 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelet-Guided Dual-Frequency Encoding for Remote Sensing Change Detection
Aug 07, 2025Change detection in remote sensing imagery plays a vital role in various engineering applications, such as natural disaster monitoring, urban expansion tracking, and infrastructure management. Despite the remarkable progress of deep learning in recent years, most existing methods still rely on spatial-domain modeling, where the limited diversity of feature representations hinders the detection of subtle change regions. We observe that frequency-domain feature modeling particularly in the wavelet domain an amplify fine-grained differences in frequency components, enhancing the perception of edge changes that are challenging to capture in the spatial domain. Thus, we propose a method called Wavelet-Guided Dual-Frequency Encoding (WGDF). Specifically, we first apply Discrete Wavelet Transform (DWT) to decompose the input images into high-frequency and low-frequency components, which are used to model local details and global structures, respectively. In the high-frequency branch, we design a Dual-Frequency Feature Enhancement (DFFE) module to strengthen edge detail representation and introduce a Frequency-Domain Interactive Difference (FDID) module to enhance the modeling of fine-grained changes. In the low-frequency branch, we exploit Transformers to capture global semantic relationships and employ a Progressive Contextual Difference Module (PCDM) to progressively refine change regions, enabling precise structural semantic characterization. Finally, the high- and low-frequency features are synergistically fused to unify local sensitivity with global discriminability. Extensive experiments on multiple remote sensing datasets demonstrate that WGDF significantly alleviates edge ambiguity and achieves superior detection accuracy and robustness compared to state-of-the-art methods. The code will be available at https://github.com/boshizhang123/WGDF.
Prototype-Driven Structure Synergy Network for Remote Sensing Images Segmentation
Aug 06, 2025
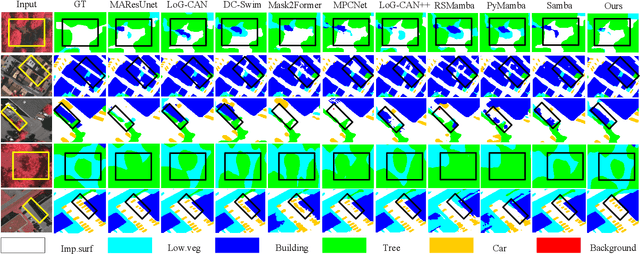
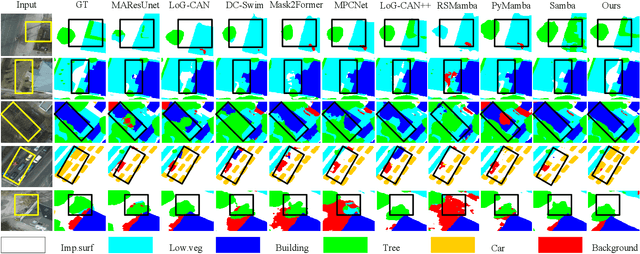
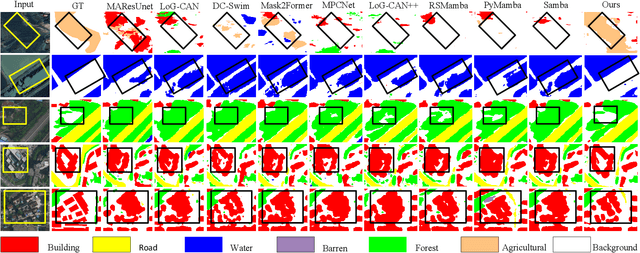
In the semantic segmentation of remote sensing images, acquiring complete ground objects is critical for achieving precise analysis. However, this task is severely hindered by two major challenges: high intra-class variance and high inter-class similarity. Traditional methods often yield incomplete segmentation results due to their inability to effectively unify class representations and distinguish between similar features. Even emerging class-guided approaches are limited by coarse class prototype representations and a neglect of target structural information. Therefore, this paper proposes a Prototype-Driven Structure Synergy Network (PDSSNet). The design of this network is based on a core concept, a complete ground object is jointly defined by its invariant class semantics and its variant spatial structure. To implement this, we have designed three key modules. First, the Adaptive Prototype Extraction Module (APEM) ensures semantic accuracy from the source by encoding the ground truth to extract unbiased class prototypes. Subsequently, the designed Semantic-Structure Coordination Module (SSCM) follows a hierarchical semantics-first, structure-second principle. This involves first establishing a global semantic cognition, then leveraging structural information to constrain and refine the semantic representation, thereby ensuring the integrity of class information. Finally, the Channel Similarity Adjustment Module (CSAM) employs a dynamic step-size adjustment mechanism to focus on discriminative features between classes. Extensive experiments demonstrate that PDSSNet outperforms state-of-the-art methods. The source code is available at https://github.com/wangjunyi-1/PDSSNet.
SFFNet: A Wavelet-Based Spatial and Frequency Domain Fusion Network for Remote Sensing Segmentation
May 03, 2024



In order to fully utilize spatial information for segmentation and address the challenge of handling areas with significant grayscale variations in remote sensing segmentation, we propose the SFFNet (Spatial and Frequency Domain Fusion Network) framework. This framework employs a two-stage network design: the first stage extracts features using spatial methods to obtain features with sufficient spatial details and semantic information; the second stage maps these features in both spatial and frequency domains. In the frequency domain mapping, we introduce the Wavelet Transform Feature Decomposer (WTFD) structure, which decomposes features into low-frequency and high-frequency components using the Haar wavelet transform and integrates them with spatial features. To bridge the semantic gap between frequency and spatial features, and facilitate significant feature selection to promote the combination of features from different representation domains, we design the Multiscale Dual-Representation Alignment Filter (MDAF). This structure utilizes multiscale convolutions and dual-cross attentions. Comprehensive experimental results demonstrate that, compared to existing methods, SFFNet achieves superior performance in terms of mIoU, reaching 84.80% and 87.73% respectively.The code is located at https://github.com/yysdck/SFFNet.
Underwater Variable Zoom: Depth-Guided Perception Network for Underwater Image Enhancement
May 02, 2024



Underwater scenes intrinsically involve degradation problems owing to heterogeneous ocean elements. Prevailing underwater image enhancement (UIE) methods stick to straightforward feature modeling to learn the mapping function, which leads to limited vision gain as it lacks more explicit physical cues (e.g., depth). In this work, we investigate injecting the depth prior into the deep UIE model for more precise scene enhancement capability. To this end, we present a novel depth-guided perception UIE framework, dubbed underwater variable zoom (UVZ). Specifically, UVZ resorts to a two-stage pipeline. First, a depth estimation network is designed to generate critical depth maps, combined with an auxiliary supervision network introduced to suppress estimation differences during training. Second, UVZ parses near-far scenarios by harnessing the predicted depth maps, enabling local and non-local perceiving in different regions. Extensive experiments on five benchmark datasets demonstrate that UVZ achieves superior visual gain and delivers promising quantitative metrics. Besides, UVZ is confirmed to exhibit good generalization in some visual tasks, especially in unusual lighting conditions. The code, models and results are available at: https://github.com/WindySprint/UVZ.
MFDS-Net: Multi-Scale Feature Depth-Supervised Network for Remote Sensing Change Detection with Global Semantic and Detail Information
May 02, 2024Change detection as an interdisciplinary discipline in the field of computer vision and remote sensing at present has been receiving extensive attention and research. Due to the rapid development of society, the geographic information captured by remote sensing satellites is changing faster and more complex, which undoubtedly poses a higher challenge and highlights the value of change detection tasks. We propose MFDS-Net: Multi-Scale Feature Depth-Supervised Network for Remote Sensing Change Detection with Global Semantic and Detail Information (MFDS-Net) with the aim of achieving a more refined description of changing buildings as well as geographic information, enhancing the localisation of changing targets and the acquisition of weak features. To achieve the research objectives, we use a modified ResNet_34 as backbone network to perform feature extraction and DO-Conv as an alternative to traditional convolution to better focus on the association between feature information and to obtain better training results. We propose the Global Semantic Enhancement Module (GSEM) to enhance the processing of high-level semantic information from a global perspective. The Differential Feature Integration Module (DFIM) is proposed to strengthen the fusion of different depth feature information, achieving learning and extraction of differential features. The entire network is trained and optimized using a deep supervision mechanism. The experimental outcomes of MFDS-Net surpass those of current mainstream change detection networks. On the LEVIR dataset, it achieved an F1 score of 91.589 and IoU of 84.483, on the WHU dataset, the scores were F1: 92.384 and IoU: 86.807, and on the GZ-CD dataset, the scores were F1: 86.377 and IoU: 76.021. The code is available at https://github.com/AOZAKIiii/MFDS-Net
DmADs-Net: Dense multiscale attention and depth-supervised network for medical image segmentation
May 01, 2024Deep learning has made important contributions to the development of medical image segmentation. Convolutional neural networks, as a crucial branch, have attracted strong attention from researchers. Through the tireless efforts of numerous researchers, convolutional neural networks have yielded numerous outstanding algorithms for processing medical images. The ideas and architectures of these algorithms have also provided important inspiration for the development of later technologies.Through extensive experimentation, we have found that currently mainstream deep learning algorithms are not always able to achieve ideal results when processing complex datasets and different types of datasets. These networks still have room for improvement in lesion localization and feature extraction. Therefore, we have created the Dense Multiscale Attention and Depth-Supervised Network (DmADs-Net).We use ResNet for feature extraction at different depths and create a Multi-scale Convolutional Feature Attention Block to improve the network's attention to weak feature information. The Local Feature Attention Block is created to enable enhanced local feature attention for high-level semantic information. In addition, in the feature fusion phase, a Feature Refinement and Fusion Block is created to enhance the fusion of different semantic information.We validated the performance of the network using five datasets of varying sizes and types. Results from comparative experiments show that DmADs-Net outperformed mainstream networks. Ablation experiments further demonstrated the effectiveness of the created modules and the rationality of the network architecture.