 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
Empowering Large Language Models on Robotic Manipulation with Affordance Prompting
Apr 17, 2024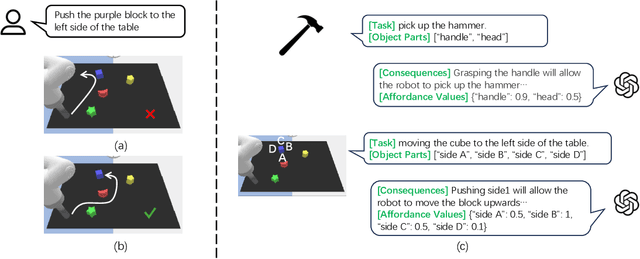
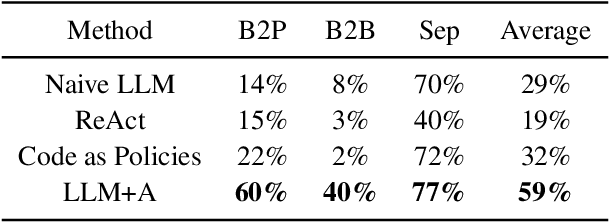
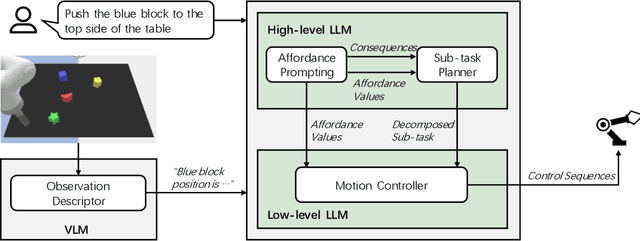
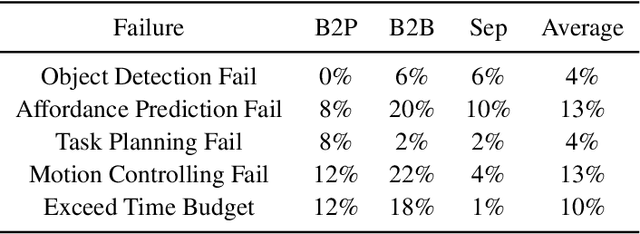
While large language models (LLMs) are successful in completing various language processing tasks, they easily fail to interact with the physical world by generating control sequences properly. We find that the main reason is that LLMs are not grounded in the physical world. Existing LLM-based approaches circumvent this problem by relying on additional pre-defined skills or pre-trained sub-policies, making it hard to adapt to new tasks. In contrast, we aim to address this problem and explore the possibility to prompt pre-trained LLMs to accomplish a series of robotic manipulation tasks in a training-free paradigm. Accordingly, we propose a framework called LLM+A(ffordance) where the LLM serves as both the sub-task planner (that generates high-level plans) and the motion controller (that generates low-level control sequences). To ground these plans and control sequences on the physical world, we develop the affordance prompting technique that stimulates the LLM to 1) predict the consequences of generated plans and 2) generate affordance values for relevant objects. Empirically, we evaluate the effectiveness of LLM+A in various language-conditioned robotic manipulation tasks, which show that our approach substantially improves performance by enhancing the feasibility of generated plans and control and can easily generalize to different environments.
XuanCe: A Comprehensive and Unified Deep Reinforcement Learning Library
Dec 25, 2023In this paper, we present XuanCe, a comprehensive and unified deep reinforcement learning (DRL) library designed to be compatible with PyTorch, TensorFlow, and MindSpore. XuanCe offers a wide range of functionalities, including over 40 classical DRL and multi-agent DRL algorithms, with the flexibility to easily incorporate new algorithms and environments. It is a versatile DRL library that supports CPU, GPU, and Ascend, and can be executed on various operating systems such as Ubuntu, Windows, MacOS, and EulerOS. Extensive benchmarks conducted on popular environments including MuJoCo, Atari, and StarCraftII multi-agent challenge demonstrate the library's impressive performance. XuanCe is open-source and can be accessed at https://github.com/agi-brain/xuance.git.
DGMem: Learning Visual Navigation Policy without Any Labels by Dynamic Graph Memory
Nov 30, 2023In recent years, learning-based approaches have demonstrated significant promise in addressing intricate navigation tasks. Traditional methods for training deep neural network navigation policies rely on meticulously designed reward functions or extensive teleoperation datasets as navigation demonstrations. However, the former is often confined to simulated environments, and the latter demands substantial human labor, making it a time-consuming process. Our vision is for robots to autonomously learn navigation skills and adapt their behaviors to environmental changes without any human intervention. In this work, we discuss the self-supervised navigation problem and present Dynamic Graph Memory (DGMem), which facilitates training only with on-board observations. With the help of DGMem, agents can actively explore their surroundings, autonomously acquiring a comprehensive navigation policy in a data-efficient manner without external feedback. Our method is evaluated in photorealistic 3D indoor scenes, and empirical studies demonstrate the effectiveness of DGMem.
Robust Navigation with Cross-Modal Fusion and Knowledge Transfer
Sep 23, 2023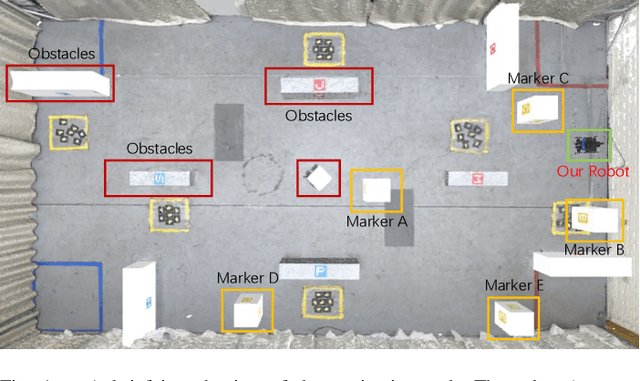
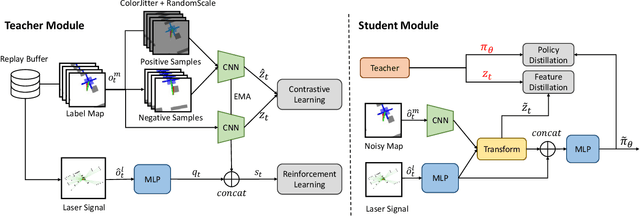

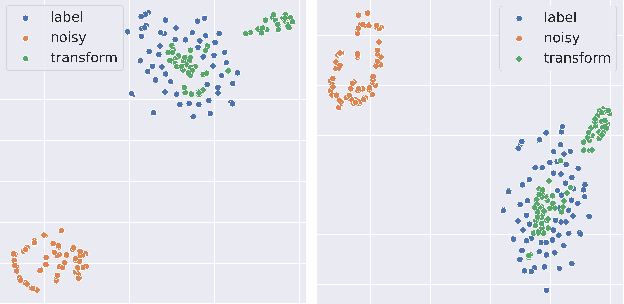
Recently, learning-based approaches show promising results in navigation tasks. However, the poor generalization capability and the simulation-reality gap prevent a wide range of applications. We consider the problem of improving the generalization of mobile robots and achieving sim-to-real transfer for navigation skills. To that end, we propose a cross-modal fusion method and a knowledge transfer framework for better generalization. This is realized by a teacher-student distillation architecture. The teacher learns a discriminative representation and the near-perfect policy in an ideal environment. By imitating the behavior and representation of the teacher, the student is able to align the features from noisy multi-modal input and reduce the influence of variations on navigation policy. We evaluate our method in simulated and real-world environments. Experiments show that our method outperforms the baselines by a large margin and achieves robust navigation performance with varying working conditions.
Bridging Zero-shot Object Navigation and Foundation Models through Pixel-Guided Navigation Skill
Sep 21, 2023



Zero-shot object navigation is a challenging task for home-assistance robots. This task emphasizes visual grounding, commonsense inference and locomotion abilities, where the first two are inherent in foundation models. But for the locomotion part, most works still depend on map-based planning approaches. The gap between RGB space and map space makes it difficult to directly transfer the knowledge from foundation models to navigation tasks. In this work, we propose a Pixel-guided Navigation skill (PixNav), which bridges the gap between the foundation models and the embodied navigation task. It is straightforward for recent foundation models to indicate an object by pixels, and with pixels as the goal specification, our method becomes a versatile navigation policy towards all different kinds of objects. Besides, our PixNav is a pure RGB-based policy that can reduce the cost of home-assistance robots. Experiments demonstrate the robustness of the PixNav which achieves 80+% success rate in the local path-planning task. To perform long-horizon object navigation, we design an LLM-based planner to utilize the commonsense knowledge between objects and rooms to select the best waypoint. Evaluations across both photorealistic indoor simulators and real-world environments validate the effectiveness of our proposed navigation strategy. Code and video demos are available at https://github.com/wzcai99/Pixel-Navigator.