 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALPBench: A Benchmark for Attribution-level Long-term Personal Behavior Understanding
Feb 03, 2026Recent advances in large language models have highlighted their potential for personalized recommendation, where accurately capturing user preferences remains a key challenge. Leveraging their strong reasoning and generalization capabilities, LLMs offer new opportunities for modeling long-term user behavior. To systematically evaluate this, we introduce ALPBench, a Benchmark for Attribution-level Long-term Personal Behavior Understanding. Unlike item-focused benchmarks, ALPBench predicts user-interested attribute combinations, enabling ground-truth evaluation even for newly introduced items. It models preferences from long-term historical behaviors rather than users' explicitly expressed requests, better reflecting enduring interests. User histories are represented as natural language sequences, allowing interpretable, reasoning-based personalization. ALPBench enables fine-grained evaluation of personalization by focusing on the prediction of attribute combinations task that remains highly challenging for current LLMs due to the need to capture complex interactions among multiple attributes and reason over long-term user behavior sequences.
OpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
NF-MKV Net: A Constraint-Preserving Neural Network Approach to Solving Mean-Field Games Equilibrium
Jan 29, 2025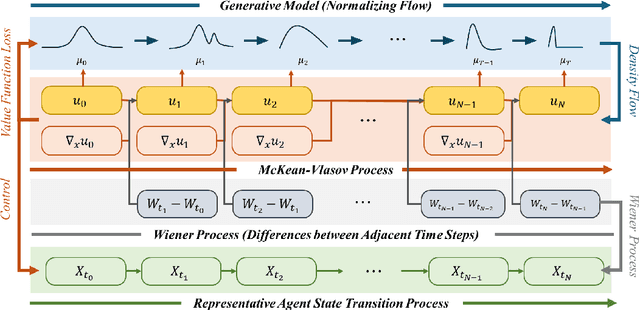
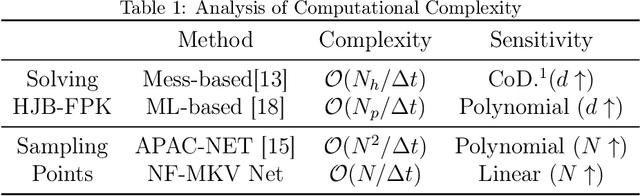
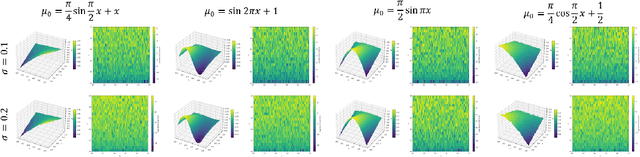
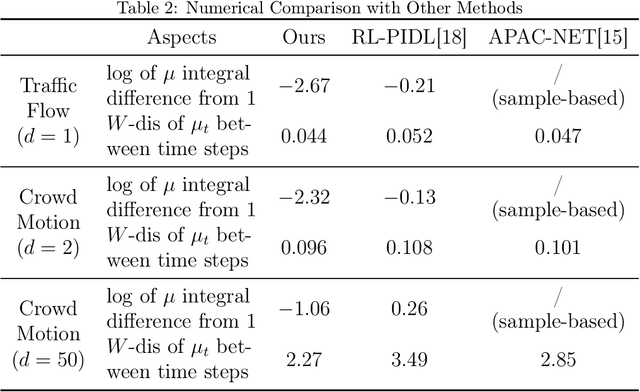
Neural network-based methods for solving Mean-Field Games (MFGs) equilibria have garnered significant attention for their effectiveness in high-dimensional problems. However, many algorithms struggle with ensuring that the evolution of the density distribution adheres to the required mathematical constraints. This paper investigates a neural network approach to solving MFGs equilibria through a stochastic process perspective. It integrates process-regularized Normalizing Flow (NF) frameworks with state-policy-connected time-series neural networks to address McKean-Vlasov-type Forward-Backward Stochastic Differential Equation (MKV FBSDE) fixed-point problems, equivalent to MFGs equilibria.
Reducing Action Space for Deep Reinforcement Learning via Causal Effect Estimation
Jan 24, 2025Intelligent decision-making within large and redundant action spaces remains challenging in deep reinforcement learning. Considering similar but ineffective actions at each step can lead to repetitive and unproductive trials. Existing methods attempt to improve agent exploration by reducing or penalizing redundant actions, yet they fail to provide quantitative and reliable evidence to determine redundancy. In this paper, we propose a method to improve exploration efficiency by estimating the causal effects of actions. Unlike prior methods, our approach offers quantitative results regarding the causality of actions for one-step transitions. We first pre-train an inverse dynamics model to serve as prior knowledge of the environment. Subsequently, we classify actions across the entire action space at each time step and estimate the causal effect of each action to suppress redundant actions during exploration. We provide a theoretical analysis to demonstrate the effectiveness of our method and present empirical results from simulations in environments with redundant actions to evaluate its performance. Our implementation is available at https://github.com/agi-brain/cee.git.
Enhance Hyperbolic Representation Learning via Second-order Pooling
Oct 29, 2024



Hyperbolic representation learning is well known for its ability to capture hierarchical information. However, the distance between samples from different levels of hierarchical classes can be required large. We reveal that the hyperbolic discriminant objective forces the backbone to capture this hierarchical information, which may inevitably increase the Lipschitz constant of the backbone. This can hinder the full utilization of the backbone's generalization ability. To address this issue, we introduce second-order pooling into hyperbolic representation learning, as it naturally increases the distance between samples without compromising the generalization ability of the input features. In this way, the Lipschitz constant of the backbone does not necessarily need to be large. However, current off-the-shelf low-dimensional bilinear pooling methods cannot be directly employed in hyperbolic representation learning because they inevitably reduce the distance expansion capability. To solve this problem, we propose a kernel approximation regularization, which enables the low-dimensional bilinear features to approximate the kernel function well in low-dimensional space. Finally, we conduct extensive experiments on graph-structured datasets to demonstrate the effectiveness of the proposed method.
DmADs-Net: Dense multiscale attention and depth-supervised network for medical image segmentation
May 01, 2024Deep learning has made important contributions to the development of medical image segmentation. Convolutional neural networks, as a crucial branch, have attracted strong attention from researchers. Through the tireless efforts of numerous researchers, convolutional neural networks have yielded numerous outstanding algorithms for processing medical images. The ideas and architectures of these algorithms have also provided important inspiration for the development of later technologies.Through extensive experimentation, we have found that currently mainstream deep learning algorithms are not always able to achieve ideal results when processing complex datasets and different types of datasets. These networks still have room for improvement in lesion localization and feature extraction. Therefore, we have created the Dense Multiscale Attention and Depth-Supervised Network (DmADs-Net).We use ResNet for feature extraction at different depths and create a Multi-scale Convolutional Feature Attention Block to improve the network's attention to weak feature information. The Local Feature Attention Block is created to enable enhanced local feature attention for high-level semantic information. In addition, in the feature fusion phase, a Feature Refinement and Fusion Block is created to enhance the fusion of different semantic information.We validated the performance of the network using five datasets of varying sizes and types. Results from comparative experiments show that DmADs-Net outperformed mainstream networks. Ablation experiments further demonstrated the effectiveness of the created modules and the rationality of the network architecture.
Leveraging Cross-Modal Neighbor Representation for Improved CLIP Classification
Apr 27, 2024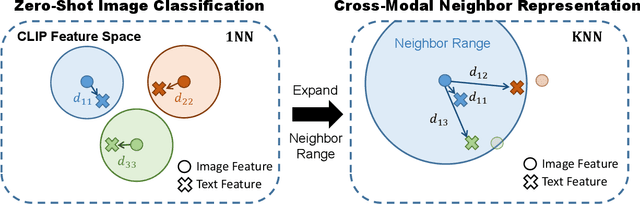
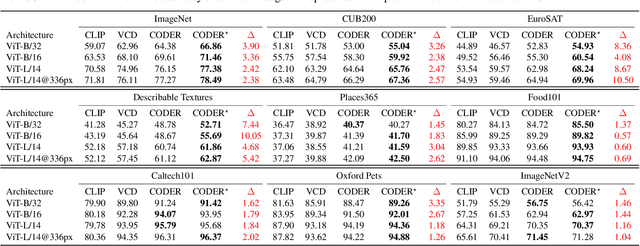

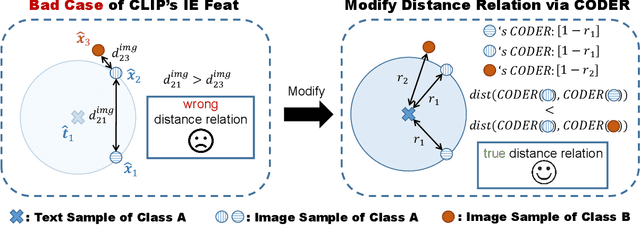
CLIP showcases exceptional cross-modal matching capabilities due to its training on image-text contrastive learning tasks. However, without specific optimization for unimodal scenarios, its performance in single-modality feature extraction might be suboptimal. Despite this, some studies have directly used CLIP's image encoder for tasks like few-shot classification, introducing a misalignment between its pre-training objectives and feature extraction methods. This inconsistency can diminish the quality of the image's feature representation, adversely affecting CLIP's effectiveness in target tasks. In this paper, we view text features as precise neighbors of image features in CLIP's space and present a novel CrOss-moDal nEighbor Representation(CODER) based on the distance structure between images and their neighbor texts. This feature extraction method aligns better with CLIP's pre-training objectives, thereby fully leveraging CLIP's robust cross-modal capabilities. The key to construct a high-quality CODER lies in how to create a vast amount of high-quality and diverse texts to match with images. We introduce the Auto Text Generator(ATG) to automatically generate the required texts in a data-free and training-free manner. We apply CODER to CLIP's zero-shot and few-shot image classification tasks. Experiment results across various datasets and models confirm CODER's effectiveness. Code is available at:https://github.com/YCaigogogo/CVPR24-CODER.
ZhiJian: A Unifying and Rapidly Deployable Toolbox for Pre-trained Model Reuse
Aug 17, 2023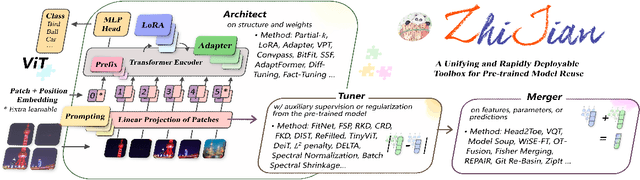
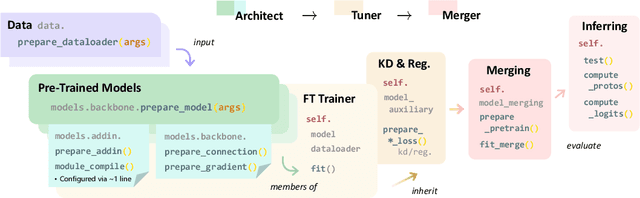
The rapid expansion of foundation pre-trained models and their fine-tuned counterparts has significantly contributed to the advancement of machine learning. Leveraging pre-trained models to extract knowledge and expedite learning in real-world tasks, known as "Model Reuse", has become crucial in various applications. Previous research focuses on reusing models within a certain aspect, including reusing model weights, structures, and hypothesis spaces. This paper introduces ZhiJian, a comprehensive and user-friendly toolbox for model reuse, utilizing the PyTorch backend. ZhiJian presents a novel paradigm that unifies diverse perspectives on model reuse, encompassing target architecture construction with PTM, tuning target model with PTM, and PTM-based inference. This empowers deep learning practitioners to explore downstream tasks and identify the complementary advantages among different methods. ZhiJian is readily accessible at https://github.com/zhangyikaii/lamda-zhijian facilitating seamless utilization of pre-trained models and streamlining the model reuse process for researchers and developers.