 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially Generalizable Mobile Manipulation via Adaptive Experience Selection and Dynamic Imagination
Jan 21, 2026Mobile Manipulation (MM) involves long-horizon decision-making over multi-stage compositions of heterogeneous skills, such as navigation and picking up objects. Despite recent progress, existing MM methods still face two key limitations: (i) low sample efficiency, due to ineffective use of redundant data generated during long-term MM interactions; and (ii) poor spatial generalization, as policies trained on specific tasks struggle to transfer to new spatial layouts without additional training. In this paper, we address these challenges through Adaptive Experience Selection (AES) and model-based dynamic imagination. In particular, AES makes MM agents pay more attention to critical experience fragments in long trajectories that affect task success, improving skill chain learning and mitigating skill forgetting. Based on AES, a Recurrent State-Space Model (RSSM) is introduced for Model-Predictive Forward Planning (MPFP) by capturing the coupled dynamics between the mobile base and the manipulator and imagining the dynamics of future manipulations. RSSM-based MPFP can reinforce MM skill learning on the current task while enabling effective generalization to new spatial layouts. Comparative studies across different experimental configurations demonstrate that our method significantly outperforms existing MM policies. Real-world experiments further validate the feasibility and practicality of our method.
DisCo-FLoc: Using Dual-Level Visual-Geometric Contrasts to Disambiguate Depth-Aware Visual Floorplan Localization
Jan 05, 2026Since floorplan data is readily available, long-term persistent, and robust to changes in visual appearance, visual Floorplan Localization (FLoc) has garnered significant attention. Existing methods either ingeniously match geometric priors or utilize sparse semantics to reduce FLoc uncertainty. However, they still suffer from ambiguous FLoc caused by repetitive structures within minimalist floorplans. Moreover, expensive but limited semantic annotations restrict their applicability. To address these issues, we propose DisCo-FLoc, which utilizes dual-level visual-geometric Contrasts to Disambiguate depth-aware visual Floc, without requiring additional semantic labels. Our solution begins with a ray regression predictor tailored for ray-casting-based FLoc, predicting a series of FLoc candidates using depth estimation expertise. In addition, a novel contrastive learning method with position-level and orientation-level constraints is proposed to strictly match depth-aware visual features with the corresponding geometric structures in the floorplan. Such matches can effectively eliminate FLoc ambiguity and select the optimal imaging pose from FLoc candidates. Exhaustive comparative studies on two standard visual Floc benchmarks demonstrate that our method outperforms the state-of-the-art semantic-based method, achieving significant improvements in both robustness and accuracy.
CogMCTS: A Novel Cognitive-Guided Monte Carlo Tree Search Framework for Iterative Heuristic Evolution with Large Language Models
Dec 11, 2025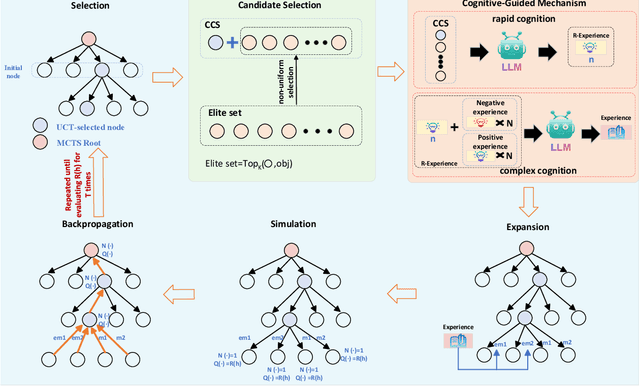
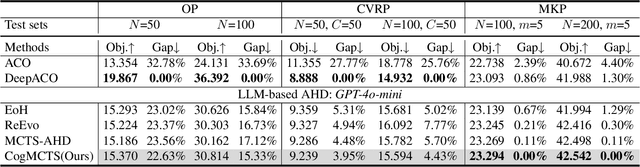
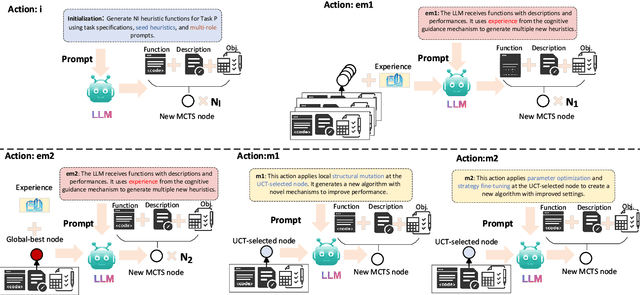
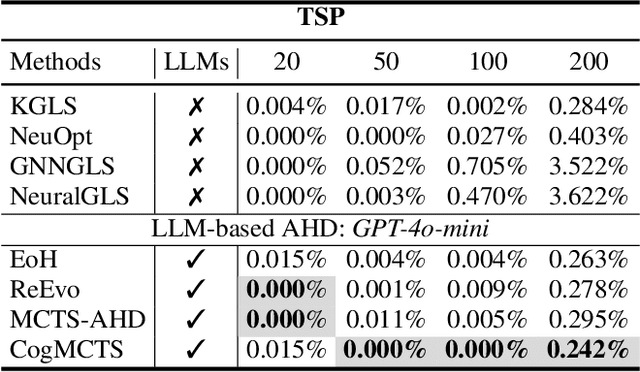
Automatic Heuristic Design (AHD) is an effective framework for solving complex optimization problems. The development of large language models (LLMs) enables the automated generation of heuristics. Existing LLM-based evolutionary methods rely on population strategies and are prone to local optima. Integrating LLMs with Monte Carlo Tree Search (MCTS) improves the trade-off between exploration and exploitation, but multi-round cognitive integration remains limited and search diversity is constrained. To overcome these limitations, this paper proposes a novel cognitive-guided MCTS framework (CogMCTS). CogMCTS tightly integrates the cognitive guidance mechanism of LLMs with MCTS to achieve efficient automated heuristic optimization. The framework employs multi-round cognitive feedback to incorporate historical experience, node information, and negative outcomes, dynamically improving heuristic generation. Dual-track node expansion combined with elite heuristic management balances the exploration of diverse heuristics and the exploitation of high-quality experience. In addition, strategic mutation modifies the heuristic forms and parameters to further enhance the diversity of the solution and the overall optimization performance. The experimental results indicate that CogMCTS outperforms existing LLM-based AHD methods in stability, efficiency, and solution quality.
MMWOZ: Building Multimodal Agent for Task-oriented Dialogue
Nov 16, 2025Task-oriented dialogue systems have garnered significant attention due to their conversational ability to accomplish goals, such as booking airline tickets for users. Traditionally, task-oriented dialogue systems are conceptualized as intelligent agents that interact with users using natural language and have access to customized back-end APIs. However, in real-world scenarios, the widespread presence of front-end Graphical User Interfaces (GUIs) and the absence of customized back-end APIs create a significant gap for traditional task-oriented dialogue systems in practical applications. In this paper, to bridge the gap, we collect MMWOZ, a new multimodal dialogue dataset that is extended from MultiWOZ 2.3 dataset. Specifically, we begin by developing a web-style GUI to serve as the front-end. Next, we devise an automated script to convert the dialogue states and system actions from the original dataset into operation instructions for the GUI. Lastly, we collect snapshots of the web pages along with their corresponding operation instructions. In addition, we propose a novel multimodal model called MATE (Multimodal Agent for Task-oriEnted dialogue) as the baseline model for the MMWOZ dataset. Furthermore, we conduct comprehensive experimental analysis using MATE to investigate the construction of a practical multimodal agent for task-oriented dialogue.
Planning of Heuristics: Strategic Planning on Large Language Models with Monte Carlo Tree Search for Automating Heuristic Optimization
Feb 17, 2025Heuristics have achieved great success in solving combinatorial optimization problems (COPs). However, heuristics designed by humans require too much domain knowledge and testing time. Given the fact that Large Language Models (LLMs) possess strong capabilities to understand and generate content, and a knowledge base that covers various domains, which offer a novel way to automatically optimize heuristics. Therefore, we propose Planning of Heuristics (PoH), an optimization method that integrates the self-reflection of LLMs with the Monte Carlo Tree Search (MCTS), a well-known planning algorithm. PoH iteratively refines generated heuristics by evaluating their performance and providing improvement suggestions. Our method enables to iteratively evaluate the generated heuristics (states) and improve them based on the improvement suggestions (actions) and evaluation results (rewards), by effectively simulating future states to search for paths with higher rewards. In this paper, we apply PoH to solve the Traveling Salesman Problem (TSP) and the Flow Shop Scheduling Problem (FSSP). The experimental results show that PoH outperforms other hand-crafted heuristics and Automatic Heuristic Design (AHD) by other LLMs-based methods, and achieves the significant improvements and the state-of-the-art performance of our proposed method in automating heuristic optimization with LLMs to solve COPs.
Reducing Action Space for Deep Reinforcement Learning via Causal Effect Estimation
Jan 24, 2025Intelligent decision-making within large and redundant action spaces remains challenging in deep reinforcement learning. Considering similar but ineffective actions at each step can lead to repetitive and unproductive trials. Existing methods attempt to improve agent exploration by reducing or penalizing redundant actions, yet they fail to provide quantitative and reliable evidence to determine redundancy. In this paper, we propose a method to improve exploration efficiency by estimating the causal effects of actions. Unlike prior methods, our approach offers quantitative results regarding the causality of actions for one-step transitions. We first pre-train an inverse dynamics model to serve as prior knowledge of the environment. Subsequently, we classify actions across the entire action space at each time step and estimate the causal effect of each action to suppress redundant actions during exploration. We provide a theoretical analysis to demonstrate the effectiveness of our method and present empirical results from simulations in environments with redundant actions to evaluate its performance. Our implementation is available at https://github.com/agi-brain/cee.git.
XuanCe: A Comprehensive and Unified Deep Reinforcement Learning Library
Dec 25, 2023In this paper, we present XuanCe, a comprehensive and unified deep reinforcement learning (DRL) library designed to be compatible with PyTorch, TensorFlow, and MindSpore. XuanCe offers a wide range of functionalities, including over 40 classical DRL and multi-agent DRL algorithms, with the flexibility to easily incorporate new algorithms and environments. It is a versatile DRL library that supports CPU, GPU, and Ascend, and can be executed on various operating systems such as Ubuntu, Windows, MacOS, and EulerOS. Extensive benchmarks conducted on popular environments including MuJoCo, Atari, and StarCraftII multi-agent challenge demonstrate the library's impressive performance. XuanCe is open-source and can be accessed at https://github.com/agi-brain/xuance.git.