 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNimbus: A Unified Embodied Synthetic Data Generation Framework
Jan 29, 2026Scaling data volume and diversity is critical for generalizing embodied intelligence. While synthetic data generation offers a scalable alternative to expensive physical data acquisition, existing pipelines remain fragmented and task-specific. This isolation leads to significant engineering inefficiency and system instability, failing to support the sustained, high-throughput data generation required for foundation model training. To address these challenges, we present Nimbus, a unified synthetic data generation framework designed to integrate heterogeneous navigation and manipulation pipelines. Nimbus introduces a modular four-layer architecture featuring a decoupled execution model that separates trajectory planning, rendering, and storage into asynchronous stages. By implementing dynamic pipeline scheduling, global load balancing, distributed fault tolerance, and backend-specific rendering optimizations, the system maximizes resource utilization across CPU, GPU, and I/O resources. Our evaluation demonstrates that Nimbus achieves a 2-3X improvement in end-to-end throughput compared to unoptimized baselines and ensuring robust, long-term operation in large-scale distributed environments. This framework serves as the production backbone for the InternData suite, enabling seamless cross-domain data synthesis.
LoGoPlanner: Localization Grounded Navigation Policy with Metric-aware Visual Geometry
Dec 23, 2025Trajectory planning in unstructured environments is a fundamental and challenging capability for mobile robots. Traditional modular pipelines suffer from latency and cascading errors across perception, localization, mapping, and planning modules. Recent end-to-end learning methods map raw visual observations directly to control signals or trajectories, promising greater performance and efficiency in open-world settings. However, most prior end-to-end approaches still rely on separate localization modules that depend on accurate sensor extrinsic calibration for self-state estimation, thereby limiting generalization across embodiments and environments. We introduce LoGoPlanner, a localization-grounded, end-to-end navigation framework that addresses these limitations by: (1) finetuning a long-horizon visual-geometry backbone to ground predictions with absolute metric scale, thereby providing implicit state estimation for accurate localization; (2) reconstructing surrounding scene geometry from historical observations to supply dense, fine-grained environmental awareness for reliable obstacle avoidance; and (3) conditioning the policy on implicit geometry bootstrapped by the aforementioned auxiliary tasks, thereby reducing error propagation. We evaluate LoGoPlanner in both simulation and real-world settings, where its fully end-to-end design reduces cumulative error while metric-aware geometry memory enhances planning consistency and obstacle avoidance, leading to more than a 27.3\% improvement over oracle-localization baselines and strong generalization across embodiments and environments. The code and models have been made publicly available on the https://steinate.github.io/logoplanner.github.io.
Ground Slow, Move Fast: A Dual-System Foundation Model for Generalizable Vision-and-Language Navigation
Dec 09, 2025While recent large vision-language models (VLMs) have improved generalization in vision-language navigation (VLN), existing methods typically rely on end-to-end pipelines that map vision-language inputs directly to short-horizon discrete actions. Such designs often produce fragmented motions, incur high latency, and struggle with real-world challenges like dynamic obstacle avoidance. We propose DualVLN, the first dual-system VLN foundation model that synergistically integrates high-level reasoning with low-level action execution. System 2, a VLM-based global planner, "grounds slowly" by predicting mid-term waypoint goals via image-grounded reasoning. System 1, a lightweight, multi-modal conditioning Diffusion Transformer policy, "moves fast" by leveraging both explicit pixel goals and latent features from System 2 to generate smooth and accurate trajectories. The dual-system design enables robust real-time control and adaptive local decision-making in complex, dynamic environments. By decoupling training, the VLM retains its generalization, while System 1 achieves interpretable and effective local navigation. DualVLN outperforms prior methods across all VLN benchmarks and real-world experiments demonstrate robust long-horizon planning and real-time adaptability in dynamic environments.
NavDP: Learning Sim-to-Real Navigation Diffusion Policy with Privileged Information Guidance
May 13, 2025Learning navigation in dynamic open-world environments is an important yet challenging skill for robots. Most previous methods rely on precise localization and mapping or learn from expensive real-world demonstrations. In this paper, we propose the Navigation Diffusion Policy (NavDP), an end-to-end framework trained solely in simulation and can zero-shot transfer to different embodiments in diverse real-world environments. The key ingredient of NavDP's network is the combination of diffusion-based trajectory generation and a critic function for trajectory selection, which are conditioned on only local observation tokens encoded from a shared policy transformer. Given the privileged information of the global environment in simulation, we scale up the demonstrations of good quality to train the diffusion policy and formulate the critic value function targets with contrastive negative samples. Our demonstration generation approach achieves about 2,500 trajectories/GPU per day, 20$\times$ more efficient than real-world data collection, and results in a large-scale navigation dataset with 363.2km trajectories across 1244 scenes. Trained with this simulation dataset, NavDP achieves state-of-the-art performance and consistently outstanding generalization capability on quadruped, wheeled, and humanoid robots in diverse indoor and outdoor environments. In addition, we present a preliminary attempt at using Gaussian Splatting to make in-domain real-to-sim fine-tuning to further bridge the sim-to-real gap. Experiments show that adding such real-to-sim data can improve the success rate by 30\% without hurting its generalization capability.
ImagineNav: Prompting Vision-Language Models as Embodied Navigator through Scene Imagination
Oct 13, 2024



Visual navigation is an essential skill for home-assistance robots, providing the object-searching ability to accomplish long-horizon daily tasks. Many recent approaches use Large Language Models (LLMs) for commonsense inference to improve exploration efficiency. However, the planning process of LLMs is limited within texts and it is difficult to represent the spatial occupancy and geometry layout only by texts. Both are important for making rational navigation decisions. In this work, we seek to unleash the spatial perception and planning ability of Vision-Language Models (VLMs), and explore whether the VLM, with only on-board camera captured RGB/RGB-D stream inputs, can efficiently finish the visual navigation tasks in a mapless manner. We achieve this by developing the imagination-powered navigation framework ImagineNav, which imagines the future observation images at valuable robot views and translates the complex navigation planning process into a rather simple best-view image selection problem for VLM. To generate appropriate candidate robot views for imagination, we introduce the Where2Imagine module, which is distilled to align with human navigation habits. Finally, to reach the VLM preferred views, an off-the-shelf point-goal navigation policy is utilized. Empirical experiments on the challenging open-vocabulary object navigation benchmarks demonstrates the superiority of our proposed system.
MO-DDN: A Coarse-to-Fine Attribute-based Exploration Agent for Multi-object Demand-driven Navigation
Oct 04, 2024The process of satisfying daily demands is a fundamental aspect of humans' daily lives. With the advancement of embodied AI, robots are increasingly capable of satisfying human demands. Demand-driven navigation (DDN) is a task in which an agent must locate an object to satisfy a specified demand instruction, such as ``I am thirsty.'' The previous study typically assumes that each demand instruction requires only one object to be fulfilled and does not consider individual preferences. However, the realistic human demand may involve multiple objects. In this paper, we introduce the Multi-object Demand-driven Navigation (MO-DDN) benchmark, which addresses these nuanced aspects, including multi-object search and personal preferences, thus making the MO-DDN task more reflective of real-life scenarios compared to DDN. Building upon previous work, we employ the concept of ``attribute'' to tackle this new task. However, instead of solely relying on attribute features in an end-to-end manner like DDN, we propose a modular method that involves constructing a coarse-to-fine attribute-based exploration agent (C2FAgent). Our experimental results illustrate that this coarse-to-fine exploration strategy capitalizes on the advantages of attributes at various decision-making levels, resulting in superior performance compared to baseline methods. Code and video can be found at https://sites.google.com/view/moddn.
InstructNav: Zero-shot System for Generic Instruction Navigation in Unexplored Environment
Jun 07, 2024



Enabling robots to navigate following diverse language instructions in unexplored environments is an attractive goal for human-robot interaction. However, this goal is challenging because different navigation tasks require different strategies. The scarcity of instruction navigation data hinders training an instruction navigation model with varied strategies. Therefore, previous methods are all constrained to one specific type of navigation instruction. In this work, we propose InstructNav, a generic instruction navigation system. InstructNav makes the first endeavor to handle various instruction navigation tasks without any navigation training or pre-built maps. To reach this goal, we introduce Dynamic Chain-of-Navigation (DCoN) to unify the planning process for different types of navigation instructions. Furthermore, we propose Multi-sourced Value Maps to model key elements in instruction navigation so that linguistic DCoN planning can be converted into robot actionable trajectories. With InstructNav, we complete the R2R-CE task in a zero-shot way for the first time and outperform many task-training methods. Besides, InstructNav also surpasses the previous SOTA method by 10.48% on the zero-shot Habitat ObjNav and by 86.34% on demand-driven navigation DDN. Real robot experiments on diverse indoor scenes further demonstrate our method's robustness in coping with the environment and instruction variations.
Empowering Large Language Models on Robotic Manipulation with Affordance Prompting
Apr 17, 2024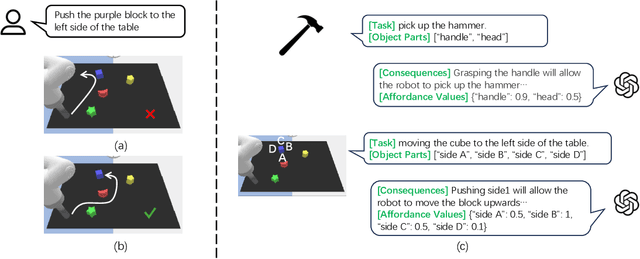
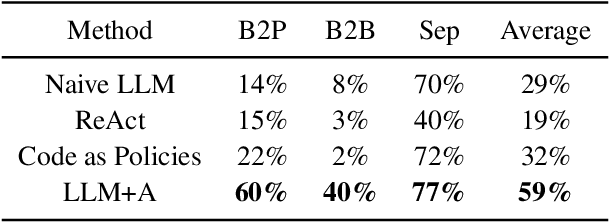
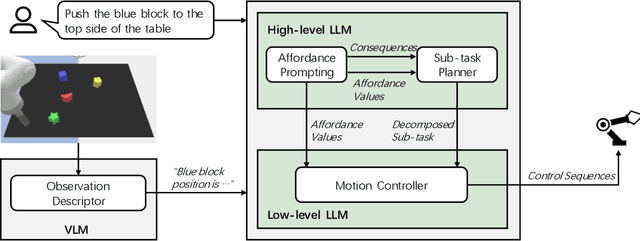
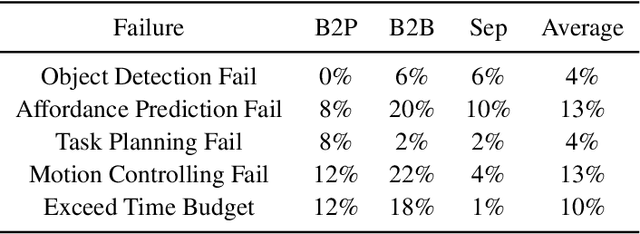
While large language models (LLMs) are successful in completing various language processing tasks, they easily fail to interact with the physical world by generating control sequences properly. We find that the main reason is that LLMs are not grounded in the physical world. Existing LLM-based approaches circumvent this problem by relying on additional pre-defined skills or pre-trained sub-policies, making it hard to adapt to new tasks. In contrast, we aim to address this problem and explore the possibility to prompt pre-trained LLMs to accomplish a series of robotic manipulation tasks in a training-free paradigm. Accordingly, we propose a framework called LLM+A(ffordance) where the LLM serves as both the sub-task planner (that generates high-level plans) and the motion controller (that generates low-level control sequences). To ground these plans and control sequences on the physical world, we develop the affordance prompting technique that stimulates the LLM to 1) predict the consequences of generated plans and 2) generate affordance values for relevant objects. Empirically, we evaluate the effectiveness of LLM+A in various language-conditioned robotic manipulation tasks, which show that our approach substantially improves performance by enhancing the feasibility of generated plans and control and can easily generalize to different environments.
XuanCe: A Comprehensive and Unified Deep Reinforcement Learning Library
Dec 25, 2023In this paper, we present XuanCe, a comprehensive and unified deep reinforcement learning (DRL) library designed to be compatible with PyTorch, TensorFlow, and MindSpore. XuanCe offers a wide range of functionalities, including over 40 classical DRL and multi-agent DRL algorithms, with the flexibility to easily incorporate new algorithms and environments. It is a versatile DRL library that supports CPU, GPU, and Ascend, and can be executed on various operating systems such as Ubuntu, Windows, MacOS, and EulerOS. Extensive benchmarks conducted on popular environments including MuJoCo, Atari, and StarCraftII multi-agent challenge demonstrate the library's impressive performance. XuanCe is open-source and can be accessed at https://github.com/agi-brain/xuance.git.
DGMem: Learning Visual Navigation Policy without Any Labels by Dynamic Graph Memory
Nov 30, 2023In recent years, learning-based approaches have demonstrated significant promise in addressing intricate navigation tasks. Traditional methods for training deep neural network navigation policies rely on meticulously designed reward functions or extensive teleoperation datasets as navigation demonstrations. However, the former is often confined to simulated environments, and the latter demands substantial human labor, making it a time-consuming process. Our vision is for robots to autonomously learn navigation skills and adapt their behaviors to environmental changes without any human intervention. In this work, we discuss the self-supervised navigation problem and present Dynamic Graph Memory (DGMem), which facilitates training only with on-board observations. With the help of DGMem, agents can actively explore their surroundings, autonomously acquiring a comprehensive navigation policy in a data-efficient manner without external feedback. Our method is evaluated in photorealistic 3D indoor scenes, and empirical studies demonstrate the effectiveness of DGMem.