 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepulsor: Accelerating Generative Modeling with a Contrastive Memory Bank
Dec 13, 2025
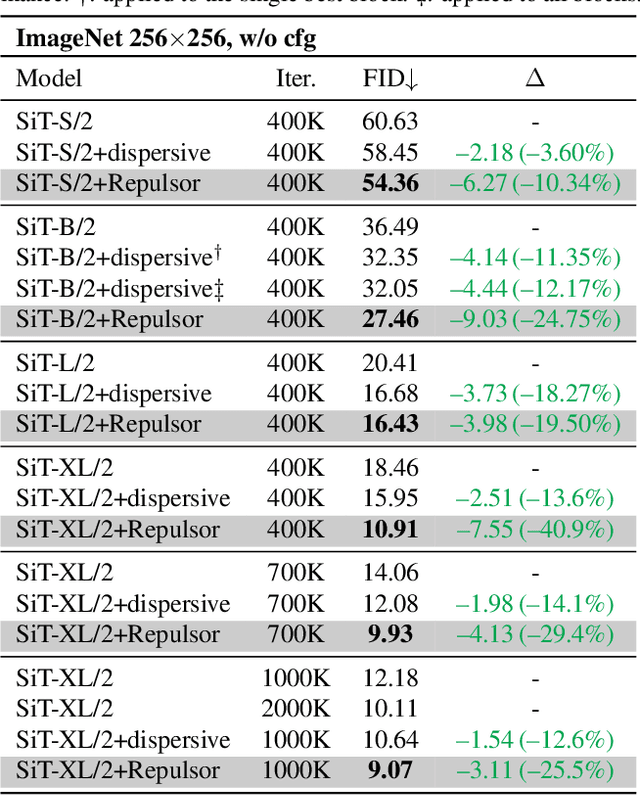
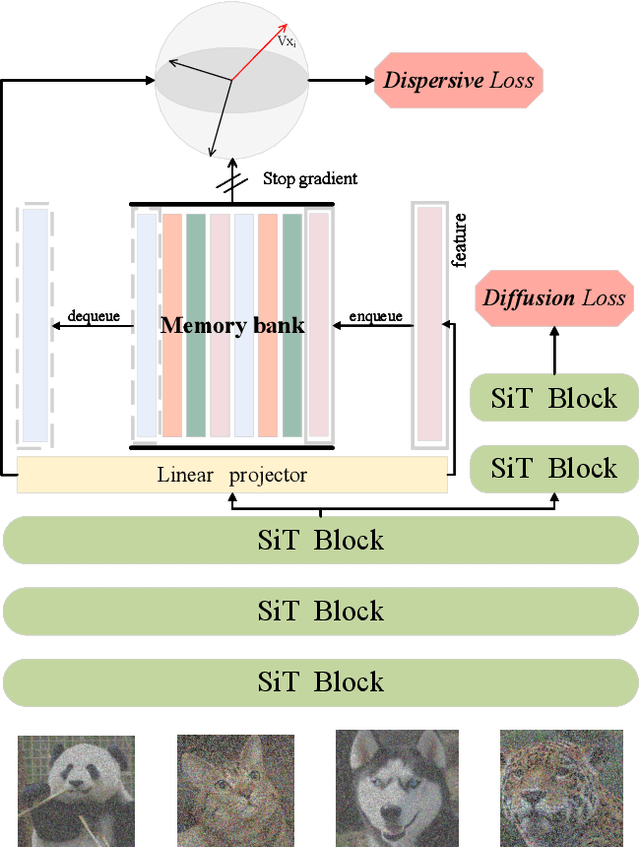

The dominance of denoising generative models (e.g., diffusion, flow-matching) in visual synthesis is tempered by their substantial training costs and inefficiencies in representation learning. While injecting discriminative representations via auxiliary alignment has proven effective, this approach still faces key limitations: the reliance on external, pre-trained encoders introduces overhead and domain shift. A dispersed-based strategy that encourages strong separation among in-batch latent representations alleviates this specific dependency. To assess the effect of the number of negative samples in generative modeling, we propose {\mname}, a plug-and-play training framework that requires no external encoders. Our method integrates a memory bank mechanism that maintains a large, dynamically updated queue of negative samples across training iterations. This decouples the number of negatives from the mini-batch size, providing abundant and high-quality negatives for a contrastive objective without a multiplicative increase in computational cost. A low-dimensional projection head is used to further minimize memory and bandwidth overhead. {\mname} offers three principal advantages: (1) it is self-contained, eliminating dependency on pretrained vision foundation models and their associated forward-pass overhead; (2) it introduces no additional parameters or computational cost during inference; and (3) it enables substantially faster convergence, achieving superior generative quality more efficiently. On ImageNet-256, {\mname} achieves a state-of-the-art FID of \textbf{2.40} within 400k steps, significantly outperforming comparable methods.
ReSim: Reliable World Simulation for Autonomous Driving
Jun 11, 2025How can we reliably simulate future driving scenarios under a wide range of ego driving behaviors? Recent driving world models, developed exclusively on real-world driving data composed mainly of safe expert trajectories, struggle to follow hazardous or non-expert behaviors, which are rare in such data. This limitation restricts their applicability to tasks such as policy evaluation. In this work, we address this challenge by enriching real-world human demonstrations with diverse non-expert data collected from a driving simulator (e.g., CARLA), and building a controllable world model trained on this heterogeneous corpus. Starting with a video generator featuring a diffusion transformer architecture, we devise several strategies to effectively integrate conditioning signals and improve prediction controllability and fidelity. The resulting model, ReSim, enables Reliable Simulation of diverse open-world driving scenarios under various actions, including hazardous non-expert ones. To close the gap between high-fidelity simulation and applications that require reward signals to judge different actions, we introduce a Video2Reward module that estimates a reward from ReSim's simulated future. Our ReSim paradigm achieves up to 44% higher visual fidelity, improves controllability for both expert and non-expert actions by over 50%, and boosts planning and policy selection performance on NAVSIM by 2% and 25%, respectively.
DriveMoE: Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving
May 22, 2025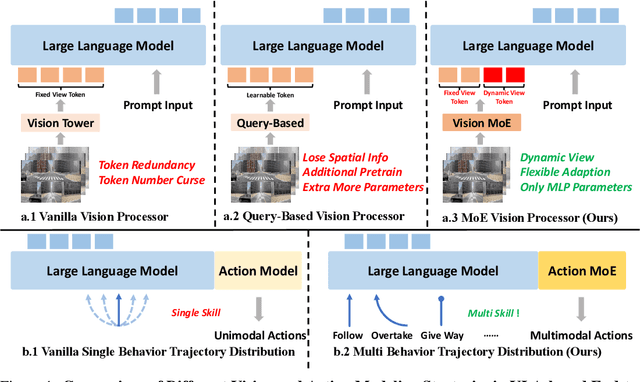
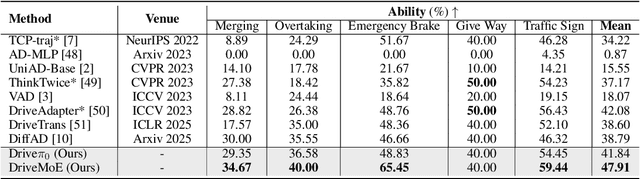
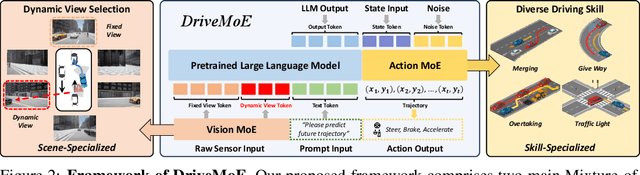
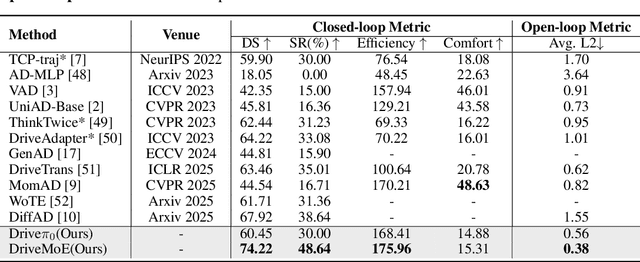
End-to-end autonomous driving (E2E-AD) demands effective processing of multi-view sensory data and robust handling of diverse and complex driving scenarios, particularly rare maneuvers such as aggressive turns. Recent success of Mixture-of-Experts (MoE) architecture in Large Language Models (LLMs) demonstrates that specialization of parameters enables strong scalability. In this work, we propose DriveMoE, a novel MoE-based E2E-AD framework, with a Scene-Specialized Vision MoE and a Skill-Specialized Action MoE. DriveMoE is built upon our $\pi_0$ Vision-Language-Action (VLA) baseline (originally from the embodied AI field), called Drive-$\pi_0$. Specifically, we add Vision MoE to Drive-$\pi_0$ by training a router to select relevant cameras according to the driving context dynamically. This design mirrors human driving cognition, where drivers selectively attend to crucial visual cues rather than exhaustively processing all visual information. In addition, we add Action MoE by training another router to activate specialized expert modules for different driving behaviors. Through explicit behavioral specialization, DriveMoE is able to handle diverse scenarios without suffering from modes averaging like existing models. In Bench2Drive closed-loop evaluation experiments, DriveMoE achieves state-of-the-art (SOTA) performance, demonstrating the effectiveness of combining vision and action MoE in autonomous driving tasks. We will release our code and models of DriveMoE and Drive-$\pi_0$.
Raw2Drive: Reinforcement Learning with Aligned World Models for End-to-End Autonomous Driving (in CARLA v2)
May 22, 2025Reinforcement Learning (RL) can mitigate the causal confusion and distribution shift inherent to imitation learning (IL). However, applying RL to end-to-end autonomous driving (E2E-AD) remains an open problem for its training difficulty, and IL is still the mainstream paradigm in both academia and industry. Recently Model-based Reinforcement Learning (MBRL) have demonstrated promising results in neural planning; however, these methods typically require privileged information as input rather than raw sensor data. We fill this gap by designing Raw2Drive, a dual-stream MBRL approach. Initially, we efficiently train an auxiliary privileged world model paired with a neural planner that uses privileged information as input. Subsequently, we introduce a raw sensor world model trained via our proposed Guidance Mechanism, which ensures consistency between the raw sensor world model and the privileged world model during rollouts. Finally, the raw sensor world model combines the prior knowledge embedded in the heads of the privileged world model to effectively guide the training of the raw sensor policy. Raw2Drive is so far the only RL based end-to-end method on CARLA Leaderboard 2.0, and Bench2Drive and it achieves state-of-the-art performance.
Interleave-VLA: Enhancing Robot Manipulation with Interleaved Image-Text Instructions
May 04, 2025Vision-Language-Action (VLA) models have shown great promise for generalist robotic manipulation in the physical world. However, existing models are restricted to robot observations and text-only instructions, lacking the flexibility of interleaved multimodal instructions enabled by recent advances in foundation models in the digital world. In this paper, we present Interleave-VLA, the first framework capable of comprehending interleaved image-text instructions and directly generating continuous action sequences in the physical world. It offers a flexible, model-agnostic paradigm that extends state-of-the-art VLA models with minimal modifications and strong zero-shot generalization. A key challenge in realizing Interleave-VLA is the absence of large-scale interleaved embodied datasets. To bridge this gap, we develop an automatic pipeline that converts text-only instructions from real-world datasets in Open X-Embodiment into interleaved image-text instructions, resulting in the first large-scale real-world interleaved embodied dataset with 210k episodes. Through comprehensive evaluation on simulation benchmarks and real-robot experiments, we demonstrate that Interleave-VLA offers significant benefits: 1) it improves out-of-domain generalization to unseen objects by 2-3x compared to state-of-the-art baselines, 2) supports flexible task interfaces, and 3) handles diverse user-provided image instructions in a zero-shot manner, such as hand-drawn sketches. We further analyze the factors behind Interleave-VLA's strong zero-shot performance, showing that the interleaved paradigm effectively leverages heterogeneous datasets and diverse instruction images, including those from the Internet, which demonstrates strong potential for scaling up. Our model and dataset will be open-sourced.
DriveTransformer: Unified Transformer for Scalable End-to-End Autonomous Driving
Mar 07, 2025End-to-end autonomous driving (E2E-AD) has emerged as a trend in the field of autonomous driving, promising a data-driven, scalable approach to system design. However, existing E2E-AD methods usually adopt the sequential paradigm of perception-prediction-planning, which leads to cumulative errors and training instability. The manual ordering of tasks also limits the system`s ability to leverage synergies between tasks (for example, planning-aware perception and game-theoretic interactive prediction and planning). Moreover, the dense BEV representation adopted by existing methods brings computational challenges for long-range perception and long-term temporal fusion. To address these challenges, we present DriveTransformer, a simplified E2E-AD framework for the ease of scaling up, characterized by three key features: Task Parallelism (All agent, map, and planning queries direct interact with each other at each block), Sparse Representation (Task queries direct interact with raw sensor features), and Streaming Processing (Task queries are stored and passed as history information). As a result, the new framework is composed of three unified operations: task self-attention, sensor cross-attention, temporal cross-attention, which significantly reduces the complexity of system and leads to better training stability. DriveTransformer achieves state-of-the-art performance in both simulated closed-loop benchmark Bench2Drive and real world open-loop benchmark nuScenes with high FPS.
PointOBB-v3: Expanding Performance Boundaries of Single Point-Supervised Oriented Object Detection
Jan 23, 2025



With the growing demand for oriented object detection (OOD), recent studies on point-supervised OOD have attracted significant interest. In this paper, we propose PointOBB-v3, a stronger single point-supervised OOD framework. Compared to existing methods, it generates pseudo rotated boxes without additional priors and incorporates support for the end-to-end paradigm. PointOBB-v3 functions by integrating three unique image views: the original view, a resized view, and a rotated/flipped (rot/flp) view. Based on the views, a scale augmentation module and an angle acquisition module are constructed. In the first module, a Scale-Sensitive Consistency (SSC) loss and a Scale-Sensitive Feature Fusion (SSFF) module are introduced to improve the model's ability to estimate object scale. To achieve precise angle predictions, the second module employs symmetry-based self-supervised learning. Additionally, we introduce an end-to-end version that eliminates the pseudo-label generation process by integrating a detector branch and introduces an Instance-Aware Weighting (IAW) strategy to focus on high-quality predictions. We conducted extensive experiments on the DIOR-R, DOTA-v1.0/v1.5/v2.0, FAIR1M, STAR, and RSAR datasets. Across all these datasets, our method achieves an average improvement in accuracy of 3.56% in comparison to previous state-of-the-art methods. The code will be available at https://github.com/ZpyWHU/PointOBB-v3.
Bench2Drive-R: Turning Real World Data into Reactive Closed-Loop Autonomous Driving Benchmark by Generative Model
Dec 11, 2024
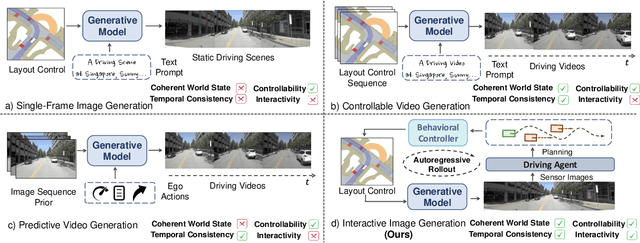
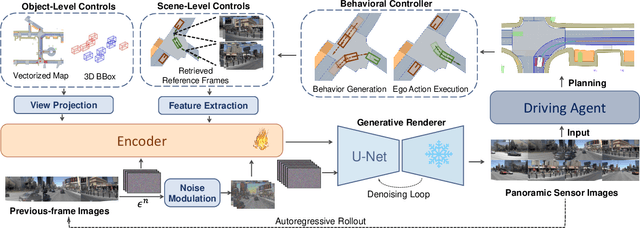
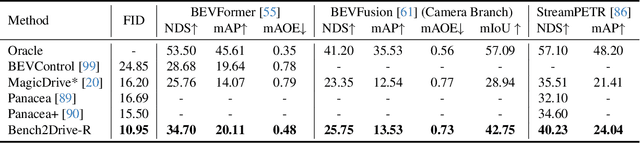
For end-to-end autonomous driving (E2E-AD), the evaluation system remains an open problem. Existing closed-loop evaluation protocols usually rely on simulators like CARLA being less realistic; while NAVSIM using real-world vision data, yet is limited to fixed planning trajectories in short horizon and assumes other agents are not reactive. We introduce Bench2Drive-R, a generative framework that enables reactive closed-loop evaluation. Unlike existing video generative models for AD, the proposed designs are tailored for interactive simulation, where sensor rendering and behavior rollout are decoupled by applying a separate behavioral controller to simulate the reactions of surrounding agents. As a result, the renderer could focus on image fidelity, control adherence, and spatial-temporal coherence. For temporal consistency, due to the step-wise interaction nature of simulation, we design a noise modulating temporal encoder with Gaussian blurring to encourage long-horizon autoregressive rollout of image sequences without deteriorating distribution shifts. For spatial consistency, a retrieval mechanism, which takes the spatially nearest images as references, is introduced to to ensure scene-level rendering fidelity during the generation process. The spatial relations between target and reference are explicitly modeled with 3D relative position encodings and the potential over-reliance of reference images is mitigated with hierarchical sampling and classifier-free guidance. We compare the generation quality of Bench2Drive-R with existing generative models and achieve state-of-the-art performance. We further integrate Bench2Drive-R into nuPlan and evaluate the generative qualities with closed-loop simulation results. We will open source our code.
FlatFusion: Delving into Details of Sparse Transformer-based Camera-LiDAR Fusion for Autonomous Driving
Aug 13, 2024The integration of data from diverse sensor modalities (e.g., camera and LiDAR) constitutes a prevalent methodology within the ambit of autonomous driving scenarios. Recent advancements in efficient point cloud transformers have underscored the efficacy of integrating information in sparse formats. When it comes to fusion, since image patches are dense in pixel space with ambiguous depth, it necessitates additional design considerations for effective fusion. In this paper, we conduct a comprehensive exploration of design choices for Transformer-based sparse cameraLiDAR fusion. This investigation encompasses strategies for image-to-3D and LiDAR-to-2D mapping, attention neighbor grouping, single modal tokenizer, and micro-structure of Transformer. By amalgamating the most effective principles uncovered through our investigation, we introduce FlatFusion, a carefully designed framework for sparse camera-LiDAR fusion. Notably, FlatFusion significantly outperforms state-of-the-art sparse Transformer-based methods, including UniTR, CMT, and SparseFusion, achieving 73.7 NDS on the nuScenes validation set with 10.1 FPS with PyTorch.
Bench2Drive: Towards Multi-Ability Benchmarking of Closed-Loop End-To-End Autonomous Driving
Jun 06, 2024
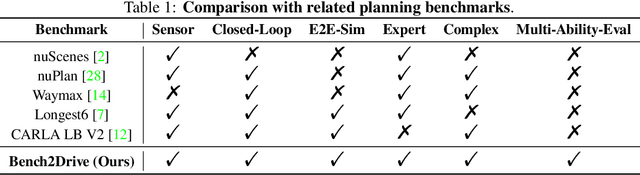
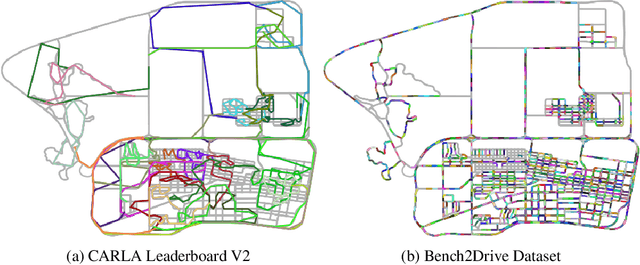

In an era marked by the rapid scaling of foundation models, autonomous driving technologies are approaching a transformative threshold where end-to-end autonomous driving (E2E-AD) emerges due to its potential of scaling up in the data-driven manner. However, existing E2E-AD methods are mostly evaluated under the open-loop log-replay manner with L2 errors and collision rate as metrics (e.g., in nuScenes), which could not fully reflect the driving performance of algorithms as recently acknowledged in the community. For those E2E-AD methods evaluated under the closed-loop protocol, they are tested in fixed routes (e.g., Town05Long and Longest6 in CARLA) with the driving score as metrics, which is known for high variance due to the unsmoothed metric function and large randomness in the long route. Besides, these methods usually collect their own data for training, which makes algorithm-level fair comparison infeasible. To fulfill the paramount need of comprehensive, realistic, and fair testing environments for Full Self-Driving (FSD), we present Bench2Drive, the first benchmark for evaluating E2E-AD systems' multiple abilities in a closed-loop manner. Bench2Drive's official training data consists of 2 million fully annotated frames, collected from 10000 short clips uniformly distributed under 44 interactive scenarios (cut-in, overtaking, detour, etc), 23 weathers (sunny, foggy, rainy, etc), and 12 towns (urban, village, university, etc) in CARLA v2. Its evaluation protocol requires E2E-AD models to pass 44 interactive scenarios under different locations and weathers which sums up to 220 routes and thus provides a comprehensive and disentangled assessment about their driving capability under different situations. We implement state-of-the-art E2E-AD models and evaluate them in Bench2Drive, providing insights regarding current status and future directions.