 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-contact Dexterous Micromanipulation with Multiple Optoelectronic Robots
Oct 30, 2024



Micromanipulation systems leverage automation and robotic technologies to improve the precision, repeatability, and efficiency of various tasks at the microscale. However, current approaches are typically limited to specific objects or tasks, which necessitates the use of custom tools and specialized grasping methods. This paper proposes a novel non-contact micromanipulation method based on optoelectronic technologies. The proposed method utilizes repulsive dielectrophoretic forces generated in the optoelectronic field to drive a microrobot, enabling the microrobot to push the target object in a cluttered environment without physical contact. The non-contact feature can minimize the risks of potential damage, contamination, or adhesion while largely improving the flexibility of manipulation. The feature enables the use of a general tool for indirect object manipulation, eliminating the need for specialized tools. A series of simulation studies and real-world experiments -- including non-contact trajectory tracking, obstacle avoidance, and reciprocal avoidance between multiple microrobots -- are conducted to validate the performance of the proposed method. The proposed formulation provides a general and dexterous solution for a range of objects and tasks at the micro scale.
GMSR:Gradient-Guided Mamba for Spectral Reconstruction from RGB Images
May 13, 2024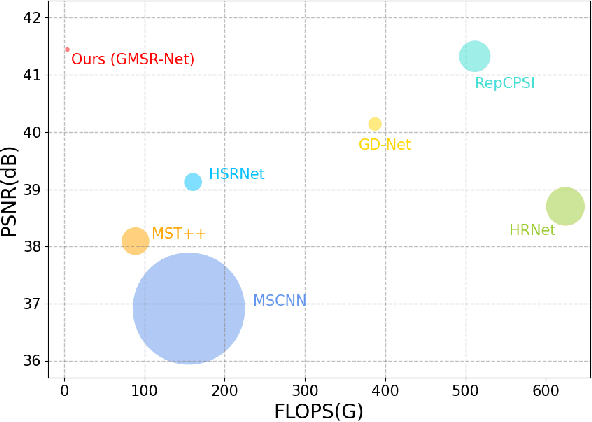
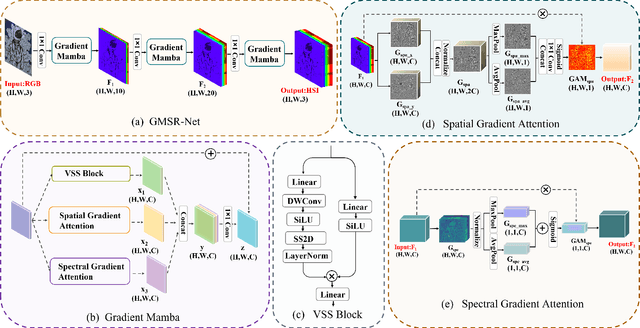
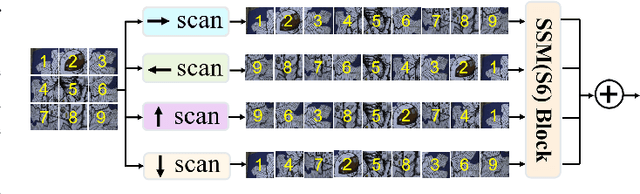

Mainstream approaches to spectral reconstruction (SR) primarily focus on designing Convolution- and Transformer-based architectures. However, CNN methods often face challenges in handling long-range dependencies, whereas Transformers are constrained by computational efficiency limitations. Recent breakthroughs in state-space model (e.g., Mamba) has attracted significant attention due to its near-linear computational efficiency and superior performance, prompting our investigation into its potential for SR problem. To this end, we propose the Gradient-guided Mamba for Spectral Reconstruction from RGB Images, dubbed GMSR-Net. GMSR-Net is a lightweight model characterized by a global receptive field and linear computational complexity. Its core comprises multiple stacked Gradient Mamba (GM) blocks, each featuring a tri-branch structure. In addition to benefiting from efficient global feature representation by Mamba block, we further innovatively introduce spatial gradient attention and spectral gradient attention to guide the reconstruction of spatial and spectral cues. GMSR-Net demonstrates a significant accuracy-efficiency trade-off, achieving state-of-the-art performance while markedly reducing the number of parameters and computational burdens. Compared to existing approaches, GMSR-Net slashes parameters and FLOPS by substantial margins of 10 times and 20 times, respectively. Code is available at https://github.com/wxy11-27/GMSR.
Underwater Variable Zoom: Depth-Guided Perception Network for Underwater Image Enhancement
May 02, 2024



Underwater scenes intrinsically involve degradation problems owing to heterogeneous ocean elements. Prevailing underwater image enhancement (UIE) methods stick to straightforward feature modeling to learn the mapping function, which leads to limited vision gain as it lacks more explicit physical cues (e.g., depth). In this work, we investigate injecting the depth prior into the deep UIE model for more precise scene enhancement capability. To this end, we present a novel depth-guided perception UIE framework, dubbed underwater variable zoom (UVZ). Specifically, UVZ resorts to a two-stage pipeline. First, a depth estimation network is designed to generate critical depth maps, combined with an auxiliary supervision network introduced to suppress estimation differences during training. Second, UVZ parses near-far scenarios by harnessing the predicted depth maps, enabling local and non-local perceiving in different regions. Extensive experiments on five benchmark datasets demonstrate that UVZ achieves superior visual gain and delivers promising quantitative metrics. Besides, UVZ is confirmed to exhibit good generalization in some visual tasks, especially in unusual lighting conditions. The code, models and results are available at: https://github.com/WindySprint/UVZ.
End-to-End Streaming Video Temporal Action Segmentation with Reinforce Learning
Sep 27, 2023Temporal Action Segmentation (TAS) from video is a kind of frame recognition task for long video with multiple action classes. As an video understanding task for long videos, current methods typically combine multi-modality action recognition models with temporal models to convert feature sequences to label sequences. This approach can only be applied to offline scenarios, which severely limits the TAS application. Therefore, this paper proposes an end-to-end Streaming Video Temporal Action Segmentation with Reinforce Learning (SVTAS-RL). The end-to-end SVTAS which regard TAS as an action segment clustering task can expand the application scenarios of TAS; and RL is used to alleviate the problem of inconsistent optimization objective and direction. Through extensive experiments, the SVTAS-RL model achieves a competitive performance to the state-of-the-art model of TAS on multiple datasets, and shows greater advantages on the ultra-long video dataset EGTEA. This indicates that our method can replace all current TAS models end-to-end and SVTAS-RL is more suitable for long video TAS. Code is availabel at https://github.com/Thinksky5124/SVTAS.
Artificial Intelligence Security Competition (AISC)
Dec 07, 2022



The security of artificial intelligence (AI) is an important research area towards safe, reliable, and trustworthy AI systems. To accelerate the research on AI security, the Artificial Intelligence Security Competition (AISC) was organized by the Zhongguancun Laboratory, China Industrial Control Systems Cyber Emergency Response Team, Institute for Artificial Intelligence, Tsinghua University, and RealAI as part of the Zhongguancun International Frontier Technology Innovation Competition (https://www.zgc-aisc.com/en). The competition consists of three tracks, including Deepfake Security Competition, Autonomous Driving Security Competition, and Face Recognition Security Competition. This report will introduce the competition rules of these three tracks and the solutions of top-ranking teams in each track.
Streaming Video Temporal Action Segmentation In Real Time
Sep 28, 2022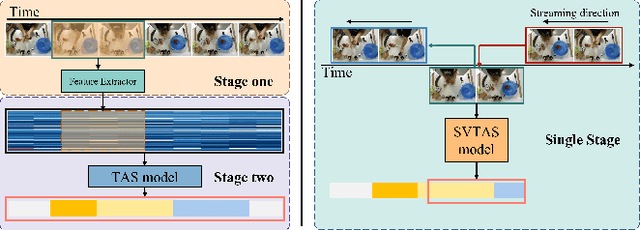
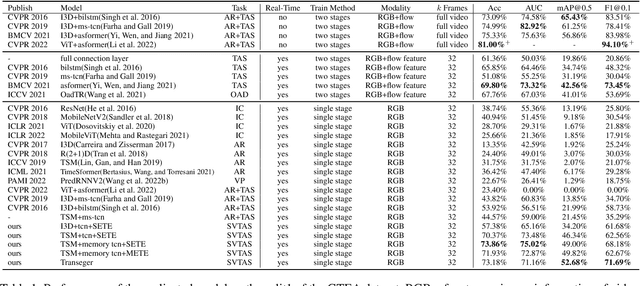
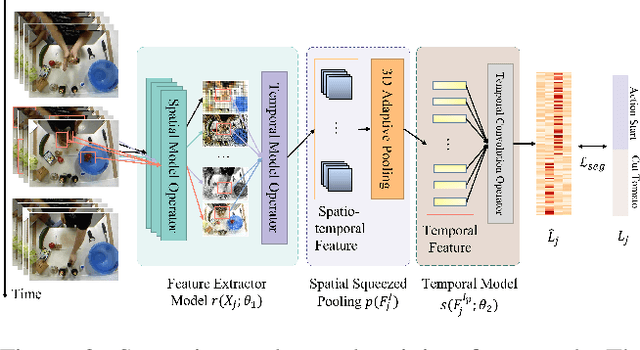
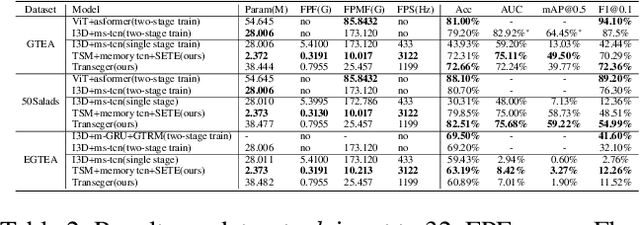
Temporal action segmentation (TAS) is a critical step toward long-term video understanding. Recent studies follow a pattern that builds models based on features instead of raw video picture information. However, we claim those models are trained complicatedly and limit application scenarios. It is hard for them to segment human actions of video in real time because they must work after the full video features are extracted. As the real-time action segmentation task is different from TAS task, we define it as streaming video real-time temporal action segmentation (SVTAS) task. In this paper, we propose a real-time end-to-end multi-modality model for SVTAS task. More specifically, under the circumstances that we cannot get any future information, we segment the current human action of streaming video chunk in real time. Furthermore, the model we propose combines the last steaming video chunk feature extracted by language model with the current image feature extracted by image model to improve the quantity of real-time temporal action segmentation. To the best of our knowledge, it is the first multi-modality real-time temporal action segmentation model. Under the same evaluation criteria as full video temporal action segmentation, our model segments human action in real time with less than 40% of state-of-the-art model computation and achieves 90% of the accuracy of the full video state-of-the-art model.
A unified framework based on graph consensus term for multi-view learning
May 25, 2021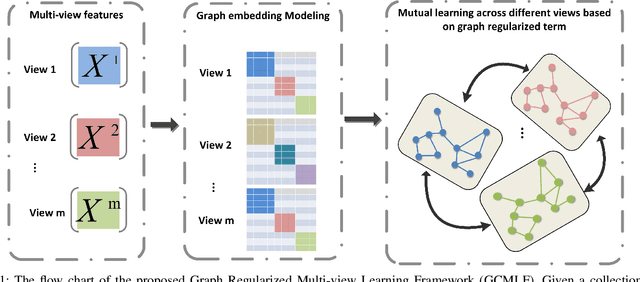
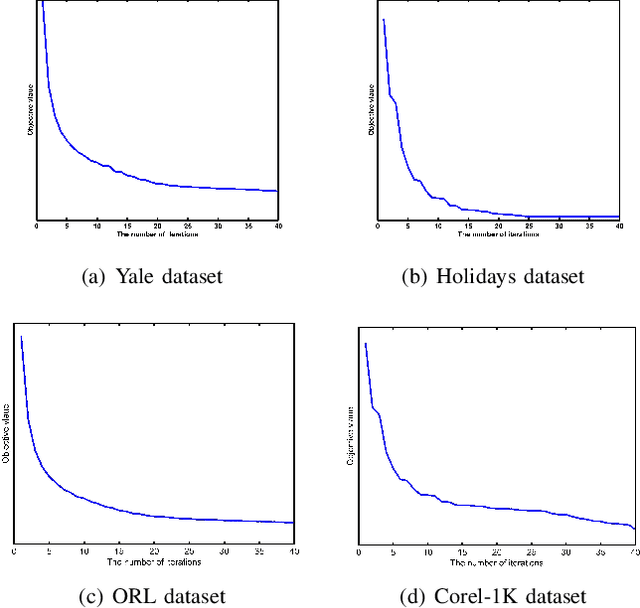

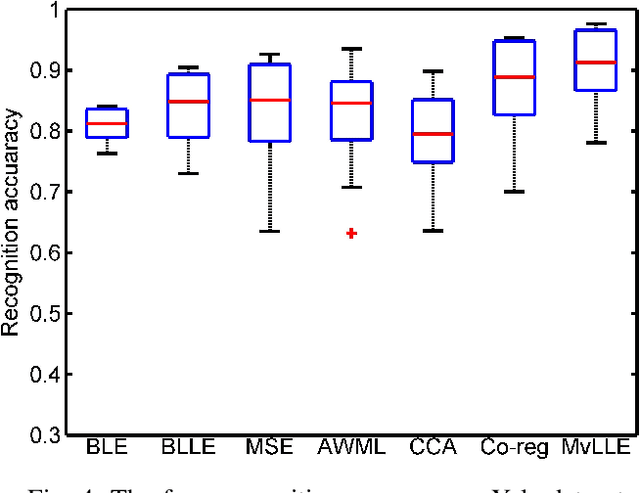
In recent years, multi-view learning technologies for various applications have attracted a surge of interest. Due to more compatible and complementary information from multiple views, existing multi-view methods could achieve more promising performance than conventional single-view methods in most situations. However, there are still no sufficient researches on the unified framework in existing multi-view works. Meanwhile, how to efficiently integrate multi-view information is still full of challenges. In this paper, we propose a novel multi-view learning framework, which aims to leverage most existing graph embedding works into a unified formula via introducing the graph consensus term. In particular, our method explores the graph structure in each view independently to preserve the diversity property of graph embedding methods. Meanwhile, we choose heterogeneous graphs to construct the graph consensus term to explore the correlations among multiple views jointly. To this end, the diversity and complementary information among different views could be simultaneously considered. Furthermore, the proposed framework is utilized to implement the multi-view extension of Locality Linear Embedding, named Multi-view Locality Linear Embedding (MvLLE), which could be efficiently solved by applying the alternating optimization strategy. Empirical validations conducted on six benchmark datasets can show the effectiveness of our proposed method.
Self-Supervised Deep Graph Embedding with High-Order Information Fusion for Community Discovery
Feb 08, 2021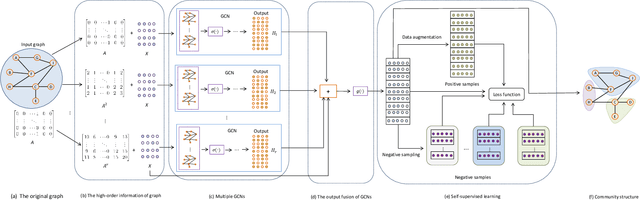
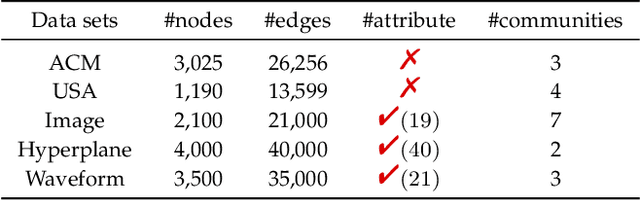

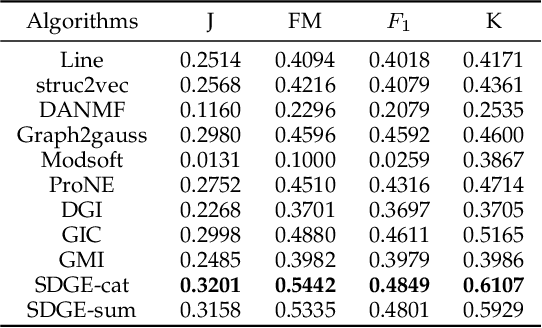
Deep graph embedding is an important approach for community discovery. Deep graph neural network with self-supervised mechanism can obtain the low-dimensional embedding vectors of nodes from unlabeled and unstructured graph data. The high-order information of graph can provide more abundant structure information for the representation learning of nodes. However, most self-supervised graph neural networks only use adjacency matrix as the input topology information of graph and cannot obtain too high-order information since the number of layers of graph neural network is fairly limited. If there are too many layers, the phenomenon of over smoothing will appear. Therefore how to obtain and fuse high-order information of graph by a shallow graph neural network is an important problem. In this paper, a deep graph embedding algorithm with self-supervised mechanism for community discovery is proposed. The proposed algorithm uses self-supervised mechanism and different high-order information of graph to train multiple deep graph convolution neural networks. The outputs of multiple graph convolution neural networks are fused to extract the representations of nodes which include the attribute and structure information of a graph. In addition, data augmentation and negative sampling are introduced into the training process to facilitate the improvement of embedding result. The proposed algorithm and the comparison algorithms are conducted on the five experimental data sets. The experimental results show that the proposed algorithm outperforms the comparison algorithms on the most experimental data sets. The experimental results demonstrate that the proposed algorithm is an effective algorithm for community discovery.
Multimodal-Aware Weakly Supervised Metric Learning with Self-weighting Triplet Loss
Feb 03, 2021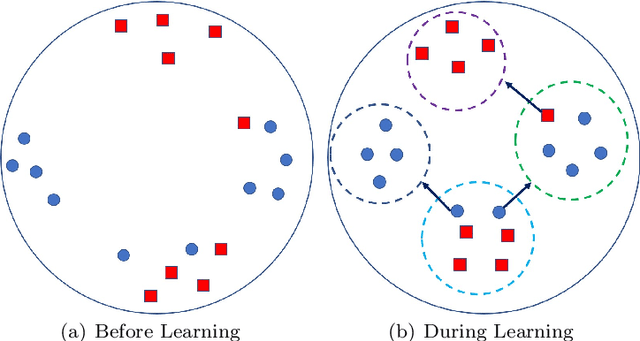

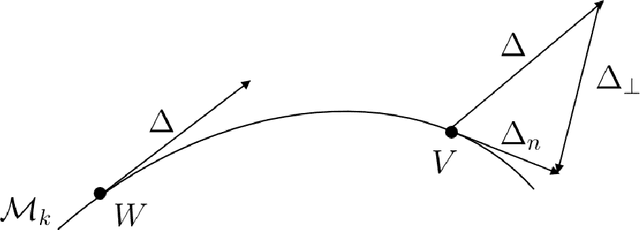
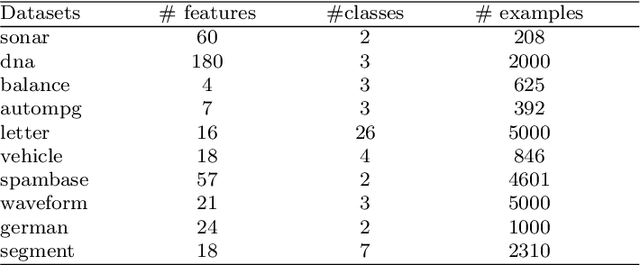
In recent years, we have witnessed a surge of interests in learning a suitable distance metric from weakly supervised data. Most existing methods aim to pull all the similar samples closer while push the dissimilar ones as far as possible. However, when some classes of the dataset exhibit multimodal distribution, these goals conflict and thus can hardly be concurrently satisfied. Additionally, to ensure a valid metric, many methods require a repeated eigenvalue decomposition process, which is expensive and numerically unstable. Therefore, how to learn an appropriate distance metric from weakly supervised data remains an open but challenging problem. To address this issue, in this paper, we propose a novel weakly supervised metric learning algorithm, named MultimoDal Aware weakly supervised Metric Learning (MDaML). MDaML partitions the data space into several clusters and allocates the local cluster centers and weight for each sample. Then, combining it with the weighted triplet loss can further enhance the local separability, which encourages the local dissimilar samples to keep a large distance from the local similar samples. Meanwhile, MDaML casts the metric learning problem into an unconstrained optimization on the SPD manifold, which can be efficiently solved by Riemannian Conjugate Gradient Descent (RCGD). Extensive experiments conducted on 13 datasets validate the superiority of the proposed MDaML.
Multi-view Low-rank Preserving Embedding: A Novel Method for Multi-view Representation
Jun 14, 2020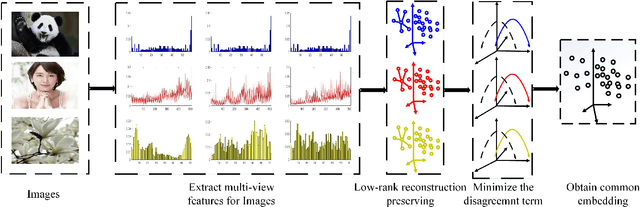
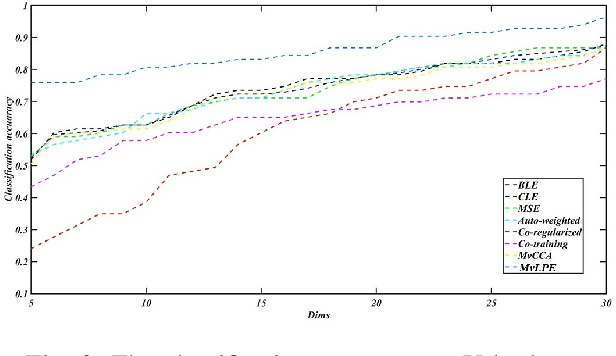
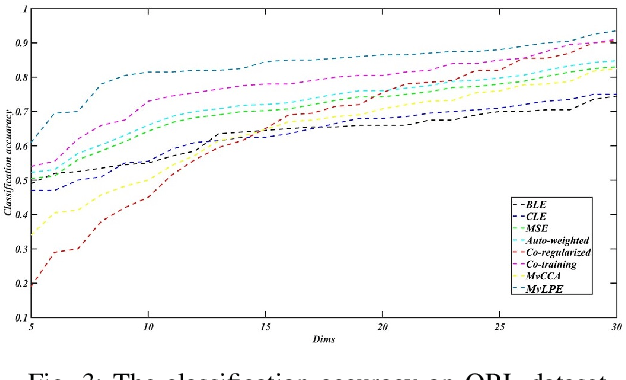
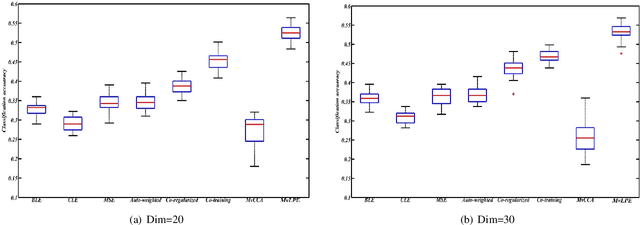
In recent years, we have witnessed a surge of interest in multi-view representation learning, which is concerned with the problem of learning representations of multi-view data. When facing multiple views that are highly related but sightly different from each other, most of existing multi-view methods might fail to fully integrate multi-view information. Besides, correlations between features from multiple views always vary seriously, which makes multi-view representation challenging. Therefore, how to learn appropriate embedding from multi-view information is still an open problem but challenging. To handle this issue, this paper proposes a novel multi-view learning method, named Multi-view Low-rank Preserving Embedding (MvLPE). It integrates different views into one centroid view by minimizing the disagreement term, based on distance or similarity matrix among instances, between the centroid view and each view meanwhile maintaining low-rank reconstruction relations among samples for each view, which could make more full use of compatible and complementary information from multi-view features. Unlike existing methods with additive parameters, the proposed method could automatically allocate a suitable weight for each view in multi-view information fusion. However, MvLPE couldn't be directly solved, which makes the proposed MvLPE difficult to obtain an analytic solution. To this end, we approximate this solution based on stationary hypothesis and normalization post-processing to efficiently obtain the optimal solution. Furthermore, an iterative alternating strategy is provided to solve this multi-view representation problem. The experiments on six benchmark datasets demonstrate that the proposed method outperforms its counterparts while achieving very competitive performance.