 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreaMontage: Arbitrary Frame-Guided One-Shot Video Generation
Dec 24, 2025The "one-shot" technique represents a distinct and sophisticated aesthetic in filmmaking. However, its practical realization is often hindered by prohibitive costs and complex real-world constraints. Although emerging video generation models offer a virtual alternative, existing approaches typically rely on naive clip concatenation, which frequently fails to maintain visual smoothness and temporal coherence. In this paper, we introduce DreaMontage, a comprehensive framework designed for arbitrary frame-guided generation, capable of synthesizing seamless, expressive, and long-duration one-shot videos from diverse user-provided inputs. To achieve this, we address the challenge through three primary dimensions. (i) We integrate a lightweight intermediate-conditioning mechanism into the DiT architecture. By employing an Adaptive Tuning strategy that effectively leverages base training data, we unlock robust arbitrary-frame control capabilities. (ii) To enhance visual fidelity and cinematic expressiveness, we curate a high-quality dataset and implement a Visual Expression SFT stage. In addressing critical issues such as subject motion rationality and transition smoothness, we apply a Tailored DPO scheme, which significantly improves the success rate and usability of the generated content. (iii) To facilitate the production of extended sequences, we design a Segment-wise Auto-Regressive (SAR) inference strategy that operates in a memory-efficient manner. Extensive experiments demonstrate that our approach achieves visually striking and seamlessly coherent one-shot effects while maintaining computational efficiency, empowering users to transform fragmented visual materials into vivid, cohesive one-shot cinematic experiences.
ProtoReasoning: Prototypes as the Foundation for Generalizable Reasoning in LLMs
Jun 18, 2025Recent advances in Large Reasoning Models (LRMs) trained with Long Chain-of-Thought (Long CoT) reasoning have demonstrated remarkable cross-domain generalization capabilities. However, the underlying mechanisms supporting such transfer remain poorly understood. We hypothesize that cross-domain generalization arises from shared abstract reasoning prototypes -- fundamental reasoning patterns that capture the essence of problems across domains. These prototypes minimize the nuances of the representation, revealing that seemingly diverse tasks are grounded in shared reasoning structures.Based on this hypothesis, we propose ProtoReasoning, a framework that enhances the reasoning ability of LLMs by leveraging scalable and verifiable prototypical representations (Prolog for logical reasoning, PDDL for planning).ProtoReasoning features: (1) an automated prototype construction pipeline that transforms problems into corresponding prototype representations; (2) a comprehensive verification system providing reliable feedback through Prolog/PDDL interpreters; (3) the scalability to synthesize problems arbitrarily within prototype space while ensuring correctness. Extensive experiments show that ProtoReasoning achieves 4.7% improvement over baseline models on logical reasoning (Enigmata-Eval), 6.3% improvement on planning tasks, 4.0% improvement on general reasoning (MMLU) and 1.0% on mathematics (AIME24). Significantly, our ablation studies confirm that learning in prototype space also demonstrates enhanced generalization to structurally similar problems compared to training solely on natural language representations, validating our hypothesis that reasoning prototypes serve as the foundation for generalizable reasoning in large language models.
CoLaDa: A Collaborative Label Denoising Framework for Cross-lingual Named Entity Recognition
May 24, 2023Cross-lingual named entity recognition (NER) aims to train an NER system that generalizes well to a target language by leveraging labeled data in a given source language. Previous work alleviates the data scarcity problem by translating source-language labeled data or performing knowledge distillation on target-language unlabeled data. However, these methods may suffer from label noise due to the automatic labeling process. In this paper, we propose CoLaDa, a Collaborative Label Denoising Framework, to address this problem. Specifically, we first explore a model-collaboration-based denoising scheme that enables models trained on different data sources to collaboratively denoise pseudo labels used by each other. We then present an instance-collaboration-based strategy that considers the label consistency of each token's neighborhood in the representation space for denoising. Experiments on different benchmark datasets show that the proposed CoLaDa achieves superior results compared to previous methods, especially when generalizing to distant languages.
TIARA: Multi-grained Retrieval for Robust Question Answering over Large Knowledge Bases
Oct 24, 2022



Pre-trained language models (PLMs) have shown their effectiveness in multiple scenarios. However, KBQA remains challenging, especially regarding coverage and generalization settings. This is due to two main factors: i) understanding the semantics of both questions and relevant knowledge from the KB; ii) generating executable logical forms with both semantic and syntactic correctness. In this paper, we present a new KBQA model, TIARA, which addresses those issues by applying multi-grained retrieval to help the PLM focus on the most relevant KB contexts, viz., entities, exemplary logical forms, and schema items. Moreover, constrained decoding is used to control the output space and reduce generation errors. Experiments over important benchmarks demonstrate the effectiveness of our approach. TIARA outperforms previous SOTA, including those using PLMs or oracle entity annotations, by at least 4.1 and 1.1 F1 points on GrailQA and WebQuestionsSP, respectively.
Disentangling Reasoning Capabilities from Language Models with Compositional Reasoning Transformers
Oct 20, 2022
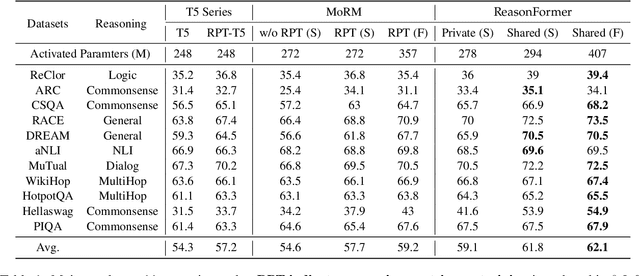


This paper presents ReasonFormer, a unified reasoning framework for mirroring the modular and compositional reasoning process of humans in complex decision making. Inspired by dual-process theory in cognitive science, the representation module (automatic thinking) and reasoning modules (controlled thinking) are disentangled to capture different levels of cognition. Upon the top of the representation module, the pre-trained reasoning modules are modular and expertise in specific and fundamental reasoning skills (e.g., logic, simple QA, etc). To mimic the controlled compositional thinking process, different reasoning modules are dynamically activated and composed in both parallel and cascaded manners to control what reasoning skills are activated and how deep the reasoning process will be reached to solve the current problems. The unified reasoning framework solves multiple tasks with a single model,and is trained and inferred in an end-to-end manner. Evaluated on 11 datasets requiring different reasoning skills and complexity, ReasonFormer demonstrates substantial performance boosts, revealing the compositional reasoning ability. Few-shot experiments exhibit better generalization ability by learning to compose pre-trained skills for new tasks with limited data,and decoupling the representation module and the reasoning modules. Further analysis shows the modularity of reasoning modules as different tasks activate distinct reasoning skills at different reasoning depths.
Decomposed Meta-Learning for Few-Shot Named Entity Recognition
Apr 13, 2022

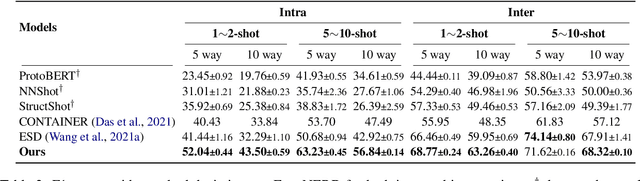

Few-shot named entity recognition (NER) systems aim at recognizing novel-class named entities based on only a few labeled examples. In this paper, we present a decomposed meta-learning approach which addresses the problem of few-shot NER by sequentially tackling few-shot span detection and few-shot entity typing using meta-learning. In particular, we take the few-shot span detection as a sequence labeling problem and train the span detector by introducing the model-agnostic meta-learning (MAML) algorithm to find a good model parameter initialization that could fast adapt to new entity classes. For few-shot entity typing, we propose MAML-ProtoNet, i.e., MAML-enhanced prototypical networks to find a good embedding space that can better distinguish text span representations from different entity classes. Extensive experiments on various benchmarks show that our approach achieves superior performance over prior methods.