 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat to Ignore, What to React: Visually Robust RL Fine-Tuning of VLA Models
May 13, 2026Reinforcement learning (RL) fine-tuning has shown promise for Vision-Language-Action (VLA) models in robotic manipulation, but deployment-time visual shifts pose practical challenges. A key difficulty is that standard task rewards supervise task success, but offer limited guidance on whether a visual change is task-irrelevant or changes the behavior required for manipulation. We propose PAIR-VLA (Paired Action Invariance & Sensitivity for Visually Robust VLA), an RL fine-tuning framework to address this difficulty by adding two auxiliary objectives over paired visual variants during PPO optimization: an invariance term that reduces the discrepancy between action distributions for a task-preserving pair (e.g., different distractors), and a sensitivity objective that encourages separable action distributions for a task-altering pair (e.g., target object in a different pose). Together, these objectives turn visual variants from mere observation diversity into behavior-level guidance on policy responses during RL fine-tuning. We evaluate on ManiSkill3 across two representative VLA architectures, OpenVLA and $π_{0.5}$, under diverse out-of-distribution visual shifts including unseen distractors, texture changes, target object pose variation, viewpoint shifts, and lighting changes. Our method consistently improves over standard PPO, achieving average improvements of 16.62% on $π_{0.5}$ and 9.10% on OpenVLA. Notably, ablations further show generalization across visual shifts: invariance guidance learned from distractor and texture variants transfers to target-pose and lighting shifts, while adding sensitivity guidance on target-pose variants further improves robustness to nuisance shifts, highlighting the broader transferability of behavior-level RL guidance.
Unified Noise Steering for Efficient Human-Guided VLA Adaptation
May 11, 2026Diffusion-based vision-language-action (VLA) models have emerged as strong priors for robotic manipulation, yet adapting them to real-world distributions remains challenging. In particular, on-robot reinforcement learning (RL) is expensive and time-consuming, so effective adaptation depends on efficient policy improvement within a limited budget of real-world interactions. Noise-space RL lowers the cost by keeping the pretrained VLA fixed as a denoising generator while updating only a lightweight actor that predicts the noise. However, its performance is still limited due to inefficient autonomous exploration. Human corrective interventions can reduce this exploration burden, but they are naturally provided in action space, whereas noise-space finetuning requires supervision over noise variables. To address these challenges, we propose UniSteer, a Unified Noise Steering framework that combines human corrective guidance with noise-space RL through approximate action-to-noise inversion. Given a human corrective action, UniSteer inverts the frozen flow-matching decoder to recover a noise target, which provides supervised guidance for the same noise actor that is simultaneously optimized via reinforcement learning. Real-world experiments on diverse manipulation tasks show that UniSteer adapts more efficiently than strong noise-space RL and action-space human-in-the-loop baselines, improving the success rate from 20% to 90% in 66 minutes on average across four real-world adaptation tasks.
Learning Additively Compositional Latent Actions for Embodied AI
Apr 03, 2026Latent action learning infers pseudo-action labels from visual transitions, providing an approach to leverage internet-scale video for embodied AI. However, most methods learn latent actions without structural priors that encode the additive, compositional structure of physical motion. As a result, latents often entangle irrelevant scene details or information about future observations with true state changes and miscalibrate motion magnitude. We introduce Additively Compositional Latent Action Model (AC-LAM), which enforces scene-wise additive composition structure over short horizons on the latent action space. These AC constraints encourage simple algebraic structure in the latent action space~(identity, inverse, cycle consistency) and suppress information that does not compose additively. Empirically, AC-LAM learns more structured, motion-specific, and displacement-calibrated latent actions and provides stronger supervision for downstream policy learning, outperforming state-of-the-art LAMs across simulated and real-world tabletop tasks.
ALOE: Action-Level Off-Policy Evaluation for Vision-Language-Action Model Post-Training
Feb 13, 2026We study how to improve large foundation vision-language-action (VLA) systems through online reinforcement learning (RL) in real-world settings. Central to this process is the value function, which provides learning signals to guide VLA learning from experience. In practice, the value function is estimated from trajectory fragments collected from different data sources, including historical policies and intermittent human interventions. Estimating the value function of current behavior quality from the mixture data is inherently an off-policy evaluation problem. However, prior work often adopts conservative on-policy estimation for stability, which avoids direct evaluation of the current high-capacity policy and limits learning effectiveness. In this paper, we propose ALOE, an action-level off-policy evaluation framework for VLA post-training. ALOE applies chunking-based temporal-difference bootstrapping to evaluate individual action sequences instead of predicting final task outcomes. This design improves effective credit assignment to critical action chunks under sparse rewards and supports stable policy improvement. We evaluate our method on three real-world manipulation tasks, including smartphone packing as a high-precision task, laundry folding as a long-horizon deformable-object task, and bimanual pick-and-place involving multi-object perception. Across all tasks, ALOE improves learning efficiency without compromising execution speed, showing that off-policy RL can be reintroduced in a reliable manner for real-world VLA post-training. Videos and additional materials are available at our project website.
ChatAD: Reasoning-Enhanced Time-Series Anomaly Detection with Multi-Turn Instruction Evolution
Jan 20, 2026LLM-driven Anomaly Detection (AD) helps enhance the understanding and explanatory abilities of anomalous behaviors in Time Series (TS). Existing methods face challenges of inadequate reasoning ability, deficient multi-turn dialogue capability, and narrow generalization. To this end, we 1) propose a multi-agent-based TS Evolution algorithm named TSEvol. On top of it, we 2) introduce the AD reasoning and multi-turn dialogue Dataset TSEData-20K and contribute the Chatbot family for AD, including ChatAD-Llama3-8B, Qwen2.5-7B, and Mistral-7B. Furthermore, 3) we propose the TS Kahneman-Tversky Optimization (TKTO) to enhance ChatAD's cross-task generalization capability. Lastly, 4) we propose a LLM-driven Learning-based AD Benchmark LLADBench to evaluate the performance of ChatAD and nine baselines across seven datasets and tasks. Our three ChatAD models achieve substantial gains, up to 34.50% in accuracy, 34.71% in F1, and a 37.42% reduction in false positives. Besides, via KTKO, our optimized ChatAD achieves competitive performance in reasoning and cross-task generalization on classification, forecasting, and imputation.
How Do VLAs Effectively Inherit from VLMs?
Nov 10, 2025Vision-language-action (VLA) models hold the promise to attain generalizable embodied control. To achieve this, a pervasive paradigm is to leverage the rich vision-semantic priors of large vision-language models (VLMs). However, the fundamental question persists: How do VLAs effectively inherit the prior knowledge from VLMs? To address this critical question, we introduce a diagnostic benchmark, GrinningFace, an emoji tabletop manipulation task where the robot arm is asked to place objects onto printed emojis corresponding to language instructions. This task design is particularly revealing -- knowledge associated with emojis is ubiquitous in Internet-scale datasets used for VLM pre-training, yet emojis themselves are largely absent from standard robotics datasets. Consequently, they provide a clean proxy: successful task completion indicates effective transfer of VLM priors to embodied control. We implement this diagnostic task in both simulated environment and a real robot, and compare various promising techniques for knowledge transfer. Specifically, we investigate the effects of parameter-efficient fine-tuning, VLM freezing, co-training, predicting discretized actions, and predicting latent actions. Through systematic evaluation, our work not only demonstrates the critical importance of preserving VLM priors for the generalization of VLA but also establishes guidelines for future research in developing truly generalizable embodied AI systems.
villa-X: Enhancing Latent Action Modeling in Vision-Language-Action Models
Jul 31, 2025Visual-Language-Action (VLA) models have emerged as a popular paradigm for learning robot manipulation policies that can follow language instructions and generalize to novel scenarios. Recent work has begun to explore the incorporation of latent actions, an abstract representation of visual change between two frames, into VLA pre-training. In this paper, we introduce villa-X, a novel Visual-Language-Latent-Action (ViLLA) framework that advances latent action modeling for learning generalizable robot manipulation policies. Our approach improves both how latent actions are learned and how they are incorporated into VLA pre-training. Together, these contributions enable villa-X to achieve superior performance across simulated environments including SIMPLER and LIBERO, as well as on two real-world robot setups including gripper and dexterous hand manipulation. We believe the ViLLA paradigm holds significant promise, and that our villa-X provides a strong foundation for future research.
PIG-Nav: Key Insights for Pretrained Image Goal Navigation Models
Jul 23, 2025
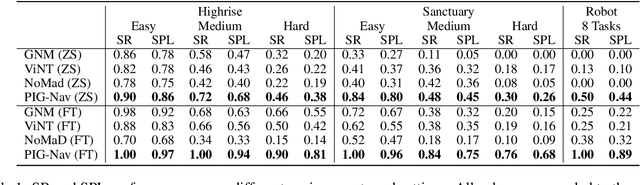
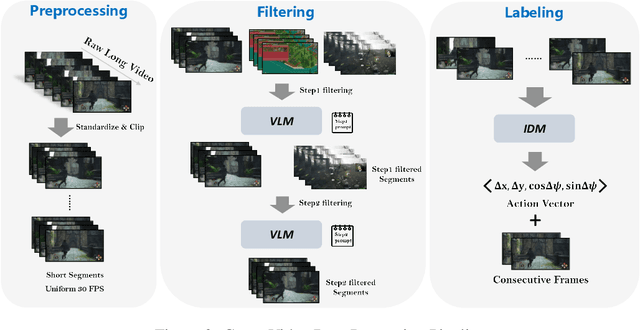
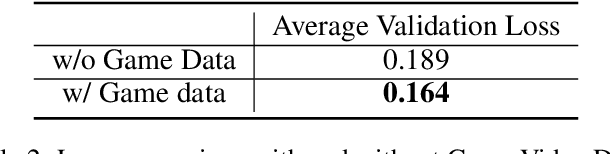
Recent studies have explored pretrained (foundation) models for vision-based robotic navigation, aiming to achieve generalizable navigation and positive transfer across diverse environments while enhancing zero-shot performance in unseen settings. In this work, we introduce PIG-Nav (Pretrained Image-Goal Navigation), a new approach that further investigates pretraining strategies for vision-based navigation models and contributes in two key areas. Model-wise, we identify two critical design choices that consistently improve the performance of pretrained navigation models: (1) integrating an early-fusion network structure to combine visual observations and goal images via appropriately pretrained Vision Transformer (ViT) image encoder, and (2) introducing suitable auxiliary tasks to enhance global navigation representation learning, thus further improving navigation performance. Dataset-wise, we propose a novel data preprocessing pipeline for efficiently labeling large-scale game video datasets for navigation model training. We demonstrate that augmenting existing open navigation datasets with diverse gameplay videos improves model performance. Our model achieves an average improvement of 22.6% in zero-shot settings and a 37.5% improvement in fine-tuning settings over existing visual navigation foundation models in two complex simulated environments and one real-world environment. These results advance the state-of-the-art in pretrained image-goal navigation models. Notably, our model maintains competitive performance while requiring significantly less fine-tuning data, highlighting its potential for real-world deployment with minimal labeled supervision.
Reward-Driven Interaction: Enhancing Proactive Dialogue Agents through User Satisfaction Prediction
May 24, 2025Reward-driven proactive dialogue agents require precise estimation of user satisfaction as an intrinsic reward signal to determine optimal interaction strategies. Specifically, this framework triggers clarification questions when detecting potential user dissatisfaction during interactions in the industrial dialogue system. Traditional works typically rely on training a neural network model based on weak labels which are generated by a simple model trained on user actions after current turn. However, existing methods suffer from two critical limitations in real-world scenarios: (1) Noisy Reward Supervision, dependence on weak labels derived from post-hoc user actions introduces bias, particularly failing to capture satisfaction signals in ASR-error-induced utterances; (2) Long-Tail Feedback Sparsity, the power-law distribution of user queries causes reward prediction accuracy to drop in low-frequency domains. The noise in the weak labels and a power-law distribution of user utterances results in that the model is hard to learn good representation of user utterances and sessions. To address these limitations, we propose two auxiliary tasks to improve the representation learning of user utterances and sessions that enhance user satisfaction prediction. The first one is a contrastive self-supervised learning task, which helps the model learn the representation of rare user utterances and identify ASR errors. The second one is a domain-intent classification task, which aids the model in learning the representation of user sessions from long-tailed domains and improving the model's performance on such domains. The proposed method is evaluated on DuerOS, demonstrating significant improvements in the accuracy of error recognition on rare user utterances and long-tailed domains.
AdaptiveStep: Automatically Dividing Reasoning Step through Model Confidence
Feb 19, 2025Current approaches for training Process Reward Models (PRMs) often involve breaking down responses into multiple reasoning steps using rule-based techniques, such as using predefined placeholder tokens or setting the reasoning step's length into a fixed size. These approaches overlook the fact that specific words do not typically mark true decision points in a text. To address this, we propose AdaptiveStep, a method that divides reasoning steps based on the model's confidence in predicting the next word. This division method provides more decision-making information at each step, enhancing downstream tasks, such as reward model learning. Moreover, our method does not require manual annotation. We demonstrate its effectiveness through experiments with AdaptiveStep-trained PRMs in mathematical reasoning and code generation tasks. Experimental results indicate that the outcome PRM achieves state-of-the-art Best-of-N performance, surpassing greedy search strategy with token-level value-guided decoding, while also reducing construction costs by over 30% compared to existing open-source PRMs. In addition, we provide a thorough analysis and case study on the PRM's performance, transferability, and generalization capabilities.