 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecurityLingua: Efficient Defense of LLM Jailbreak Attacks via Security-Aware Prompt Compression
Jun 15, 2025Large language models (LLMs) have achieved widespread adoption across numerous applications. However, many LLMs are vulnerable to malicious attacks even after safety alignment. These attacks typically bypass LLMs' safety guardrails by wrapping the original malicious instructions inside adversarial jailbreaks prompts. Previous research has proposed methods such as adversarial training and prompt rephrasing to mitigate these safety vulnerabilities, but these methods often reduce the utility of LLMs or lead to significant computational overhead and online latency. In this paper, we propose SecurityLingua, an effective and efficient approach to defend LLMs against jailbreak attacks via security-oriented prompt compression. Specifically, we train a prompt compressor designed to discern the "true intention" of the input prompt, with a particular focus on detecting the malicious intentions of adversarial prompts. Then, in addition to the original prompt, the intention is passed via the system prompt to the target LLM to help it identify the true intention of the request. SecurityLingua ensures a consistent user experience by leaving the original input prompt intact while revealing the user's potentially malicious intention and stimulating the built-in safety guardrails of the LLM. Moreover, thanks to prompt compression, SecurityLingua incurs only a negligible overhead and extra token cost compared to all existing defense methods, making it an especially practical solution for LLM defense. Experimental results demonstrate that SecurityLingua can effectively defend against malicious attacks and maintain utility of the LLM with negligible compute and latency overhead. Our code is available at https://aka.ms/SecurityLingua.
Llama See, Llama Do: A Mechanistic Perspective on Contextual Entrainment and Distraction in LLMs
May 14, 2025We observe a novel phenomenon, contextual entrainment, across a wide range of language models (LMs) and prompt settings, providing a new mechanistic perspective on how LMs become distracted by ``irrelevant'' contextual information in the input prompt. Specifically, LMs assign significantly higher logits (or probabilities) to any tokens that have previously appeared in the context prompt, even for random tokens. This suggests that contextual entrainment is a mechanistic phenomenon, occurring independently of the relevance or semantic relation of the tokens to the question or the rest of the sentence. We find statistically significant evidence that the magnitude of contextual entrainment is influenced by semantic factors. Counterfactual prompts have a greater effect compared to factual ones, suggesting that while contextual entrainment is a mechanistic phenomenon, it is modulated by semantic factors. We hypothesise that there is a circuit of attention heads -- the entrainment heads -- that corresponds to the contextual entrainment phenomenon. Using a novel entrainment head discovery method based on differentiable masking, we identify these heads across various settings. When we ``turn off'' these heads, i.e., set their outputs to zero, the effect of contextual entrainment is significantly attenuated, causing the model to generate output that capitulates to what it would produce if no distracting context were provided. Our discovery of contextual entrainment, along with our investigation into LM distraction via the entrainment heads, marks a key step towards the mechanistic analysis and mitigation of the distraction problem.
MMInference: Accelerating Pre-filling for Long-Context VLMs via Modality-Aware Permutation Sparse Attention
Apr 22, 2025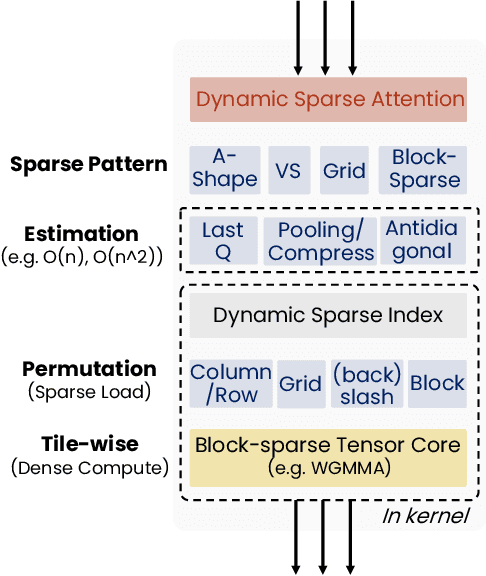
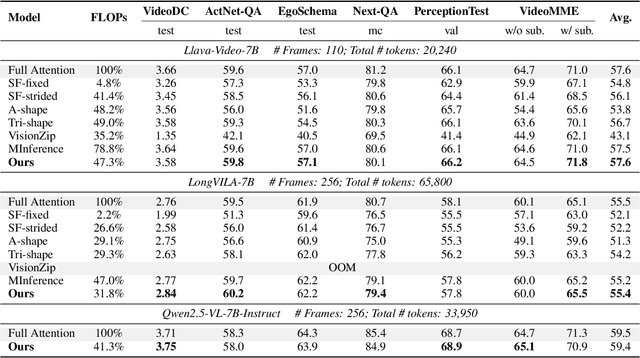
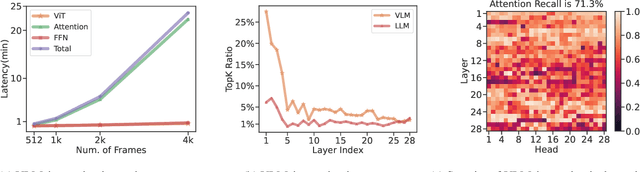

The integration of long-context capabilities with visual understanding unlocks unprecedented potential for Vision Language Models (VLMs). However, the quadratic attention complexity during the pre-filling phase remains a significant obstacle to real-world deployment. To overcome this limitation, we introduce MMInference (Multimodality Million tokens Inference), a dynamic sparse attention method that accelerates the prefilling stage for long-context multi-modal inputs. First, our analysis reveals that the temporal and spatial locality of video input leads to a unique sparse pattern, the Grid pattern. Simultaneously, VLMs exhibit markedly different sparse distributions across different modalities. We introduce a permutation-based method to leverage the unique Grid pattern and handle modality boundary issues. By offline search the optimal sparse patterns for each head, MMInference constructs the sparse distribution dynamically based on the input. We also provide optimized GPU kernels for efficient sparse computations. Notably, MMInference integrates seamlessly into existing VLM pipelines without any model modifications or fine-tuning. Experiments on multi-modal benchmarks-including Video QA, Captioning, VisionNIAH, and Mixed-Modality NIAH-with state-of-the-art long-context VLMs (LongVila, LlavaVideo, VideoChat-Flash, Qwen2.5-VL) show that MMInference accelerates the pre-filling stage by up to 8.3x at 1M tokens while maintaining accuracy. Our code is available at https://aka.ms/MMInference.
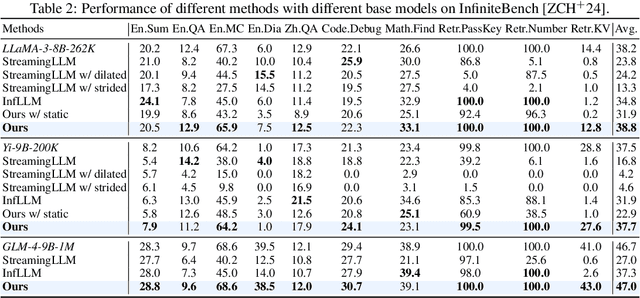
SCBench: A KV Cache-Centric Analysis of Long-Context Methods
Dec 13, 2024



Long-context LLMs have enabled numerous downstream applications but also introduced significant challenges related to computational and memory efficiency. To address these challenges, optimizations for long-context inference have been developed, centered around the KV cache. However, existing benchmarks often evaluate in single-request, neglecting the full lifecycle of the KV cache in real-world use. This oversight is particularly critical, as KV cache reuse has become widely adopted in LLMs inference frameworks, such as vLLM and SGLang, as well as by LLM providers, including OpenAI, Microsoft, Google, and Anthropic. To address this gap, we introduce SCBench(SharedContextBench), a comprehensive benchmark for evaluating long-context methods from a KV cachecentric perspective: 1) KV cache generation, 2) KV cache compression, 3) KV cache retrieval, 4) KV cache loading. Specifically, SCBench uses test examples with shared context, ranging 12 tasks with two shared context modes, covering four categories of long-context capabilities: string retrieval, semantic retrieval, global information, and multi-task. With it, we provide an extensive KV cache-centric analysis of eight categories long-context solutions, including Gated Linear RNNs, Mamba-Attention hybrids, and efficient methods such as sparse attention, KV cache dropping, quantization, retrieval, loading, and prompt compression. The evaluation is conducted on 8 long-context LLMs. Our findings show that sub-O(n) memory methods suffer in multi-turn scenarios, while sparse encoding with O(n) memory and sub-O(n^2) pre-filling computation perform robustly. Dynamic sparsity yields more expressive KV caches than static patterns, and layer-level sparsity in hybrid architectures reduces memory usage with strong performance. Additionally, we identify attention distribution shift issues in long-generation scenarios. https://aka.ms/SCBench.
MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention
Jul 02, 2024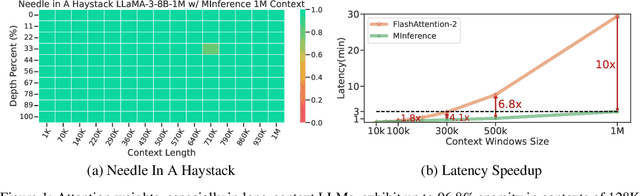

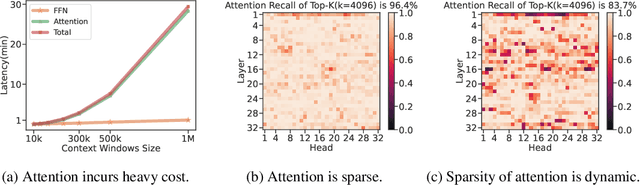
The computational challenges of Large Language Model (LLM) inference remain a significant barrier to their widespread deployment, especially as prompt lengths continue to increase. Due to the quadratic complexity of the attention computation, it takes 30 minutes for an 8B LLM to process a prompt of 1M tokens (i.e., the pre-filling stage) on a single A100 GPU. Existing methods for speeding up prefilling often fail to maintain acceptable accuracy or efficiency when applied to long-context LLMs. To address this gap, we introduce MInference (Milliontokens Inference), a sparse calculation method designed to accelerate pre-filling of long-sequence processing. Specifically, we identify three unique patterns in long-context attention matrices-the A-shape, Vertical-Slash, and Block-Sparsethat can be leveraged for efficient sparse computation on GPUs. We determine the optimal pattern for each attention head offline and dynamically build sparse indices based on the assigned pattern during inference. With the pattern and sparse indices, we perform efficient sparse attention calculations via our optimized GPU kernels to significantly reduce the latency in the pre-filling stage of long-context LLMs. Our proposed technique can be directly applied to existing LLMs without any modifications to the pre-training setup or additional fine-tuning. By evaluating on a wide range of downstream tasks, including InfiniteBench, RULER, PG-19, and Needle In A Haystack, and models including LLaMA-3-1M, GLM4-1M, Yi-200K, Phi-3-128K, and Qwen2-128K, we demonstrate that MInference effectively reduces inference latency by up to 10x for pre-filling on an A100, while maintaining accuracy. Our code is available at https://aka.ms/MInference.
NL2KQL: From Natural Language to Kusto Query
Apr 03, 2024



Data is growing rapidly in volume and complexity. Proficiency in database query languages is pivotal for crafting effective queries. As coding assistants become more prevalent, there is significant opportunity to enhance database query languages. The Kusto Query Language (KQL) is a widely used query language for large semi-structured data such as logs, telemetries, and time-series for big data analytics platforms. This paper introduces NL2KQL an innovative framework that uses large language models (LLMs) to convert natural language queries (NLQs) to KQL queries. The proposed NL2KQL framework includes several key components: Schema Refiner which narrows down the schema to its most pertinent elements; the Few-shot Selector which dynamically selects relevant examples from a few-shot dataset; and the Query Refiner which repairs syntactic and semantic errors in KQL queries. Additionally, this study outlines a method for generating large datasets of synthetic NLQ-KQL pairs which are valid within a specific database contexts. To validate NL2KQL's performance, we utilize an array of online (based on query execution) and offline (based on query parsing) metrics. Through ablation studies, the significance of each framework component is examined, and the datasets used for benchmarking are made publicly available. This work is the first of its kind and is compared with available baselines to demonstrate its effectiveness.
TD-GEN: Graph Generation With Tree Decomposition
Jun 20, 2021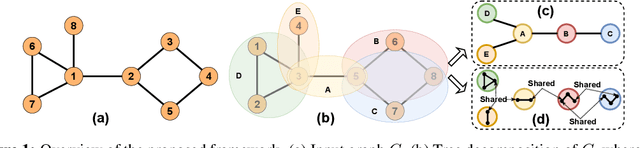
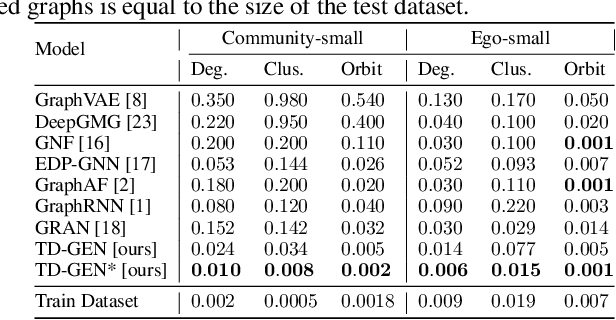
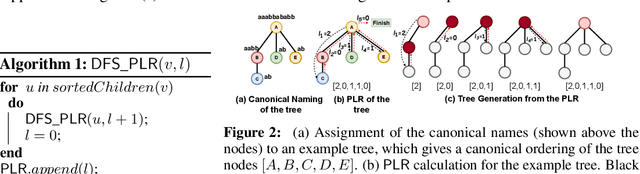
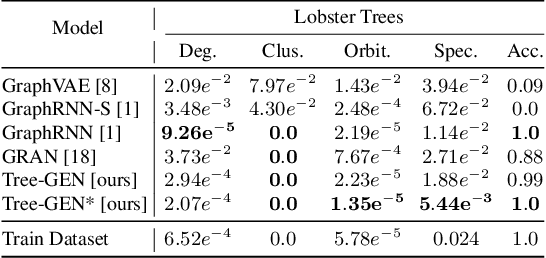
We propose TD-GEN, a graph generation framework based on tree decomposition, and introduce a reduced upper bound on the maximum number of decisions needed for graph generation. The framework includes a permutation invariant tree generation model which forms the backbone of graph generation. Tree nodes are supernodes, each representing a cluster of nodes in the graph. Graph nodes and edges are incrementally generated inside the clusters by traversing the tree supernodes, respecting the structure of the tree decomposition, and following node sharing decisions between the clusters. Finally, we discuss the shortcomings of standard evaluation criteria based on statistical properties of the generated graphs as performance measures. We propose to compare the performance of models based on likelihood. Empirical results on a variety of standard graph generation datasets demonstrate the superior performance of our method.
Variational Learning with Disentanglement-PyTorch
Dec 11, 2019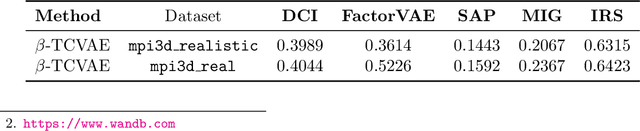

Unsupervised learning of disentangled representations is an open problem in machine learning. The Disentanglement-PyTorch library is developed to facilitate research, implementation, and testing of new variational algorithms. In this modular library, neural architectures, dimensionality of the latent space, and the training algorithms are fully decoupled, allowing for independent and consistent experiments across variational methods. The library handles the training scheduling, logging, and visualizations of reconstructions and latent space traversals. It also evaluates the encodings based on various disentanglement metrics. The library, so far, includes implementations of the following unsupervised algorithms VAE, Beta-VAE, Factor-VAE, DIP-I-VAE, DIP-II-VAE, Info-VAE, and Beta-TCVAE, as well as conditional approaches such as CVAE and IFCVAE. The library is compatible with the Disentanglement Challenge of NeurIPS 2019, hosted on AICrowd, and achieved the 3rd rank in both the first and second stages of the challenge.
A Study into Echocardiography View Conversion
Dec 05, 2019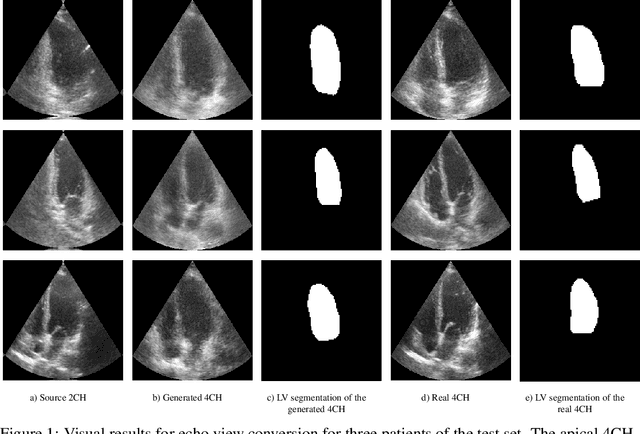
Transthoracic echo is one of the most common means of cardiac studies in the clinical routines. During the echo exam, the sonographer captures a set of standard cross sections (echo views) of the heart. Each 2D echo view cuts through the 3D cardiac geometry via a unique plane. Consequently, different views share some limited information. In this work, we investigate the feasibility of generating a 2D echo view using another view based on adversarial generative models. The objective optimized to train the view-conversion model is based on the ideas introduced by LSGAN, PatchGAN and Conditional GAN (cGAN). The size and length of the left ventricle in the generated target echo view is compared against that of the target ground-truth to assess the validity of the echo view conversion. Results show that there is a correlation of 0.50 between the LV areas and 0.49 between the LV lengths of the generated target frames and the real target frames.
A Preliminary Study of Disentanglement With Insights on the Inadequacy of Metrics
Nov 26, 2019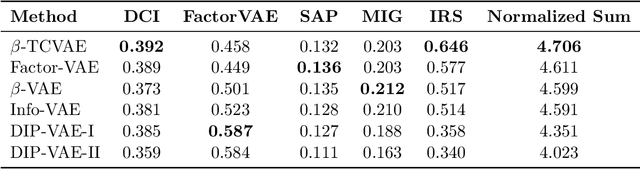
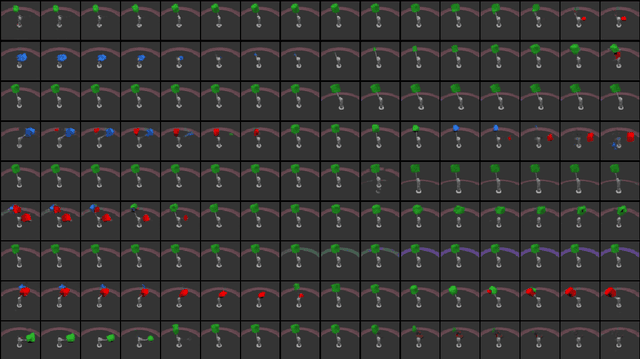

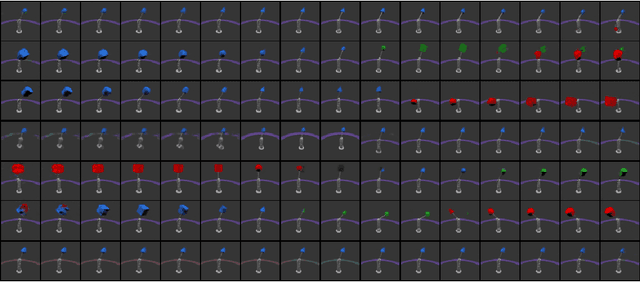
Disentangled encoding is an important step towards a better representation learning. However, despite the numerous efforts, there still is no clear winner that captures the independent features of the data in an unsupervised fashion. In this work we empirically evaluate the performance of six unsupervised disentanglement approaches on the mpi3d toy dataset curated and released for the NeurIPS 2019 Disentanglement Challenge. The methods investigated in this work are Beta-VAE, Factor-VAE, DIP-I-VAE, DIP-II-VAE, Info-VAE, and Beta-TCVAE. The capacities of all models were progressively increased throughout the training and the hyper-parameters were kept intact across experiments. The methods were evaluated based on five disentanglement metrics, namely, DCI, Factor-VAE, IRS, MIG, and SAP-Score. Within the limitations of this study, the Beta-TCVAE approach was found to outperform its alternatives with respect to the normalized sum of metrics. However, a qualitative study of the encoded latents reveal that there is not a consistent correlation between the reported metrics and the disentanglement potential of the model.