 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Need Reasoning to Learn Reasoning: The Limitations of Label-Free RL in Weak Base Models
Nov 07, 2025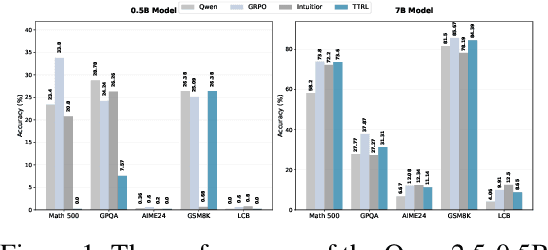
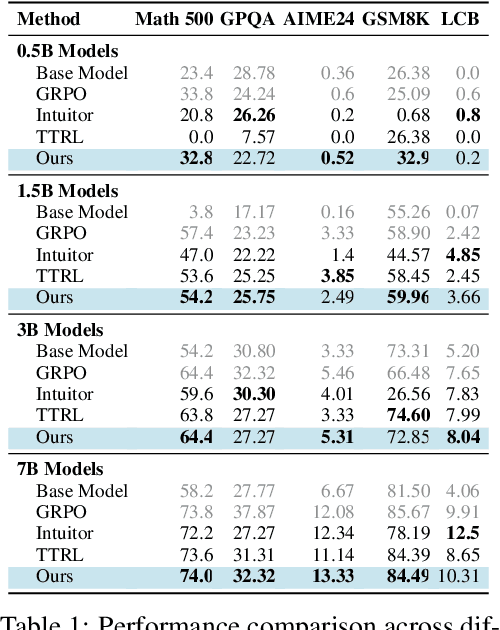

Recent advances in large language models have demonstrated the promise of unsupervised reinforcement learning (RL) methods for enhancing reasoning capabilities without external supervision. However, the generalizability of these label-free RL approaches to smaller base models with limited reasoning capabilities remains unexplored. In this work, we systematically investigate the performance of label-free RL methods across different model sizes and reasoning strengths, from 0.5B to 7B parameters. Our empirical analysis reveals critical limitations: label-free RL is highly dependent on the base model's pre-existing reasoning capability, with performance often degrading below baseline levels for weaker models. We find that smaller models fail to generate sufficiently long or diverse chain-of-thought reasoning to enable effective self-reflection, and that training data difficulty plays a crucial role in determining success. To address these challenges, we propose a simple yet effective method for label-free RL that utilizes curriculum learning to progressively introduce harder problems during training and mask no-majority rollouts during training. Additionally, we introduce a data curation pipeline to generate samples with predefined difficulty. Our approach demonstrates consistent improvements across all model sizes and reasoning capabilities, providing a path toward more robust unsupervised RL that can bootstrap reasoning abilities in resource-constrained models. We make our code available at https://github.com/BorealisAI/CuMa
TabReason: A Reinforcement Learning-Enhanced Reasoning LLM for Explainable Tabular Data Prediction
May 29, 2025Predictive modeling on tabular data is the cornerstone of many real-world applications. Although gradient boosting machines and some recent deep models achieve strong performance on tabular data, they often lack interpretability. On the other hand, large language models (LLMs) have demonstrated powerful capabilities to generate human-like reasoning and explanations, but remain under-performed for tabular data prediction. In this paper, we propose a new approach that leverages reasoning-based LLMs, trained using reinforcement learning, to perform more accurate and explainable predictions on tabular data. Our method introduces custom reward functions that guide the model not only toward high prediction accuracy but also toward human-understandable reasons for its predictions. Experimental results show that our model achieves promising performance on financial benchmark datasets, outperforming most existing LLMs.
Radar: Fast Long-Context Decoding for Any Transformer
Mar 13, 2025Transformer models have demonstrated exceptional performance across a wide range of applications. Though forming the foundation of Transformer models, the dot-product attention does not scale well to long-context data since its time requirement grows quadratically with context length. In this work, we propose Radar, a training-free approach that accelerates inference by dynamically searching for the most important context tokens. For any pre-trained Transformer, Radar can reduce the decoding time complexity without training or heuristically evicting tokens. Moreover, we provide theoretical justification for our approach, demonstrating that Radar can reliably identify the most important tokens with high probability. We conduct extensive comparisons with the previous methods on a wide range of tasks. The results demonstrate that Radar achieves the state-of-the-art performance across different architectures with reduced time complexity, offering a practical solution for efficient long-context processing of Transformers.
Attention as an RNN
May 22, 2024



The advent of Transformers marked a significant breakthrough in sequence modelling, providing a highly performant architecture capable of leveraging GPU parallelism. However, Transformers are computationally expensive at inference time, limiting their applications, particularly in low-resource settings (e.g., mobile and embedded devices). Addressing this, we (1) begin by showing that attention can be viewed as a special Recurrent Neural Network (RNN) with the ability to compute its \textit{many-to-one} RNN output efficiently. We then (2) show that popular attention-based models such as Transformers can be viewed as RNN variants. However, unlike traditional RNNs (e.g., LSTMs), these models cannot be updated efficiently with new tokens, an important property in sequence modelling. Tackling this, we (3) introduce a new efficient method of computing attention's \textit{many-to-many} RNN output based on the parallel prefix scan algorithm. Building on the new attention formulation, we (4) introduce \textbf{Aaren}, an attention-based module that can not only (i) be trained in parallel (like Transformers) but also (ii) be updated efficiently with new tokens, requiring only constant memory for inferences (like traditional RNNs). Empirically, we show Aarens achieve comparable performance to Transformers on $38$ datasets spread across four popular sequential problem settings: reinforcement learning, event forecasting, time series classification, and time series forecasting tasks while being more time and memory-efficient.
Tree Cross Attention
Sep 29, 2023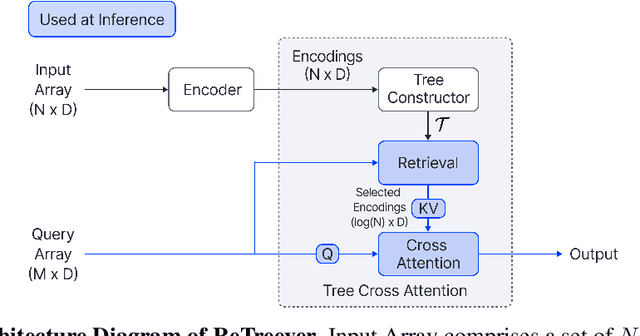
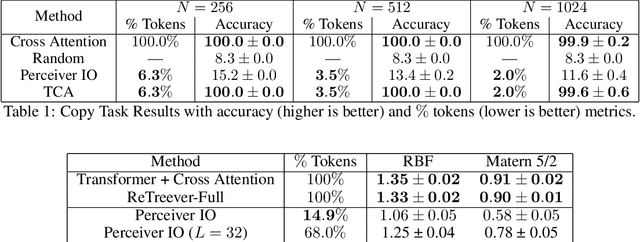
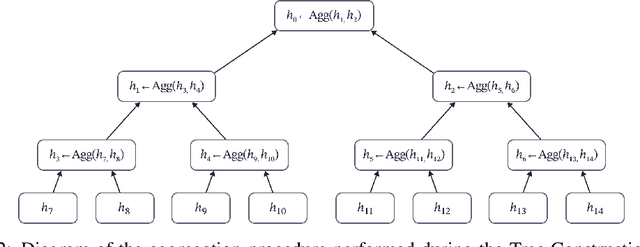

Cross Attention is a popular method for retrieving information from a set of context tokens for making predictions. At inference time, for each prediction, Cross Attention scans the full set of $\mathcal{O}(N)$ tokens. In practice, however, often only a small subset of tokens are required for good performance. Methods such as Perceiver IO are cheap at inference as they distill the information to a smaller-sized set of latent tokens $L < N$ on which cross attention is then applied, resulting in only $\mathcal{O}(L)$ complexity. However, in practice, as the number of input tokens and the amount of information to distill increases, the number of latent tokens needed also increases significantly. In this work, we propose Tree Cross Attention (TCA) - a module based on Cross Attention that only retrieves information from a logarithmic $\mathcal{O}(\log(N))$ number of tokens for performing inference. TCA organizes the data in a tree structure and performs a tree search at inference time to retrieve the relevant tokens for prediction. Leveraging TCA, we introduce ReTreever, a flexible architecture for token-efficient inference. We show empirically that Tree Cross Attention (TCA) performs comparable to Cross Attention across various classification and uncertainty regression tasks while being significantly more token-efficient. Furthermore, we compare ReTreever against Perceiver IO, showing significant gains while using the same number of tokens for inference.
Constant Memory Attention Block
Jun 21, 2023
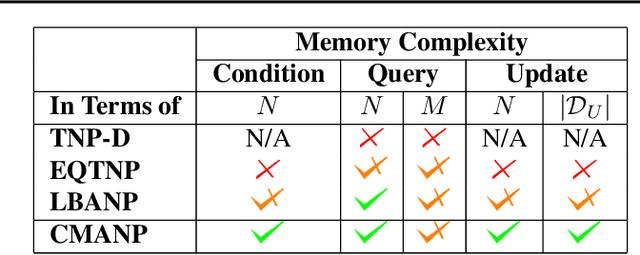

Modern foundation model architectures rely on attention mechanisms to effectively capture context. However, these methods require linear or quadratic memory in terms of the number of inputs/datapoints, limiting their applicability in low-compute domains. In this work, we propose Constant Memory Attention Block (CMAB), a novel general-purpose attention block that computes its output in constant memory and performs updates in constant computation. Highlighting CMABs efficacy, we introduce methods for Neural Processes and Temporal Point Processes. Empirically, we show our proposed methods achieve results competitive with state-of-the-art while being significantly more memory efficient.
Constant Memory Attentive Neural Processes
May 23, 2023



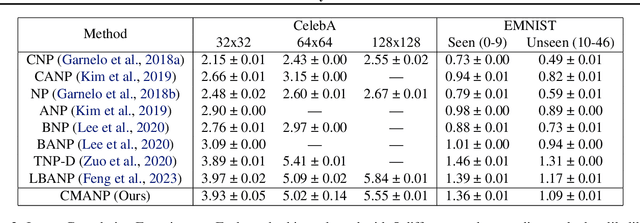
Neural Processes (NPs) are efficient methods for estimating predictive uncertainties. NPs comprise of a conditioning phase where a context dataset is encoded, a querying phase where the model makes predictions using the context dataset encoding, and an updating phase where the model updates its encoding with newly received datapoints. However, state-of-the-art methods require additional memory which scales linearly or quadratically with the size of the dataset, limiting their applications, particularly in low-resource settings. In this work, we propose Constant Memory Attentive Neural Processes (CMANPs), an NP variant which only requires constant memory for the conditioning, querying, and updating phases. In building CMANPs, we propose Constant Memory Attention Block (CMAB), a novel general-purpose attention block that can compute its output in constant memory and perform updates in constant computation. Empirically, we show CMANPs achieve state-of-the-art results on meta-regression and image completion tasks while being (1) significantly more memory efficient than prior methods and (2) more scalable to harder settings.
Latent Bottlenecked Attentive Neural Processes
Nov 15, 2022Neural Processes (NPs) are popular methods in meta-learning that can estimate predictive uncertainty on target datapoints by conditioning on a context dataset. Previous state-of-the-art method Transformer Neural Processes (TNPs) achieve strong performance but require quadratic computation with respect to the number of context datapoints, significantly limiting its scalability. Conversely, existing sub-quadratic NP variants perform significantly worse than that of TNPs. Tackling this issue, we propose Latent Bottlenecked Attentive Neural Processes (LBANPs), a new computationally efficient sub-quadratic NP variant, that has a querying computational complexity independent of the number of context datapoints. The model encodes the context dataset into a constant number of latent vectors on which self-attention is performed. When making predictions, the model retrieves higher-order information from the context dataset via multiple cross-attention mechanisms on the latent vectors. We empirically show that LBANPs achieve results competitive with the state-of-the-art on meta-regression, image completion, and contextual multi-armed bandits. We demonstrate that LBANPs can trade-off the computational cost and performance according to the number of latent vectors. Finally, we show LBANPs can scale beyond existing attention-based NP variants to larger dataset settings.
Training a Vision Transformer from scratch in less than 24 hours with 1 GPU
Nov 09, 2022
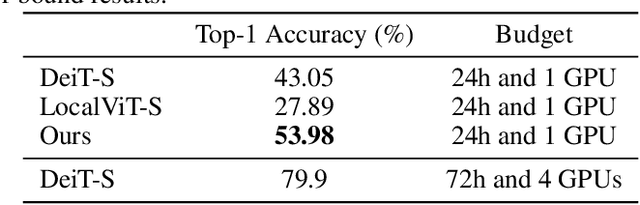
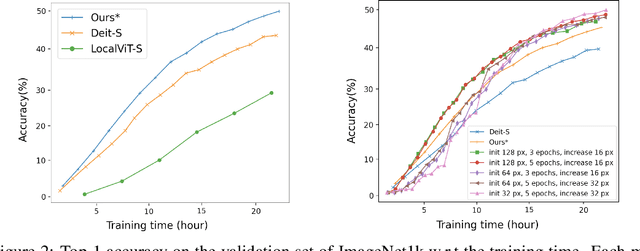
Transformers have become central to recent advances in computer vision. However, training a vision Transformer (ViT) model from scratch can be resource intensive and time consuming. In this paper, we aim to explore approaches to reduce the training costs of ViT models. We introduce some algorithmic improvements to enable training a ViT model from scratch with limited hardware (1 GPU) and time (24 hours) resources. First, we propose an efficient approach to add locality to the ViT architecture. Second, we develop a new image size curriculum learning strategy, which allows to reduce the number of patches extracted from each image at the beginning of the training. Finally, we propose a new variant of the popular ImageNet1k benchmark by adding hardware and time constraints. We evaluate our contributions on this benchmark, and show they can significantly improve performances given the proposed training budget. We will share the code in https://github.com/BorealisAI/efficient-vit-training.
Stop Overcomplicating Selective Classification: Use Max-Logit
Jun 17, 2022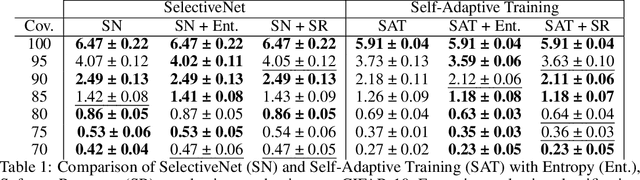
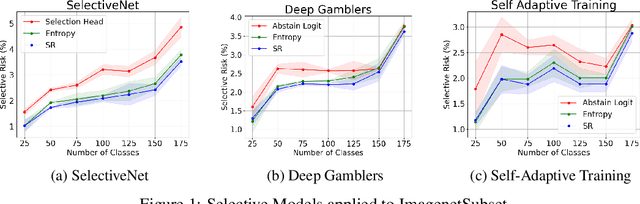
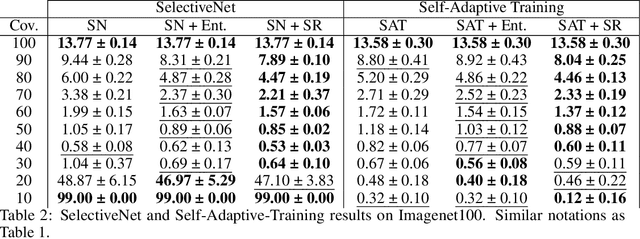
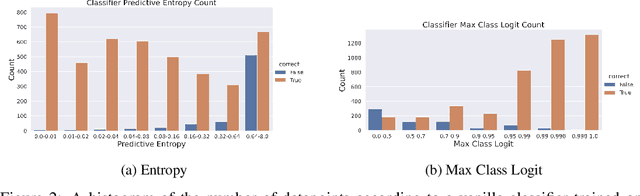
We tackle the problem of Selective Classification where the goal is to achieve the best performance on the desired coverages of the dataset. Recent state-of-the-art selective methods come with architectural changes either via introducing a separate selection head or an extra abstention logit. In this paper, we present surprising results for Selective Classification by confirming that the superior performance of state-of-the-art methods is owed to training a more generalizable classifier; however, their selection mechanism is suboptimal. We argue that the selection mechanism should be rooted in the objective function instead of a separately calculated score. Accordingly, in this paper, we motivate an alternative selection strategy that is based on the cross entropy loss for the classification settings, namely, max of the logits. Our proposed selection strategy achieves better results by a significant margin, consistently, across all coverages and all datasets, without any additional computation. Finally, inspired by our superior selection mechanism, we propose to further regularize the objective function with entropy-minimization. Our proposed max-logit selection with the modified loss function achieves new state-of-the-art results for Selective Classification.