2023



Traveling Salesman Problem (TSP), as a classic routing optimization problem originally arising in the domain of transportation and logistics, has become a critical task in broader domains, such as manufacturing and biology. Recently, Deep Reinforcement Learning (DRL) has been increasingly employed to solve TSP due to its high inference efficiency. Nevertheless, most of existing end-to-end DRL algorithms only perform well on small TSP instances and can hardly generalize to large scale because of the drastically soaring memory consumption and computation time along with the enlarging problem scale. In this paper, we propose a novel end-to-end DRL approach, referred to as Pointerformer, based on multi-pointer Transformer. Particularly, Pointerformer adopts both reversible residual network in the encoder and multi-pointer network in the decoder to effectively contain memory consumption of the encoder-decoder architecture. To further improve the performance of TSP solutions, Pointerformer employs both a feature augmentation method to explore the symmetries of TSP at both training and inference stages as well as an enhanced context embedding approach to include more comprehensive context information in the query. Extensive experiments on a randomly generated benchmark and a public benchmark have shown that, while achieving comparative results on most small-scale TSP instances as SOTA DRL approaches do, Pointerformer can also well generalize to large-scale TSPs.
Multi-Agent Reinforcement Learning with Shared Resources for Inventory Management
Dec 18, 2022



In this paper, we consider the inventory management (IM) problem where we need to make replenishment decisions for a large number of stock keeping units (SKUs) to balance their supply and demand. In our setting, the constraint on the shared resources (such as the inventory capacity) couples the otherwise independent control for each SKU. We formulate the problem with this structure as Shared-Resource Stochastic Game (SRSG)and propose an efficient algorithm called Context-aware Decentralized PPO (CD-PPO). Through extensive experiments, we demonstrate that CD-PPO can accelerate the learning procedure compared with standard MARL algorithms.