 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadar: Fast Long-Context Decoding for Any Transformer
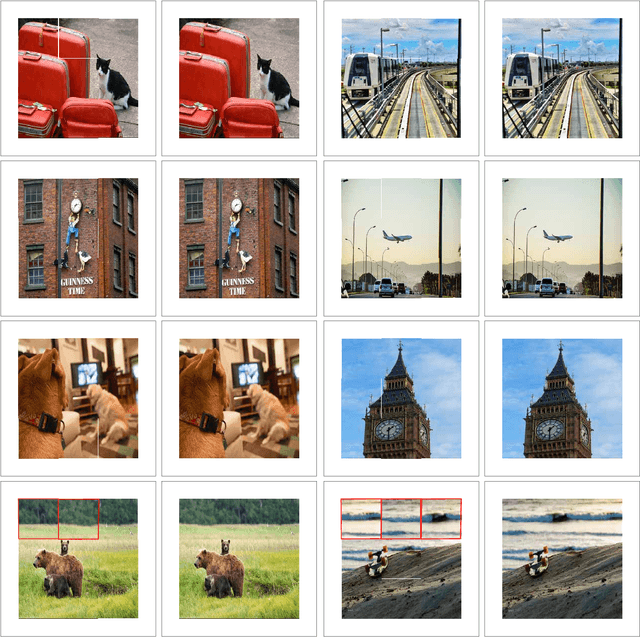
Mar 13, 2025Transformer models have demonstrated exceptional performance across a wide range of applications. Though forming the foundation of Transformer models, the dot-product attention does not scale well to long-context data since its time requirement grows quadratically with context length. In this work, we propose Radar, a training-free approach that accelerates inference by dynamically searching for the most important context tokens. For any pre-trained Transformer, Radar can reduce the decoding time complexity without training or heuristically evicting tokens. Moreover, we provide theoretical justification for our approach, demonstrating that Radar can reliably identify the most important tokens with high probability. We conduct extensive comparisons with the previous methods on a wide range of tasks. The results demonstrate that Radar achieves the state-of-the-art performance across different architectures with reduced time complexity, offering a practical solution for efficient long-context processing of Transformers.
Prompting-based Efficient Temporal Domain Generalization
Oct 03, 2023
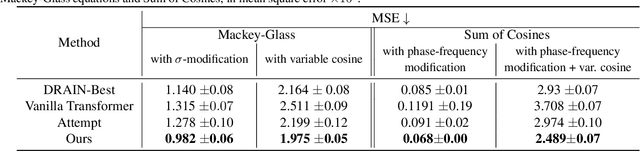
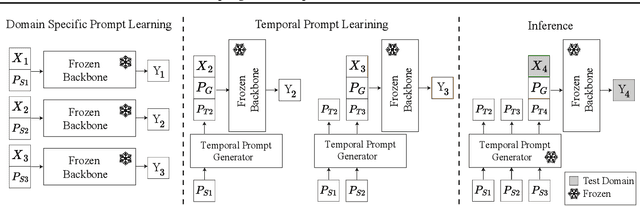
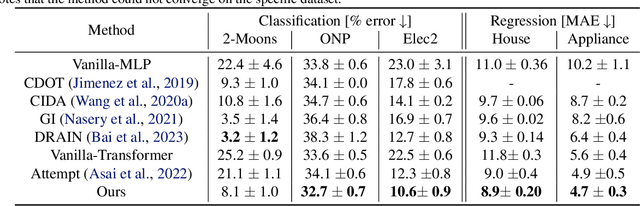
Machine learning traditionally assumes that training and testing data are distributed independently and identically. However, in many real-world settings, the data distribution can shift over time, leading to poor generalization of trained models in future time periods. Our paper presents a novel prompting-based approach to temporal domain generalization that is parameter-efficient, time-efficient, and does not require access to the target domain data (i.e., unseen future time periods) during training. Our method adapts a target pre-trained model to temporal drift by learning global prompts, domain-specific prompts, and drift-aware prompts that capture underlying temporal dynamics. It is compatible across diverse tasks, such as classification, regression, and time series forecasting, and sets a new state-of-the-art benchmark in temporal domain generalization. The code repository will be publicly shared.
JigsawPlan: Room Layout Jigsaw Puzzle Extreme Structure from Motion using Diffusion Models
Nov 24, 2022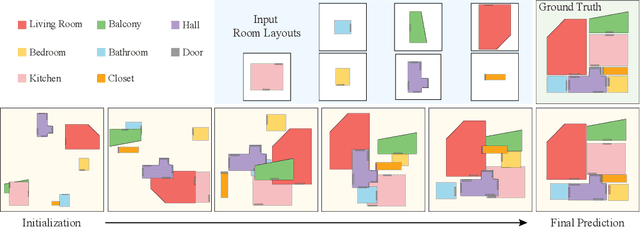

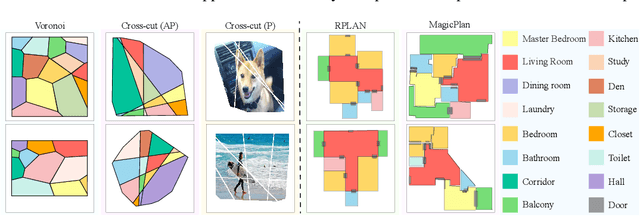
This paper presents a novel approach to the Extreme Structure from Motion (E-SfM) problem, which takes a set of room layouts as polygonal curves in the top-down view, and aligns the room layout pieces by estimating their 2D translations and rotations, akin to solving the jigsaw puzzle of room layouts. The biggest discovery and surprise of the paper is that the simple use of a Diffusion Model solves this challenging registration problem as a conditional generation process. The paper presents a new dataset of room layouts and floorplans for 98,780 houses. The qualitative and quantitative evaluations demonstrate that the proposed approach outperforms the competing methods by significant margins.
HouseDiffusion: Vector Floorplan Generation via a Diffusion Model with Discrete and Continuous Denoising
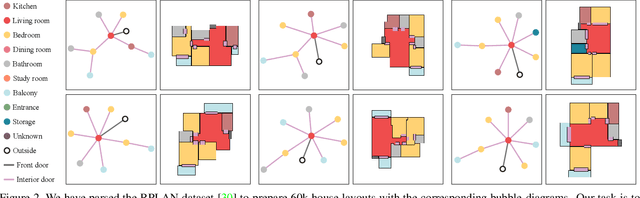
Nov 23, 2022The paper presents a novel approach for vector-floorplan generation via a diffusion model, which denoises 2D coordinates of room/door corners with two inference objectives: 1) a single-step noise as the continuous quantity to precisely invert the continuous forward process; and 2) the final 2D coordinate as the discrete quantity to establish geometric incident relationships such as parallelism, orthogonality, and corner-sharing. Our task is graph-conditioned floorplan generation, a common workflow in floorplan design. We represent a floorplan as 1D polygonal loops, each of which corresponds to a room or a door. Our diffusion model employs a Transformer architecture at the core, which controls the attention masks based on the input graph-constraint and directly generates vector-graphics floorplans via a discrete and continuous denoising process. We have evaluated our approach on RPLAN dataset. The proposed approach makes significant improvements in all the metrics against the state-of-the-art with significant margins, while being capable of generating non-Manhattan structures and controlling the exact number of corners per room. A project website with supplementary video and document is here https://aminshabani.github.io/housediffusion.
Extreme Floorplan Reconstruction by Structure-Hallucinating Transformer Cascades
Jun 01, 2022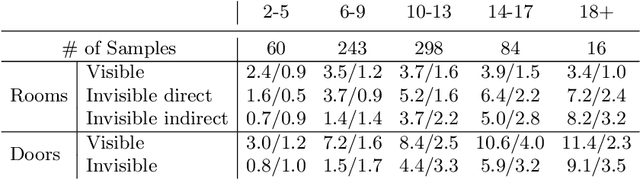
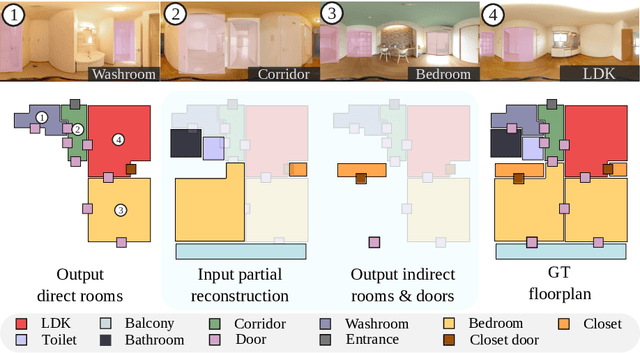
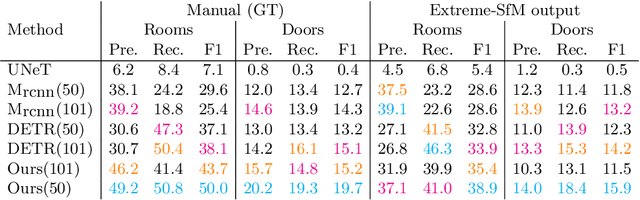
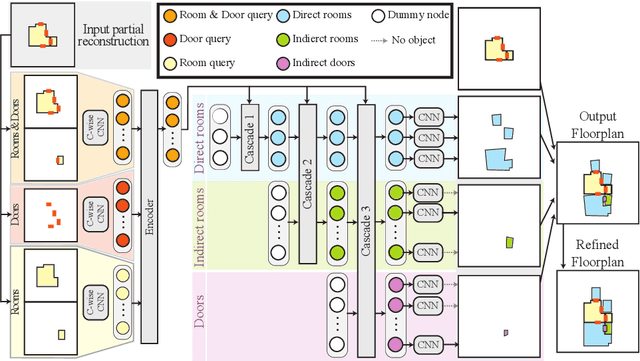
This paper presents an extreme floorplan reconstruction task, a new benchmark for the task, and a neural architecture as a solution. Given a partial floorplan reconstruction inferred or curated from panorama images, the task is to reconstruct a complete floorplan including invisible architectural structures. The proposed neural network 1) encodes an input partial floorplan into a set of latent vectors by convolutional neural networks and a Transformer; and 2) reconstructs an entire floorplan while hallucinating invisible rooms and doors by cascading Transformer decoders. Qualitative and quantitative evaluations demonstrate effectiveness of our approach over the benchmark of 701 houses, outperforming the state-of-the-art reconstruction techniques. We will share our code, models, and data.
House-GAN++: Generative Adversarial Layout Refinement Networks
Mar 03, 2021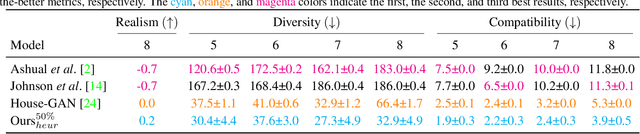
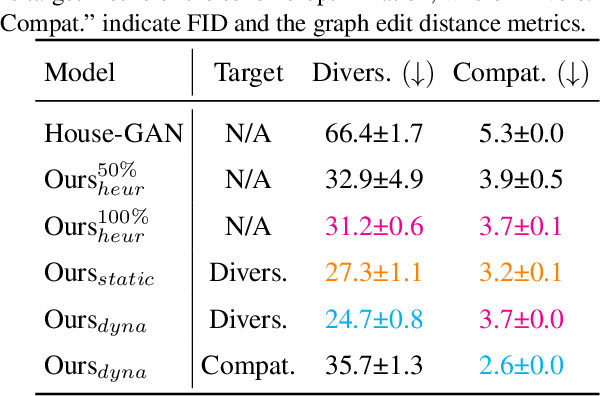
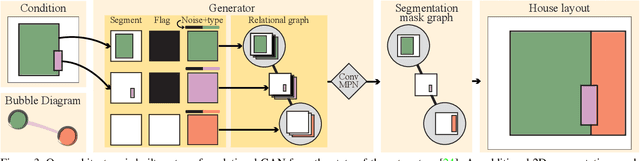
This paper proposes a novel generative adversarial layout refinement network for automated floorplan generation. Our architecture is an integration of a graph-constrained relational GAN and a conditional GAN, where a previously generated layout becomes the next input constraint, enabling iterative refinement. A surprising discovery of our research is that a simple non-iterative training process, dubbed component-wise GT-conditioning, is effective in learning such a generator. The iterative generator also creates a new opportunity in further improving a metric of choice via meta-optimization techniques by controlling when to pass which input constraints during iterative layout refinement. Our qualitative and quantitative evaluation based on the three standard metrics demonstrate that the proposed system makes significant improvements over the current state-of-the-art, even competitive against the ground-truth floorplans, designed by professional architects.
Distill-2MD-MTL: Data Distillation based on Multi-Dataset Multi-Domain Multi-Task Frame Work to Solve Face Related Tasksks, Multi Task Learning, Semi-Supervised Learning
Jul 09, 2019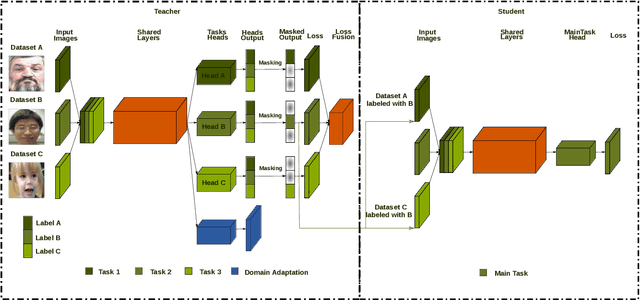
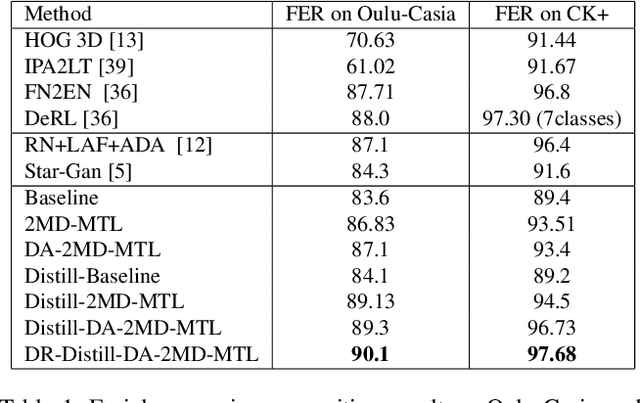

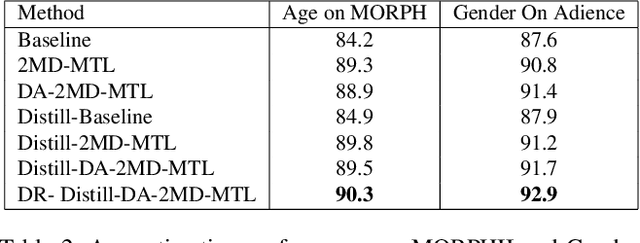
We propose a new semi-supervised learning method on face-related tasks based on Multi-Task Learning (MTL) and data distillation. The proposed method exploits multiple datasets with different labels for different-but-related tasks such as simultaneous age, gender, race, facial expression estimation. Specifically, when there are only a few well-labeled data for a specific task among the multiple related ones, we exploit the labels of other related tasks in different domains. Our approach is composed of (1) a new MTL method which can deal with weakly labeled datasets and perform several tasks simultaneously, and (2) an MTL-based data distillation framework which enables network generalization for the training and test data from different domains. Experiments show that the proposed multi-task system performs each task better than the baseline single task. It is also demonstrated that using different domain datasets along with the main dataset can enhance network generalization and overcome the domain differences between datasets. Also, comparing data distillation both on the baseline and MTL framework, the latter shows more accurate predictions on unlabeled data from different domains. Furthermore, by proposing a new learning-rate optimization method, our proposed network is able to dynamically tune its learning rate.
Feeding Hand-Crafted Features for Enhancing the Performance of Convolutional Neural Networks
Jan 24, 2018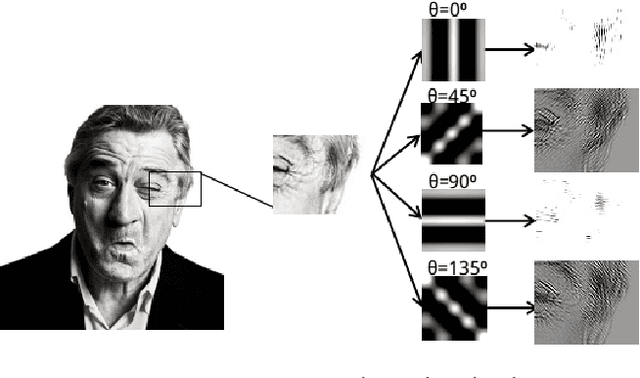
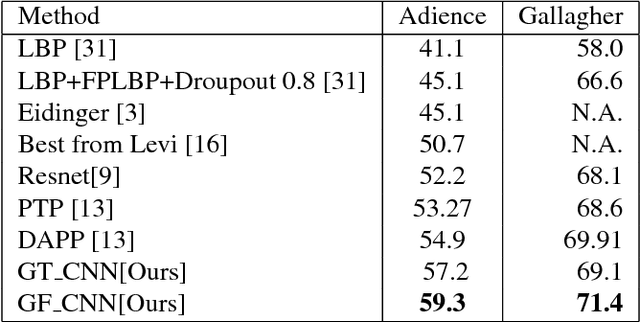
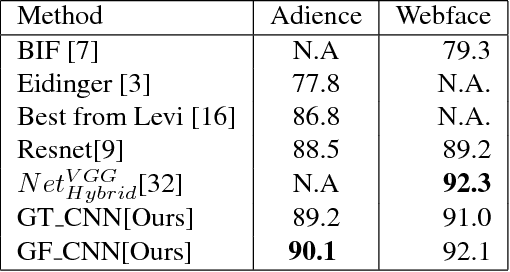
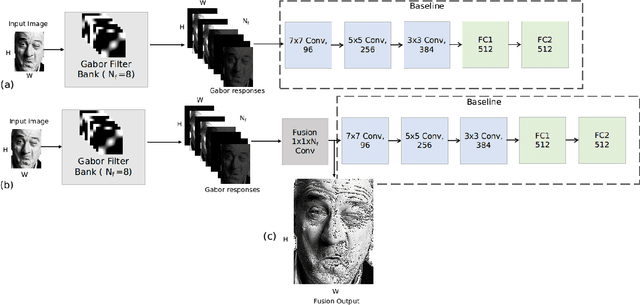
Since the convolutional neural network (CNN) is be- lieved to find right features for a given problem, the study of hand-crafted features is somewhat neglected these days. In this paper, we show that finding an appropriate feature for the given problem may be still important as they can en- hance the performance of CNN-based algorithms. Specif- ically, we show that feeding an appropriate feature to the CNN enhances its performance in some face related works such as age/gender estimation, face detection and emotion recognition. We use Gabor filter bank responses for these tasks, feeding them to the CNN along with the input image. The stack of image and Gabor responses can be fed to the CNN as a tensor input, or as a fused image which is a weighted sum of image and Gabor responses. The Gabor filter parameters can also be tuned depending on the given problem, for increasing the performance. From the extensive experiments, it is shown that the proposed methods provide better performance than the conventional CNN-based methods that use only the input images.