 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactSim-Bench: Benchmarking Reactive Behavior World Model Simulation in Autonomous Driving
Jun 12, 2026Reactive capability is a key property of data-driven behavior world model simulators for autonomous driving simulation systems. With this capability, simulated world agents can respond feasibly to autonomous vehicle (AV) behaviors that differ from the log. However, existing behavior simulation benchmarks do not directly measure reactive capability. They often let the simulator jointly control the AV and surrounding agents and evaluate realism through log similarity or open-loop prediction metrics. In this work, we introduce ReactSim-Bench for evaluating the reactive capability of behavior world model simulation in autonomous driving. We decouple the control of agents and the AV, using AV behaviors that differ from the log and require agents to respond as independent AV inputs. To obtain these AV behaviors, we construct a pipeline that uses an AV planner model to generate candidate behaviors and filters the data using rules and manual verification. Collision metrics, map-based metrics, and kinematic feasibility metrics are used to evaluate the safety and rule compliance of reactive responses. We construct 2,636 test scenarios with three categories and conduct a systematic evaluation of state-of-the-art models across multiple architectures, including Transformer-based, diffusion-based, and next-token-prediction-based models. We further analyze how replan frequency affects performance and provide insights for future studies.
GuidedVLA: Specifying Task-Relevant Factors via Plug-and-Play Action Attention Specialization
May 12, 2026Vision-Language-Action (VLA) models aim for general robot learning by aligning action as a modality within powerful Vision-Language Models (VLMs). Existing VLAs rely on end-to-end supervision to implicitly enable the action decoding process to learn task-relevant features. However, without explicit guidance, these models often overfit to spurious correlations, such as visual shortcuts or environmental noise, limiting their generalization. In this paper, we introduce GuidedVLA, a framework designed to manually guide the action generation to focus on task-relevant factors. Our core insight is to treat the action decoder not as a monolithic learner, but as an assembly of functional components. Individual attention heads are supervised by manually defined auxiliary signals to capture distinct factors. As an initial study, we instantiate this paradigm with three specialized heads: object grounding, spatial geometry, and temporal skill logic. Across simulation and real-robot experiments, GuidedVLA improves success rates in both in-domain and out-of-domain settings compared to strong VLA baselines. Finally, we show that the quality of these specialized factors correlates positively with task performance and that our mechanism yields decoupled, high-quality features. Our results suggest that explicitly guiding action-decoder learning is a promising direction for building more robust and general VLA models.
Bench2Drive-VL: Benchmarks for Closed-Loop Autonomous Driving with Vision-Language Models
Apr 01, 2026With the rise of vision-language models (VLM), their application for autonomous driving (VLM4AD) has gained significant attention. Meanwhile, in autonomous driving, closed-loop evaluation has become widely recognized as a more reliable validation method than open-loop evaluation, as it can evaluate the performance of the model under cumulative errors and out-of-distribution inputs. However, existing VLM4AD benchmarks evaluate the model`s scene understanding ability under open-loop, i.e., via static question-answer (QA) dataset. This kind of evaluation fails to assess the VLMs performance under out-of-distribution states rarely appeared in the human collected datasets.To this end, we present Bench2Drive-VL, an extension of Bench2Drive that brings closed-loop evaluation to VLM-based driving, which introduces: (1) DriveCommenter, a closed-loop generator that automatically generates diverse, behavior-grounded question-answer pairs for all driving situations in CARLA,including severe off-route and off-road deviations previously unassessable in simulation. (2) A unified protocol and interface that allows modern VLMs to be directly plugged into the Bench2Drive closed-loop environment to compare with traditional agents. (3) A flexible reasoning and control framework, supporting multi-format visual inputs and configurable graph-based chain-of-thought execution. (4) A complete development ecosystem. Together, these components form a comprehensive closed-loop benchmark for VLM4AD. All codes and annotated datasets are open sourced.
Raw2Drive: Reinforcement Learning with Aligned World Models for End-to-End Autonomous Driving (in CARLA v2)
May 22, 2025Reinforcement Learning (RL) can mitigate the causal confusion and distribution shift inherent to imitation learning (IL). However, applying RL to end-to-end autonomous driving (E2E-AD) remains an open problem for its training difficulty, and IL is still the mainstream paradigm in both academia and industry. Recently Model-based Reinforcement Learning (MBRL) have demonstrated promising results in neural planning; however, these methods typically require privileged information as input rather than raw sensor data. We fill this gap by designing Raw2Drive, a dual-stream MBRL approach. Initially, we efficiently train an auxiliary privileged world model paired with a neural planner that uses privileged information as input. Subsequently, we introduce a raw sensor world model trained via our proposed Guidance Mechanism, which ensures consistency between the raw sensor world model and the privileged world model during rollouts. Finally, the raw sensor world model combines the prior knowledge embedded in the heads of the privileged world model to effectively guide the training of the raw sensor policy. Raw2Drive is so far the only RL based end-to-end method on CARLA Leaderboard 2.0, and Bench2Drive and it achieves state-of-the-art performance.
DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
May 22, 2025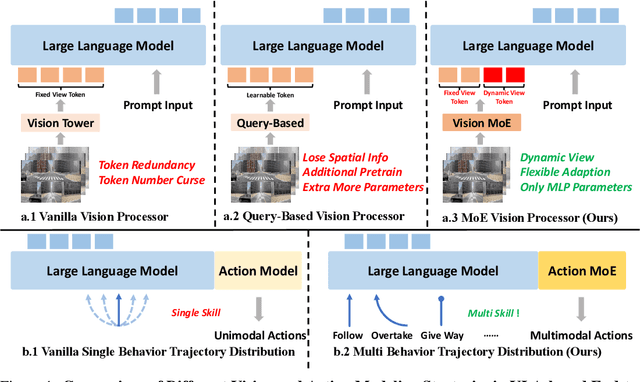
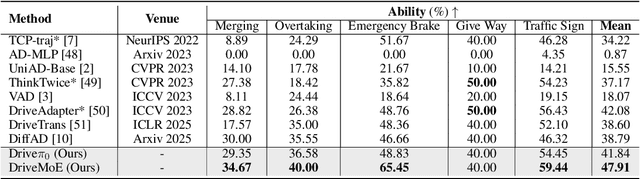
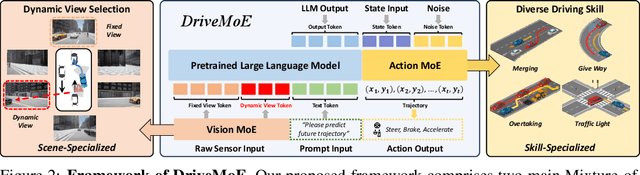
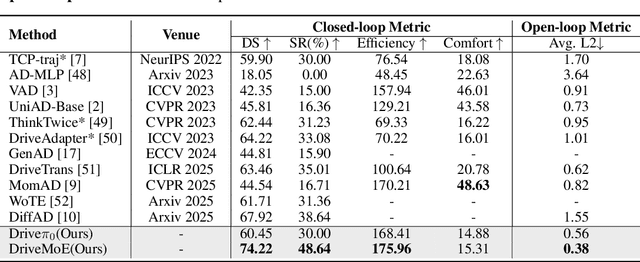
End-to-end autonomous driving (E2E-AD) demands effective processing of multi-view sensory data and robust handling of diverse and complex driving scenarios, particularly rare maneuvers such as aggressive turns. Recent success of Mixture-of-Experts (MoE) architecture in Large Language Models (LLMs) demonstrates that specialization of parameters enables strong scalability. In this work, we propose DriveMoE, a novel MoE-based E2E-AD framework, with a Scene-Specialized Vision MoE and a Skill-Specialized Action MoE. DriveMoE is built upon our $\pi_0$ Vision-Language-Action (VLA) baseline (originally from the embodied AI field), called Drive-$\pi_0$. Specifically, we add Vision MoE to Drive-$\pi_0$ by training a router to select relevant cameras according to the driving context dynamically. This design mirrors human driving cognition, where drivers selectively attend to crucial visual cues rather than exhaustively processing all visual information. In addition, we add Action MoE by training another router to activate specialized expert modules for different driving behaviors. Through explicit behavioral specialization, DriveMoE is able to handle diverse scenarios without suffering from modes averaging like existing models. In Bench2Drive closed-loop evaluation experiments, DriveMoE achieves state-of-the-art (SOTA) performance, demonstrating the effectiveness of combining vision and action MoE in autonomous driving tasks. We will release our code and models of DriveMoE and Drive-$\pi_0$.
Automatically Planning Optimal Parallel Strategy for Large Language Models
Dec 31, 2024



The number of parameters in large-scale language models based on transformers is gradually increasing, and the scale of computing clusters is also growing. The technology of quickly mobilizing large amounts of computing resources for parallel computing is becoming increasingly important. In this paper, we propose an automatic parallel algorithm that automatically plans the parallel strategy with maximum throughput based on model and hardware information. By decoupling the training time into computation, communication, and overlap, we established a training duration simulation model. Based on this simulation model, we prune the parallel solution space to shorten the search time required. The multi-node experiment results show that the algorithm can estimate the parallel training duration in real time with an average accuracy of 96%. In our test, the recommendation strategy provided by the algorithm is always globally optimal.
An Unsupervised Dialogue Topic Segmentation Model Based on Utterance Rewriting
Sep 12, 2024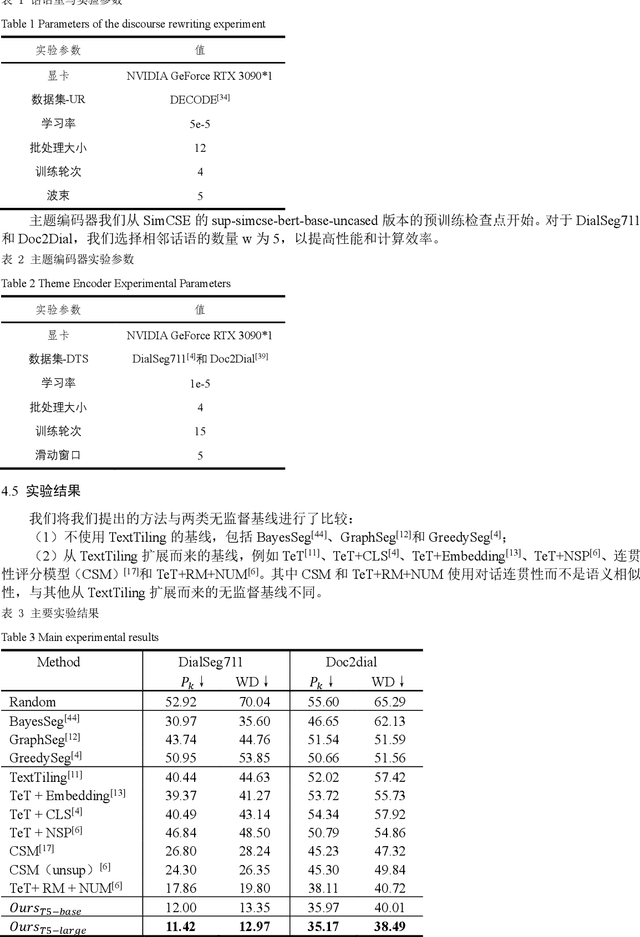
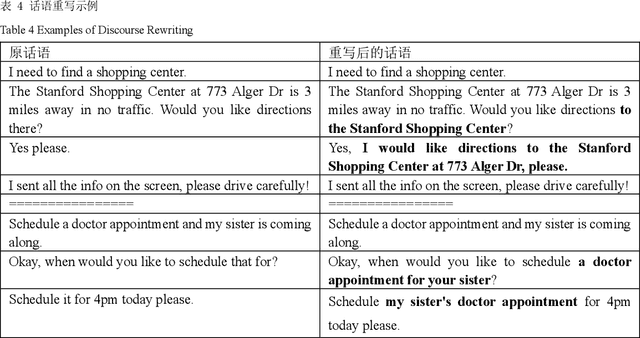
Dialogue topic segmentation plays a crucial role in various types of dialogue modeling tasks. The state-of-the-art unsupervised DTS methods learn topic-aware discourse representations from conversation data through adjacent discourse matching and pseudo segmentation to further mine useful clues in unlabeled conversational relations. However, in multi-round dialogs, discourses often have co-references or omissions, leading to the fact that direct use of these discourses for representation learning may negatively affect the semantic similarity computation in the neighboring discourse matching task. In order to fully utilize the useful cues in conversational relations, this study proposes a novel unsupervised dialog topic segmentation method that combines the Utterance Rewriting (UR) technique with an unsupervised learning algorithm to efficiently utilize the useful cues in unlabeled dialogs by rewriting the dialogs in order to recover the co-referents and omitted words. Compared with existing unsupervised models, the proposed Discourse Rewriting Topic Segmentation Model (UR-DTS) significantly improves the accuracy of topic segmentation. The main finding is that the performance on DialSeg711 improves by about 6% in terms of absolute error score and WD, achieving 11.42% in terms of absolute error score and 12.97% in terms of WD. on Doc2Dial the absolute error score and WD improves by about 3% and 2%, respectively, resulting in SOTA reaching 35.17% in terms of absolute error score and 38.49% in terms of WD. This shows that the model is very effective in capturing the nuances of conversational topics, as well as the usefulness and challenges of utilizing unlabeled conversations.
Raw Text is All you Need: Knowledge-intensive Multi-turn Instruction Tuning for Large Language Model
Jul 03, 2024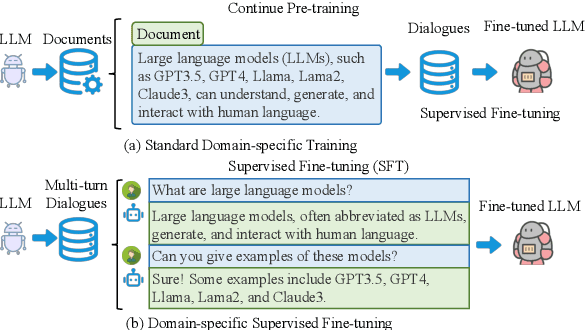



Instruction tuning as an effective technique aligns the outputs of large language models (LLMs) with human preference. But how to generate the seasonal multi-turn dialogues from raw documents for instruction tuning still requires further exploration. In this paper, we present a novel framework named R2S that leverages the CoD-Chain of Dialogue logic to guide large language models (LLMs) in generating knowledge-intensive multi-turn dialogues for instruction tuning. By integrating raw documents from both open-source datasets and domain-specific web-crawled documents into a benchmark K-BENCH, we cover diverse areas such as Wikipedia (English), Science (Chinese), and Artifacts (Chinese). Our approach first decides the logic flow of the current dialogue and then prompts LLMs to produce key phrases for sourcing relevant response content. This methodology enables the creation of the G I NSTRUCT instruction dataset, retaining raw document knowledge within dialoguestyle interactions. Utilizing this dataset, we fine-tune GLLM, a model designed to transform raw documents into structured multi-turn dialogues, thereby injecting comprehensive domain knowledge into the SFT model for enhanced instruction tuning. This work signifies a stride towards refining the adaptability and effectiveness of LLMs in processing and generating more accurate, contextually nuanced responses across various fields.
Bench2Drive: Towards Multi-Ability Benchmarking of Closed-Loop End-To-End Autonomous Driving
Jun 06, 2024
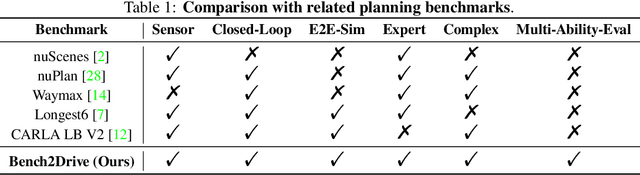
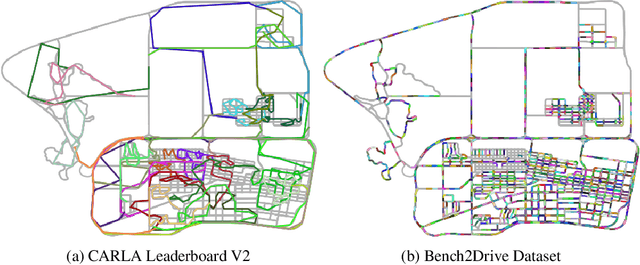

In an era marked by the rapid scaling of foundation models, autonomous driving technologies are approaching a transformative threshold where end-to-end autonomous driving (E2E-AD) emerges due to its potential of scaling up in the data-driven manner. However, existing E2E-AD methods are mostly evaluated under the open-loop log-replay manner with L2 errors and collision rate as metrics (e.g., in nuScenes), which could not fully reflect the driving performance of algorithms as recently acknowledged in the community. For those E2E-AD methods evaluated under the closed-loop protocol, they are tested in fixed routes (e.g., Town05Long and Longest6 in CARLA) with the driving score as metrics, which is known for high variance due to the unsmoothed metric function and large randomness in the long route. Besides, these methods usually collect their own data for training, which makes algorithm-level fair comparison infeasible. To fulfill the paramount need of comprehensive, realistic, and fair testing environments for Full Self-Driving (FSD), we present Bench2Drive, the first benchmark for evaluating E2E-AD systems' multiple abilities in a closed-loop manner. Bench2Drive's official training data consists of 2 million fully annotated frames, collected from 10000 short clips uniformly distributed under 44 interactive scenarios (cut-in, overtaking, detour, etc), 23 weathers (sunny, foggy, rainy, etc), and 12 towns (urban, village, university, etc) in CARLA v2. Its evaluation protocol requires E2E-AD models to pass 44 interactive scenarios under different locations and weathers which sums up to 220 routes and thus provides a comprehensive and disentangled assessment about their driving capability under different situations. We implement state-of-the-art E2E-AD models and evaluate them in Bench2Drive, providing insights regarding current status and future directions.
Think2Drive: Efficient Reinforcement Learning by Thinking in Latent World Model for Quasi-Realistic Autonomous Driving (in CARLA-v2)
Feb 26, 2024Real-world autonomous driving (AD) especially urban driving involves many corner cases. The lately released AD simulator CARLA v2 adds 39 common events in the driving scene, and provide more quasi-realistic testbed compared to CARLA v1. It poses new challenge to the community and so far no literature has reported any success on the new scenarios in V2 as existing works mostly have to rely on specific rules for planning yet they cannot cover the more complex cases in CARLA v2. In this work, we take the initiative of directly training a planner and the hope is to handle the corner cases flexibly and effectively, which we believe is also the future of AD. To our best knowledge, we develop the first model-based RL method named Think2Drive for AD, with a world model to learn the transitions of the environment, and then it acts as a neural simulator to train the planner. This paradigm significantly boosts the training efficiency due to the low dimensional state space and parallel computing of tensors in the world model. As a result, Think2Drive is able to run in an expert-level proficiency in CARLA v2 within 3 days of training on a single A6000 GPU, and to our best knowledge, so far there is no reported success (100\% route completion)on CARLA v2. We also propose CornerCase-Repository, a benchmark that supports the evaluation of driving models by scenarios. Additionally, we propose a new and balanced metric to evaluate the performance by route completion, infraction number, and scenario density, so that the driving score could give more information about the actual driving performance.