 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenWebRL: Demystifying Online Multi-turn Reinforcement Learning for Visual Web Agents
Jun 01, 2026Building capable visual web agents requires long-horizon reasoning, precise grounding, and robust interaction with dynamic real-world websites. Despite rapid progress, the strongest systems remain largely proprietary, while open agents still depend heavily on supervised post-training over large collections of curated web trajectories. This dependence creates a major scalability bottleneck: high-quality demonstrations are expensive to collect, and static datasets offer limited coverage of the diverse, ever-changing open web. Although online RL has shown promise for text-based agents, its potential for training visual web agents directly on live websites remains largely underexplored. In this paper, we introduce OpenWebRL, an open framework for training visual web agents with online multi-turn RL on real websites. OpenWebRL covers the full training pipeline, including scalable live-browser infrastructure, supervised initialization, multimodal context management, trajectory-level success judging, and efficient multi-turn policy optimization. Using this framework, we train OpenWebRL-4B, which establishes a new open-source state of the art on challenging live-web benchmarks. With only 0.4K initialization trajectories and 2.2K open-ended RL training tasks, OpenWebRL-4B achieves 67.0% success on Online-Mind2Web and 64.0% on DeepShop, outperforming prior open agents of similar or larger scale and remaining competitive with proprietary systems including OpenAI CUA and Gemini CUA. Beyond strong benchmark performance, we systematically study the key design choices that make online RL effective for visual web agents, and analyze how RL improves agentic reasoning. Overall, our work offers a practical path toward building more capable, reproducible, and cost-efficient open web agents. We will release our training data, models, and code to support future research.
Orchard: An Open-Source Agentic Modeling Framework
May 14, 2026Agentic modeling aims to transform LLMs into autonomous agents capable of solving complex tasks through planning, reasoning, tool use, and multi-turn interaction with environments. Despite major investment, open research remains constrained by infrastructure and training gaps. Many high-performing systems rely on proprietary codebases, models, or services, while most open-source frameworks focus on orchestration and evaluation rather than scalable agent training. We present Orchard, an open-source framework for scalable agentic modeling. At its core is Orchard Env, a lightweight environment service providing reusable primitives for sandbox lifecycle management across task domains, agent harnesses, and pipeline stages. On top of Orchard Env, we build three agentic modeling recipes. Orchard-SWE targets coding agents. We distill 107K trajectories from MiniMax-M2.5 and Qwen3.5-397B, introduce credit-assignment SFT to learn from productive segments of unresolved trajectories, and apply Balanced Adaptive Rollout for RL. Starting from Qwen3-30B-A3B-Thinking, Orchard-SWE achieves 64.3% on SWE-bench Verified after SFT and 67.5% after SFT+RL, setting a new state of the art among open-source models of comparable size. Orchard-GUI trains a 4B vision-language computer-use agent using only 0.4K distilled trajectories and 2.2K open-ended tasks. It achieves 74.1%, 67.0%, and 64.0% success rates on WebVoyager, Online-Mind2Web, and DeepShop, respectively, making it the strongest open-source model while remaining competitive with proprietary systems. Orchard-Claw targets personal assistant agents. Trained with only 0.2K synthetic tasks, it achieves 59.6% pass@3 on Claw-Eval and 73.9% when paired with a stronger ZeroClaw harness. Collectively, these results show that a lightweight, open, harness-agnostic environment layer enables reusable agentic data, training recipes, and evaluations across domains.
WebXSkill: Skill Learning for Autonomous Web Agents
Apr 14, 2026Autonomous web agents powered by large language models (LLMs) have shown promise in completing complex browser tasks, yet they still struggle with long-horizon workflows. A key bottleneck is the grounding gap in existing skill formulations: textual workflow skills provide natural language guidance but cannot be directly executed, while code-based skills are executable but opaque to the agent, offering no step-level understanding for error recovery or adaptation. We introduce WebXSkill, a framework that bridges this gap with executable skills, each pairing a parameterized action program with step-level natural language guidance, enabling both direct execution and agent-driven adaptation. WebXSkill operates in three stages: skill extraction mines reusable action subsequences from readily available synthetic agent trajectories and abstracts them into parameterized skills, skill organization indexes skills into a URL-based graph for context-aware retrieval, and skill deployment exposes two complementary modes, grounded mode for fully automated multi-step execution and guided mode where skills serve as step-by-step instructions that the agent follows with its native planning. On WebArena and WebVoyager, WebXSkill improves task success rate by up to 9.8 and 12.9 points over the baseline, respectively, demonstrating the effectiveness of executable skills for web agents. The code is publicly available at https://github.com/aiming-lab/WebXSkill.
The Tool Illusion: Rethinking Tool Use in Web Agents
Apr 03, 2026As web agents rapidly evolve, an increasing body of work has moved beyond conventional atomic browser interactions and explored tool use as a higher-level action paradigm. Although prior studies have shown the promise of tools, their conclusions are often drawn from limited experimental scales and sometimes non-comparable settings. As a result, several fundamental questions remain unclear: i) whether tools provide consistent gains for web agents, ii) what practical design principles characterize effective tools, and iii) what side effects tool use may introduce. To establish a stronger empirical foundation for future research, we revisit tool use in web agents through an extensive and carefully controlled study across diverse tool sources, backbone models, tool-use frameworks, and evaluation benchmarks. Our findings both revise some prior conclusions and complement others with broader evidence. We hope this study provides a more reliable empirical basis and inspires future research on tool-use web agents.
GUI-Libra: Training Native GUI Agents to Reason and Act with Action-aware Supervision and Partially Verifiable RL
Feb 25, 2026Open-source native GUI agents still lag behind closed-source systems on long-horizon navigation tasks. This gap stems from two limitations: a shortage of high-quality, action-aligned reasoning data, and the direct adoption of generic post-training pipelines that overlook the unique challenges of GUI agents. We identify two fundamental issues in these pipelines: (i) standard SFT with CoT reasoning often hurts grounding, and (ii) step-wise RLVR-tyle training faces partial verifiability, where multiple actions can be correct but only a single demonstrated action is used for verification. This makes offline step-wise metrics weak predictors of online task success. In this work, we present GUI-Libra, a tailored training recipe that addresses these challenges. First, to mitigate the scarcity of action-aligned reasoning data, we introduce a data construction and filtering pipeline and release a curated 81K GUI reasoning dataset. Second, to reconcile reasoning with grounding, we propose action-aware SFT that mixes reasoning-then-action and direct-action data and reweights tokens to emphasize action and grounding. Third, to stabilize RL under partial verifiability, we identify the overlooked importance of KL regularization in RLVR and show that a KL trust region is critical for improving offline-to-online predictability; we further introduce success-adaptive scaling to downweight unreliable negative gradients. Across diverse web and mobile benchmarks, GUI-Libra consistently improves both step-wise accuracy and end-to-end task completion. Our results suggest that carefully designed post-training and data curation can unlock significantly stronger task-solving capabilities without costly online data collection. We release our dataset, code, and models to facilitate further research on data-efficient post-training for reasoning-capable GUI agents.
GUI-360$^\circ$: A Comprehensive Dataset and Benchmark for Computer-Using Agents
Nov 10, 2025We introduce GUI-360$^\circ$, a large-scale, comprehensive dataset and benchmark suite designed to advance computer-using agents (CUAs). CUAs present unique challenges and is constrained by three persistent gaps: a scarcity of real-world CUA tasks, the lack of automated collection-and-annotation pipelines for multi-modal trajectories, and the absence of a unified benchmark that jointly evaluates GUI grounding, screen parsing, and action prediction. GUI-360$^\circ$ addresses these gaps with an LLM-augmented, largely automated pipeline for query sourcing, environment-template construction, task instantiation, batched execution, and LLM-driven quality filtering. The released corpus contains over 1.2M executed action steps across thousands of trajectories in popular Windows office applications, and includes full-resolution screenshots, accessibility metadata when available, instantiated goals, intermediate reasoning traces, and both successful and failed action trajectories. The dataset supports three canonical tasks, GUI grounding, screen parsing, and action prediction, and a hybrid GUI+API action space that reflects modern agent designs. Benchmarking state-of-the-art vision--language models on GUI-360$^\circ$ reveals substantial out-of-the-box shortcomings in grounding and action prediction; supervised fine-tuning and reinforcement learning yield significant gains but do not close the gap to human-level reliability. We release GUI-360$^\circ$ and accompanying code to facilitate reproducible research and accelerate progress on robust desktop CUAs. The full dataset has been made public on https://huggingface.co/datasets/vyokky/GUI-360.
Adapting Web Agents with Synthetic Supervision
Nov 08, 2025Web agents struggle to adapt to new websites due to the scarcity of environment specific tasks and demonstrations. Recent works have explored synthetic data generation to address this challenge, however, they suffer from data quality issues where synthesized tasks contain hallucinations that cannot be executed, and collected trajectories are noisy with redundant or misaligned actions. In this paper, we propose SynthAgent, a fully synthetic supervision framework that aims at improving synthetic data quality via dual refinement of both tasks and trajectories. Our approach begins by synthesizing diverse tasks through categorized exploration of web elements, ensuring efficient coverage of the target environment. During trajectory collection, we refine tasks when conflicts with actual observations are detected, mitigating hallucinations while maintaining task consistency. After collection, we conduct trajectory refinement with a global context to mitigate potential noise or misalignments. Finally, we fine-tune open-source web agents on the refined synthetic data to adapt them to the target environment. Experimental results demonstrate that SynthAgent outperforms existing synthetic data methods, validating the importance of high-quality synthetic supervision. The code will be publicly available at https://github.com/aiming-lab/SynthAgent.
GUI-360: A Comprehensive Dataset and Benchmark for Computer-Using Agents
Nov 06, 2025We introduce GUI-360$^\circ$, a large-scale, comprehensive dataset and benchmark suite designed to advance computer-using agents (CUAs). CUAs present unique challenges and is constrained by three persistent gaps: a scarcity of real-world CUA tasks, the lack of automated collection-and-annotation pipelines for multi-modal trajectories, and the absence of a unified benchmark that jointly evaluates GUI grounding, screen parsing, and action prediction. GUI-360$^\circ$ addresses these gaps with an LLM-augmented, largely automated pipeline for query sourcing, environment-template construction, task instantiation, batched execution, and LLM-driven quality filtering. The released corpus contains over 1.2M executed action steps across thousands of trajectories in popular Windows office applications, and includes full-resolution screenshots, accessibility metadata when available, instantiated goals, intermediate reasoning traces, and both successful and failed action trajectories. The dataset supports three canonical tasks, GUI grounding, screen parsing, and action prediction, and a hybrid GUI+API action space that reflects modern agent designs. Benchmarking state-of-the-art vision--language models on GUI-360$^\circ$ reveals substantial out-of-the-box shortcomings in grounding and action prediction; supervised fine-tuning and reinforcement learning yield significant gains but do not close the gap to human-level reliability. We release GUI-360$^\circ$ and accompanying code to facilitate reproducible research and accelerate progress on robust desktop CUAs. The full dataset has been made public on https://huggingface.co/datasets/vyokky/GUI-360.
Dyna-Mind: Learning to Simulate from Experience for Better AI Agents
Oct 10, 2025



Reasoning models have recently shown remarkable progress in domains such as math and coding. However, their expert-level abilities in math and coding contrast sharply with their performance in long-horizon, interactive tasks such as web navigation and computer/phone-use. Inspired by literature on human cognition, we argue that current AI agents need ''vicarious trial and error'' - the capacity to mentally simulate alternative futures before acting - in order to enhance their understanding and performance in complex interactive environments. We introduce Dyna-Mind, a two-stage training framework that explicitly teaches (V)LM agents to integrate such simulation into their reasoning. In stage 1, we introduce Reasoning with Simulations (ReSim), which trains the agent to generate structured reasoning traces from expanded search trees built from real experience gathered through environment interactions. ReSim thus grounds the agent's reasoning in faithful world dynamics and equips it with the ability to anticipate future states in its reasoning. In stage 2, we propose Dyna-GRPO, an online reinforcement learning method to further strengthen the agent's simulation and decision-making ability by using both outcome rewards and intermediate states as feedback from real rollouts. Experiments on two synthetic benchmarks (Sokoban and ALFWorld) and one realistic benchmark (AndroidWorld) demonstrate that (1) ReSim effectively infuses simulation ability into AI agents, and (2) Dyna-GRPO leverages outcome and interaction-level signals to learn better policies for long-horizon, planning-intensive tasks. Together, these results highlight the central role of simulation in enabling AI agents to reason, plan, and act more effectively in the ever more challenging environments.
MMInference: Accelerating Pre-filling for Long-Context VLMs via Modality-Aware Permutation Sparse Attention
Apr 22, 2025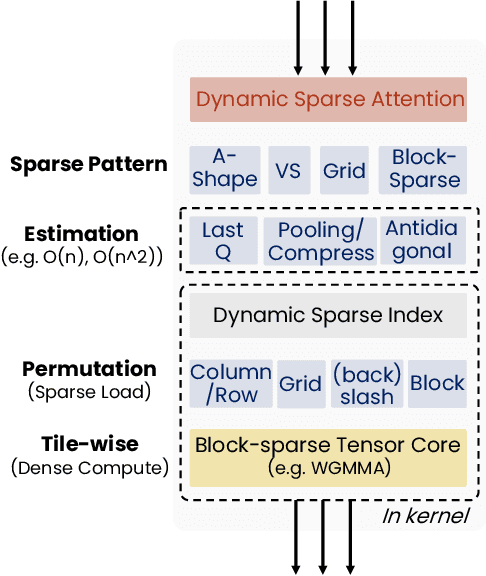
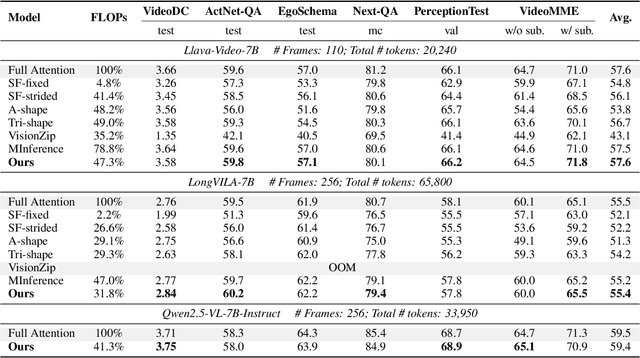
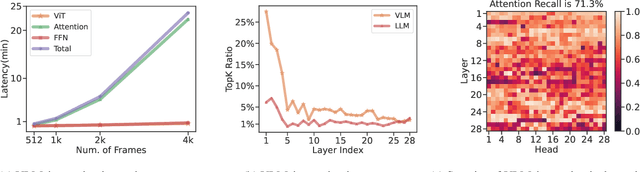

The integration of long-context capabilities with visual understanding unlocks unprecedented potential for Vision Language Models (VLMs). However, the quadratic attention complexity during the pre-filling phase remains a significant obstacle to real-world deployment. To overcome this limitation, we introduce MMInference (Multimodality Million tokens Inference), a dynamic sparse attention method that accelerates the prefilling stage for long-context multi-modal inputs. First, our analysis reveals that the temporal and spatial locality of video input leads to a unique sparse pattern, the Grid pattern. Simultaneously, VLMs exhibit markedly different sparse distributions across different modalities. We introduce a permutation-based method to leverage the unique Grid pattern and handle modality boundary issues. By offline search the optimal sparse patterns for each head, MMInference constructs the sparse distribution dynamically based on the input. We also provide optimized GPU kernels for efficient sparse computations. Notably, MMInference integrates seamlessly into existing VLM pipelines without any model modifications or fine-tuning. Experiments on multi-modal benchmarks-including Video QA, Captioning, VisionNIAH, and Mixed-Modality NIAH-with state-of-the-art long-context VLMs (LongVila, LlavaVideo, VideoChat-Flash, Qwen2.5-VL) show that MMInference accelerates the pre-filling stage by up to 8.3x at 1M tokens while maintaining accuracy. Our code is available at https://aka.ms/MMInference.