 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongAct: Harnessing Intrinsic Activation Patterns for Long-Context Reinforcement Learning
Apr 16, 2026Reinforcement Learning (RL) has emerged as a critical driver for enhancing the reasoning capabilities of Large Language Models (LLMs). While recent advancements have focused on reward engineering or data synthesis, few studies exploit the model's intrinsic representation characteristics to guide the training process. In this paper, we first observe the presence of high-magnitude activations within the query and key vectors when processing long contexts. Drawing inspiration from model quantization -- which establishes the criticality of such high-magnitude activations -- and the insight that long-context reasoning inherently exhibits a sparse structure, we hypothesize that these weights serve as the pivotal drivers for effective model optimization. Based on this insight, we propose LongAct, a strategy that shifts from uniform to saliency-guided sparse updates. By selectively updating only the weights associated with these significant activations, LongAct achieves an approximate 8% improvement on LongBench v2 and enhances generalization on the RULER benchmark. Furthermore, our method exhibits remarkable universality, consistently boosting performance across diverse RL algorithms such as GRPO and DAPO. Extensive ablation studies suggest that focusing on these salient features is key to unlocking long-context potential.
LongR: Unleashing Long-Context Reasoning via Reinforcement Learning with Dense Utility Rewards
Feb 05, 2026Reinforcement Learning has emerged as a key driver for LLM reasoning. This capability is equally pivotal in long-context scenarios--such as long-dialogue understanding and structured data analysis, where the challenge extends beyond consuming tokens to performing rigorous deduction. While existing efforts focus on data synthesis or architectural changes, recent work points out that relying solely on sparse, outcome-only rewards yields limited gains, as such coarse signals are often insufficient to effectively guide the complex long-context reasoning. To address this, we propose LongR, a unified framework that enhances long-context performance by integrating a dynamic "Think-and-Read" mechanism, which interleaves reasoning with document consultation, with a contextual density reward based on relative information gain to quantify the utility of the relevant documents. Empirically, LongR achieves a 9% gain on LongBench v2 and consistent improvements on RULER and InfiniteBench, demonstrating robust efficiency in navigating extensive contexts. Furthermore, LongR consistently enhances performance across diverse RL algorithms (e.g., DAPO, GSPO). Finally, we conduct in-depth analyses to investigate the impact of reasoning chain length on efficiency and the model's robustness against distractors.
Achieving $\varepsilon^{-2}$ Dependence for Average-Reward Q-Learning with a New Contraction Principle
Jan 29, 2026We present the convergence rates of synchronous and asynchronous Q-learning for average-reward Markov decision processes, where the absence of contraction poses a fundamental challenge. Existing non-asymptotic results overcome this challenge by either imposing strong assumptions to enforce seminorm contraction or relying on discounted or episodic Markov decision processes as successive approximations, which either require unknown parameters or result in suboptimal sample complexity. In this work, under a reachability assumption, we establish optimal $\widetilde{O}(\varepsilon^{-2})$ sample complexity guarantees (up to logarithmic factors) for a simple variant of synchronous and asynchronous Q-learning that samples from the lazified dynamics, where the system remains in the current state with some fixed probability. At the core of our analysis is the construction of an instance-dependent seminorm and showing that, after a lazy transformation of the Markov decision process, the Bellman operator becomes one-step contractive under this seminorm.
A Graph Neural Network with Auxiliary Task Learning for Missing PMU Data Reconstruction
Dec 31, 2025In wide-area measurement systems (WAMS), phasor measurement unit (PMU) measurement is prone to data missingness due to hardware failures, communication delays, and cyber-attacks. Existing data-driven methods are limited by inadaptability to concept drift in power systems, poor robustness under high missing rates, and reliance on the unrealistic assumption of full system observability. Thus, this paper proposes an auxiliary task learning (ATL) method for reconstructing missing PMU data. First, a K-hop graph neural network (GNN) is proposed to enable direct learning on the subgraph consisting of PMU nodes, overcoming the limitation of the incompletely observable system. Then, an auxiliary learning framework consisting of two complementary graph networks is designed for accurate reconstruction: a spatial-temporal GNN extracts spatial-temporal dependencies from PMU data to reconstruct missing values, and another auxiliary GNN utilizes the low-rank property of PMU data to achieve unsupervised online learning. In this way, the low-rank properties of the PMU data are dynamically leveraged across the architecture to ensure robustness and self-adaptation. Numerical results demonstrate the superior offline and online performance of the proposed method under high missing rates and incomplete observability.
GeoBench: Rethinking Multimodal Geometric Problem-Solving via Hierarchical Evaluation
Dec 30, 2025Geometric problem solving constitutes a critical branch of mathematical reasoning, requiring precise analysis of shapes and spatial relationships. Current evaluations of geometric reasoning in vision-language models (VLMs) face limitations, including the risk of test data contamination from textbook-based benchmarks, overemphasis on final answers over reasoning processes, and insufficient diagnostic granularity. To address these issues, we present GeoBench, a hierarchical benchmark featuring four reasoning levels in geometric problem-solving: Visual Perception, Goal-Oriented Planning, Rigorous Theorem Application, and Self-Reflective Backtracking. Through six formally verified tasks generated via TrustGeoGen, we systematically assess capabilities ranging from attribute extraction to logical error correction. Experiments reveal that while reasoning models like OpenAI-o3 outperform general MLLMs, performance declines significantly with increasing task complexity. Key findings demonstrate that sub-goal decomposition and irrelevant premise filtering critically influence final problem-solving accuracy, whereas Chain-of-Thought prompting unexpectedly degrades performance in some tasks. These findings establish GeoBench as a comprehensive benchmark while offering actionable guidelines for developing geometric problem-solving systems.
ProtoReasoning: Prototypes as the Foundation for Generalizable Reasoning in LLMs
Jun 18, 2025Recent advances in Large Reasoning Models (LRMs) trained with Long Chain-of-Thought (Long CoT) reasoning have demonstrated remarkable cross-domain generalization capabilities. However, the underlying mechanisms supporting such transfer remain poorly understood. We hypothesize that cross-domain generalization arises from shared abstract reasoning prototypes -- fundamental reasoning patterns that capture the essence of problems across domains. These prototypes minimize the nuances of the representation, revealing that seemingly diverse tasks are grounded in shared reasoning structures.Based on this hypothesis, we propose ProtoReasoning, a framework that enhances the reasoning ability of LLMs by leveraging scalable and verifiable prototypical representations (Prolog for logical reasoning, PDDL for planning).ProtoReasoning features: (1) an automated prototype construction pipeline that transforms problems into corresponding prototype representations; (2) a comprehensive verification system providing reliable feedback through Prolog/PDDL interpreters; (3) the scalability to synthesize problems arbitrarily within prototype space while ensuring correctness. Extensive experiments show that ProtoReasoning achieves 4.7% improvement over baseline models on logical reasoning (Enigmata-Eval), 6.3% improvement on planning tasks, 4.0% improvement on general reasoning (MMLU) and 1.0% on mathematics (AIME24). Significantly, our ablation studies confirm that learning in prototype space also demonstrates enhanced generalization to structurally similar problems compared to training solely on natural language representations, validating our hypothesis that reasoning prototypes serve as the foundation for generalizable reasoning in large language models.
Understanding and Benchmarking the Trustworthiness in Multimodal LLMs for Video Understanding
Jun 14, 2025Recent advancements in multimodal large language models for video understanding (videoLLMs) have improved their ability to process dynamic multimodal data. However, trustworthiness challenges factual inaccuracies, harmful content, biases, hallucinations, and privacy risks, undermine reliability due to video data's spatiotemporal complexities. This study introduces Trust-videoLLMs, a comprehensive benchmark evaluating videoLLMs across five dimensions: truthfulness, safety, robustness, fairness, and privacy. Comprising 30 tasks with adapted, synthetic, and annotated videos, the framework assesses dynamic visual scenarios, cross-modal interactions, and real-world safety concerns. Our evaluation of 23 state-of-the-art videoLLMs (5 commercial,18 open-source) reveals significant limitations in dynamic visual scene understanding and cross-modal perturbation resilience. Open-source videoLLMs show occasional truthfulness advantages but inferior overall credibility compared to commercial models, with data diversity outperforming scale effects. These findings highlight the need for advanced safety alignment to enhance capabilities. Trust-videoLLMs provides a publicly available, extensible toolbox for standardized trustworthiness assessments, bridging the gap between accuracy-focused benchmarks and critical demands for robustness, safety, fairness, and privacy.
Sample Complexity of Distributionally Robust Average-Reward Reinforcement Learning
May 15, 2025Motivated by practical applications where stable long-term performance is critical-such as robotics, operations research, and healthcare-we study the problem of distributionally robust (DR) average-reward reinforcement learning. We propose two algorithms that achieve near-optimal sample complexity. The first reduces the problem to a DR discounted Markov decision process (MDP), while the second, Anchored DR Average-Reward MDP, introduces an anchoring state to stabilize the controlled transition kernels within the uncertainty set. Assuming the nominal MDP is uniformly ergodic, we prove that both algorithms attain a sample complexity of $\widetilde{O}\left(|\mathbf{S}||\mathbf{A}| t_{\mathrm{mix}}^2\varepsilon^{-2}\right)$ for estimating the optimal policy as well as the robust average reward under KL and $f_k$-divergence-based uncertainty sets, provided the uncertainty radius is sufficiently small. Here, $\varepsilon$ is the target accuracy, $|\mathbf{S}|$ and $|\mathbf{A}|$ denote the sizes of the state and action spaces, and $t_{\mathrm{mix}}$ is the mixing time of the nominal MDP. This represents the first finite-sample convergence guarantee for DR average-reward reinforcement learning. We further validate the convergence rates of our algorithms through numerical experiments.
TrustGeoGen: Scalable and Formal-Verified Data Engine for Trustworthy Multi-modal Geometric Problem Solving
Apr 22, 2025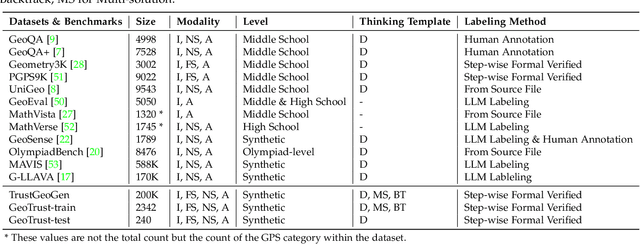
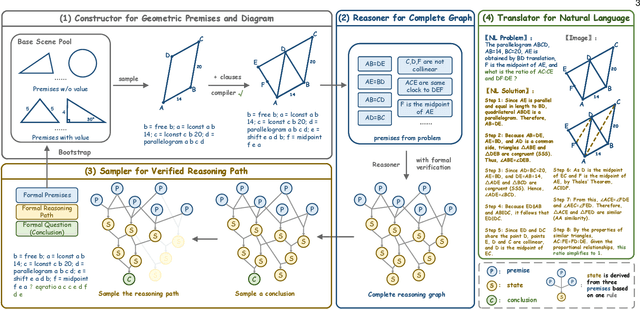
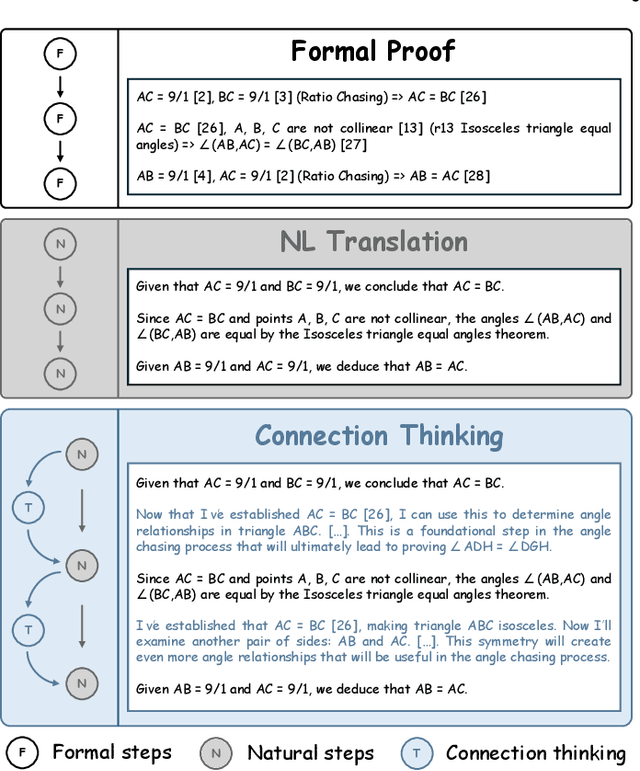
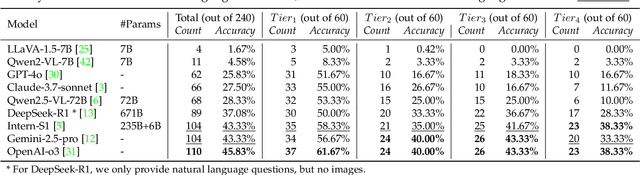
Mathematical geometric problem solving (GPS) often requires effective integration of multimodal information and verifiable logical coherence. Despite the fast development of large language models in general problem solving, it remains unresolved regarding with both methodology and benchmarks, especially given the fact that exiting synthetic GPS benchmarks are often not self-verified and contain noise and self-contradicted information due to the illusion of LLMs. In this paper, we propose a scalable data engine called TrustGeoGen for problem generation, with formal verification to provide a principled benchmark, which we believe lays the foundation for the further development of methods for GPS. The engine synthesizes geometric data through four key innovations: 1) multimodal-aligned generation of diagrams, textual descriptions, and stepwise solutions; 2) formal verification ensuring rule-compliant reasoning paths; 3) a bootstrapping mechanism enabling complexity escalation via recursive state generation and 4) our devised GeoExplore series algorithms simultaneously produce multi-solution variants and self-reflective backtracking traces. By formal logical verification, TrustGeoGen produces GeoTrust-200K dataset with guaranteed modality integrity, along with GeoTrust-test testset. Experiments reveal the state-of-the-art models achieve only 49.17\% accuracy on GeoTrust-test, demonstrating its evaluation stringency. Crucially, models trained on GeoTrust achieve OOD generalization on GeoQA, significantly reducing logical inconsistencies relative to pseudo-label annotated by OpenAI-o1. Our code is available at https://github.com/Alpha-Innovator/TrustGeoGen
Unveiling Uncertainty: A Deep Dive into Calibration and Performance of Multimodal Large Language Models
Dec 19, 2024



Multimodal large language models (MLLMs) combine visual and textual data for tasks such as image captioning and visual question answering. Proper uncertainty calibration is crucial, yet challenging, for reliable use in areas like healthcare and autonomous driving. This paper investigates representative MLLMs, focusing on their calibration across various scenarios, including before and after visual fine-tuning, as well as before and after multimodal training of the base LLMs. We observed miscalibration in their performance, and at the same time, no significant differences in calibration across these scenarios. We also highlight how uncertainty differs between text and images and how their integration affects overall uncertainty. To better understand MLLMs' miscalibration and their ability to self-assess uncertainty, we construct the IDK (I don't know) dataset, which is key to evaluating how they handle unknowns. Our findings reveal that MLLMs tend to give answers rather than admit uncertainty, but this self-assessment improves with proper prompt adjustments. Finally, to calibrate MLLMs and enhance model reliability, we propose techniques such as temperature scaling and iterative prompt optimization. Our results provide insights into improving MLLMs for effective and responsible deployment in multimodal applications. Code and IDK dataset: \href{https://github.com/hfutml/Calibration-MLLM}{https://github.com/hfutml/Calibration-MLLM}.