 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimCURL: Simple Contrastive User Representation Learning from Command Sequences
Jul 29, 2022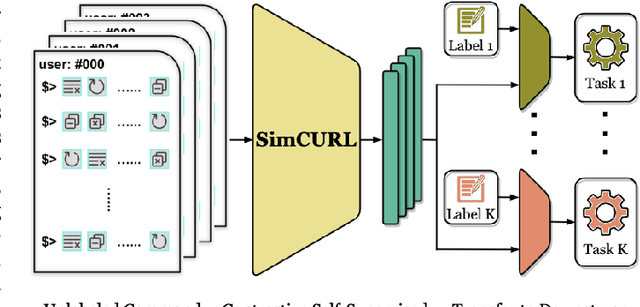

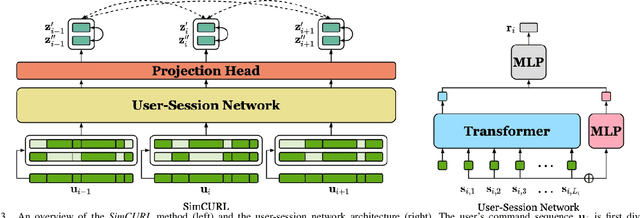

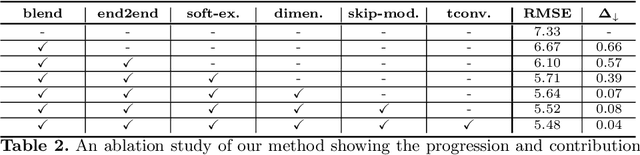
User modeling is crucial to understanding user behavior and essential for improving user experience and personalized recommendations. When users interact with software, vast amounts of command sequences are generated through logging and analytics systems. These command sequences contain clues to the users' goals and intents. However, these data modalities are highly unstructured and unlabeled, making it difficult for standard predictive systems to learn from. We propose SimCURL, a simple yet effective contrastive self-supervised deep learning framework that learns user representation from unlabeled command sequences. Our method introduces a user-session network architecture, as well as session dropout as a novel way of data augmentation. We train and evaluate our method on a real-world command sequence dataset of more than half a billion commands. Our method shows significant improvement over existing methods when the learned representation is transferred to downstream tasks such as experience and expertise classification.
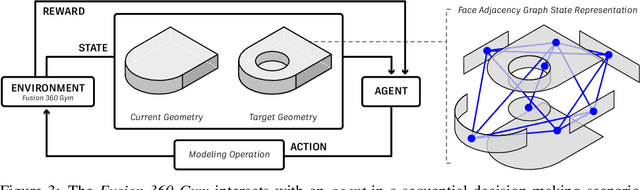
JoinABLe: Learning Bottom-up Assembly of Parametric CAD Joints
Nov 24, 2021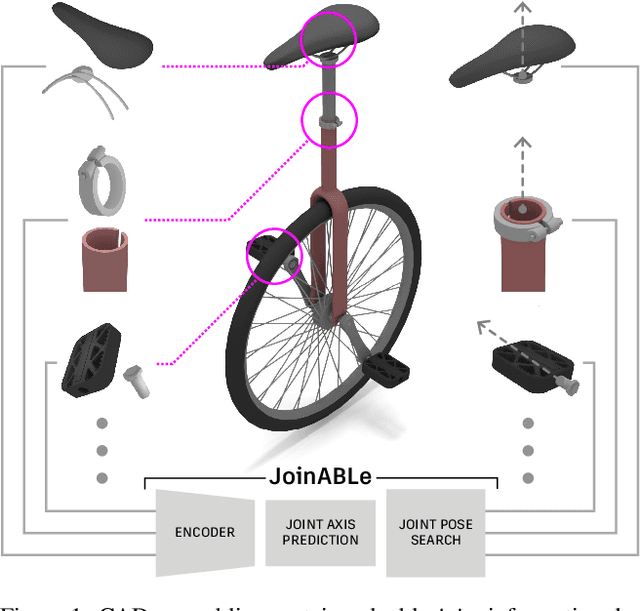
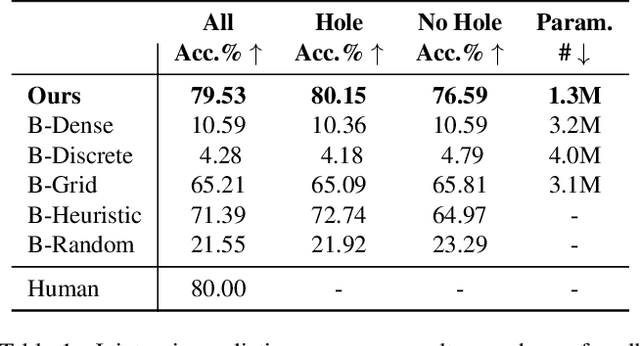
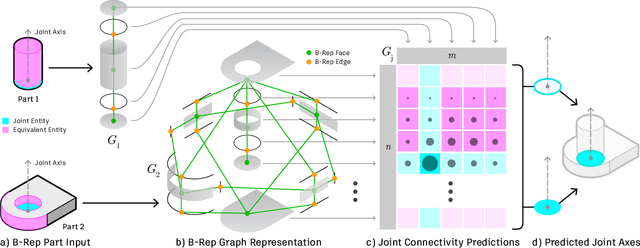
Physical products are often complex assemblies combining a multitude of 3D parts modeled in computer-aided design (CAD) software. CAD designers build up these assemblies by aligning individual parts to one another using constraints called joints. In this paper we introduce JoinABLe, a learning-based method that assembles parts together to form joints. JoinABLe uses the weak supervision available in standard parametric CAD files without the help of object class labels or human guidance. Our results show that by making network predictions over a graph representation of solid models we can outperform multiple baseline methods with an accuracy (79.53%) that approaches human performance (80%). Finally, to support future research we release the Fusion 360 Gallery assembly dataset, containing assemblies with rich information on joints, contact surfaces, holes, and the underlying assembly graph structure.
CLIP-Forge: Towards Zero-Shot Text-to-Shape Generation
Oct 06, 2021
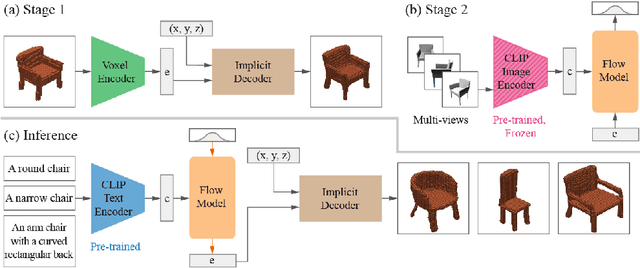


While recent progress has been made in text-to-image generation, text-to-shape generation remains a challenging problem due to the unavailability of paired text and shape data at a large scale. We present a simple yet effective method for zero-shot text-to-shape generation based on a two-stage training process, which only depends on an unlabelled shape dataset and a pre-trained image-text network such as CLIP. Our method not only demonstrates promising zero-shot generalization, but also avoids expensive inference time optimization and can generate multiple shapes for a given text.
LSD-StructureNet: Modeling Levels of Structural Detail in 3D Part Hierarchies
Sep 07, 2021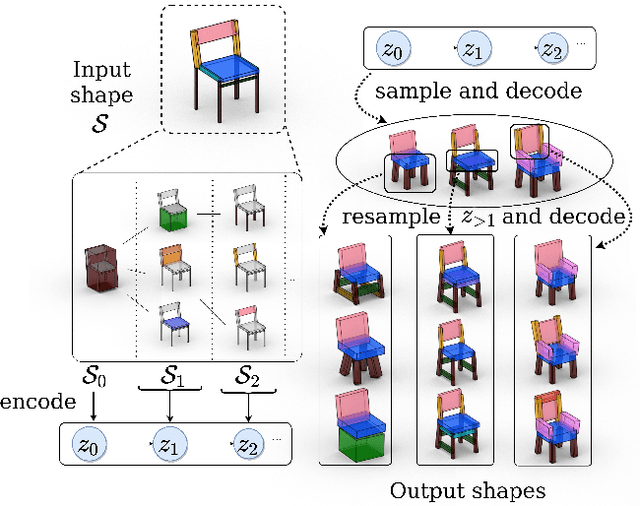
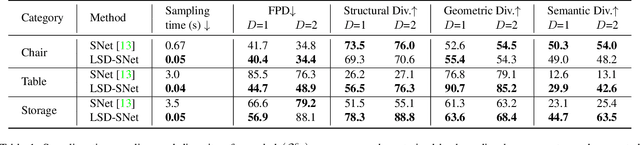
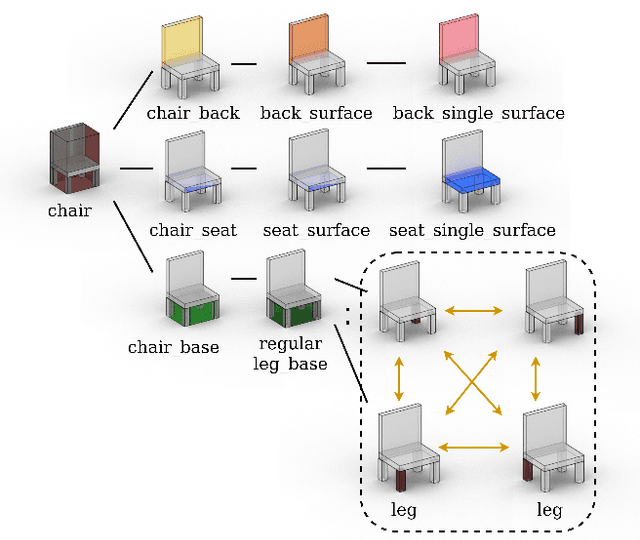
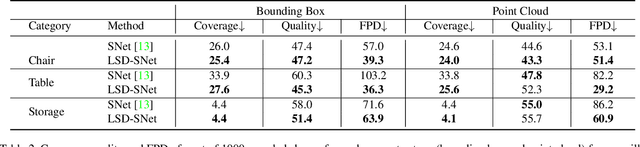
Generative models for 3D shapes represented by hierarchies of parts can generate realistic and diverse sets of outputs. However, existing models suffer from the key practical limitation of modelling shapes holistically and thus cannot perform conditional sampling, i.e. they are not able to generate variants on individual parts of generated shapes without modifying the rest of the shape. This is limiting for applications such as 3D CAD design that involve adjusting created shapes at multiple levels of detail. To address this, we introduce LSD-StructureNet, an augmentation to the StructureNet architecture that enables re-generation of parts situated at arbitrary positions in the hierarchies of its outputs. We achieve this by learning individual, probabilistic conditional decoders for each hierarchy depth. We evaluate LSD-StructureNet on the PartNet dataset, the largest dataset of 3D shapes represented by hierarchies of parts. Our results show that contrarily to existing methods, LSD-StructureNet can perform conditional sampling without impacting inference speed or the realism and diversity of its outputs.
Engineering Sketch Generation for Computer-Aided Design
Apr 19, 2021

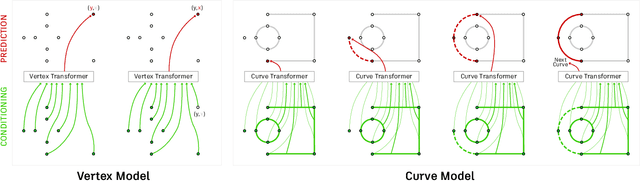

Engineering sketches form the 2D basis of parametric Computer-Aided Design (CAD), the foremost modeling paradigm for manufactured objects. In this paper we tackle the problem of learning based engineering sketch generation as a first step towards synthesis and composition of parametric CAD models. We propose two generative models, CurveGen and TurtleGen, for engineering sketch generation. Both models generate curve primitives without the need for a sketch constraint solver and explicitly consider topology for downstream use with constraints and 3D CAD modeling operations. We find in our perceptual evaluation using human subjects that both CurveGen and TurtleGen produce more realistic engineering sketches when compared with the current state-of-the-art for engineering sketch generation.
House-GAN++: Generative Adversarial Layout Refinement Networks
Mar 03, 2021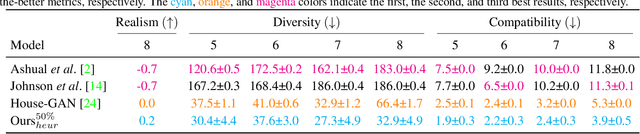
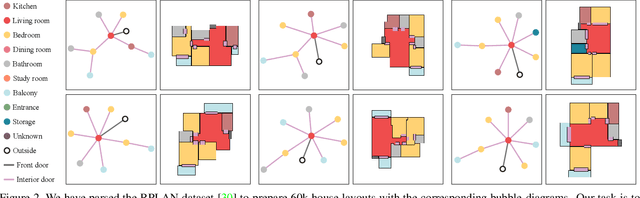
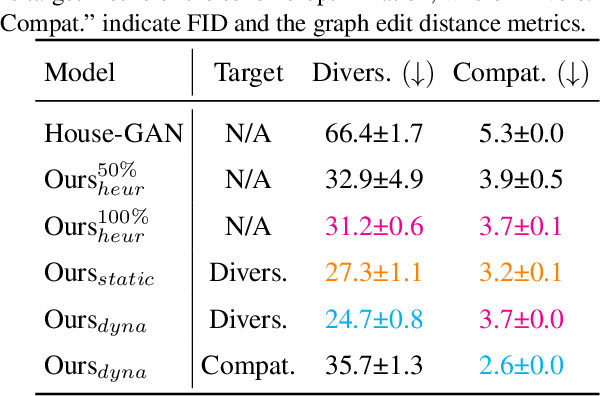
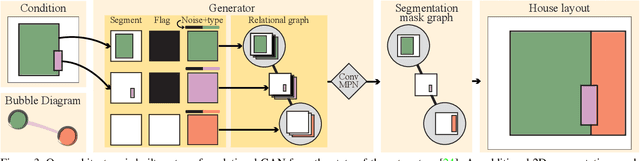
This paper proposes a novel generative adversarial layout refinement network for automated floorplan generation. Our architecture is an integration of a graph-constrained relational GAN and a conditional GAN, where a previously generated layout becomes the next input constraint, enabling iterative refinement. A surprising discovery of our research is that a simple non-iterative training process, dubbed component-wise GT-conditioning, is effective in learning such a generator. The iterative generator also creates a new opportunity in further improving a metric of choice via meta-optimization techniques by controlling when to pass which input constraints during iterative layout refinement. Our qualitative and quantitative evaluation based on the three standard metrics demonstrate that the proposed system makes significant improvements over the current state-of-the-art, even competitive against the ground-truth floorplans, designed by professional architects.
Fusion 360 Gallery: A Dataset and Environment for Programmatic CAD Reconstruction
Oct 05, 2020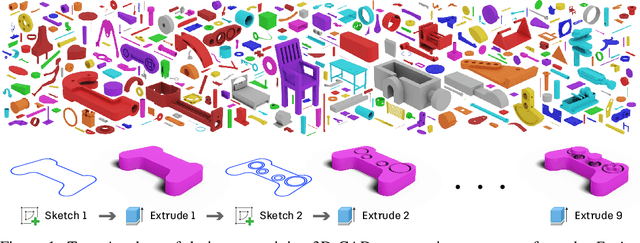

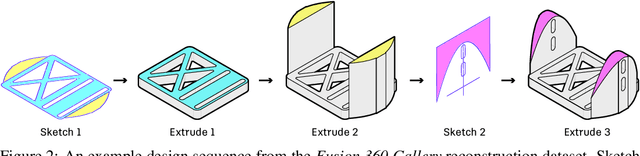
Parametric computer-aided design (CAD) is a standard paradigm used for the design of manufactured objects. CAD designers perform modeling operations, such as sketch and extrude, to form a construction sequence that makes up a final design. Despite the pervasiveness of parametric CAD and growing interest from the research community, a dataset of human designed 3D CAD construction sequences has not been available to-date. In this paper we present the Fusion 360 Gallery reconstruction dataset and environment for learning CAD reconstruction. We provide a dataset of 8,625 designs, comprising sequential sketch and extrude modeling operations, together with a complementary environment called the Fusion 360 Gym, to assist with performing CAD reconstruction. We outline a standard CAD reconstruction task, together with evaluation metrics, and present results from a novel method using neurally guided search to recover a construction sequence from raw geometry.
Expressive Telepresence via Modular Codec Avatars
Aug 26, 2020

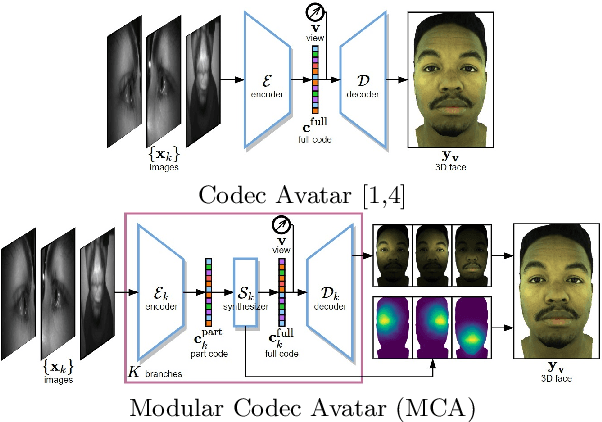
VR telepresence consists of interacting with another human in a virtual space represented by an avatar. Today most avatars are cartoon-like, but soon the technology will allow video-realistic ones. This paper aims in this direction and presents Modular Codec Avatars (MCA), a method to generate hyper-realistic faces driven by the cameras in the VR headset. MCA extends traditional Codec Avatars (CA) by replacing the holistic models with a learned modular representation. It is important to note that traditional person-specific CAs are learned from few training samples, and typically lack robustness as well as limited expressiveness when transferring facial expressions. MCAs solve these issues by learning a modulated adaptive blending of different facial components as well as an exemplar-based latent alignment. We demonstrate that MCA achieves improved expressiveness and robustness w.r.t to CA in a variety of real-world datasets and practical scenarios. Finally, we showcase new applications in VR telepresence enabled by the proposed model.
Learning to Generate Diverse Dance Motions with Transformer
Aug 18, 2020
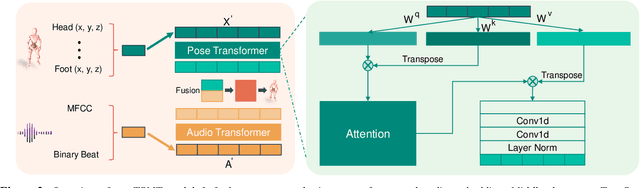

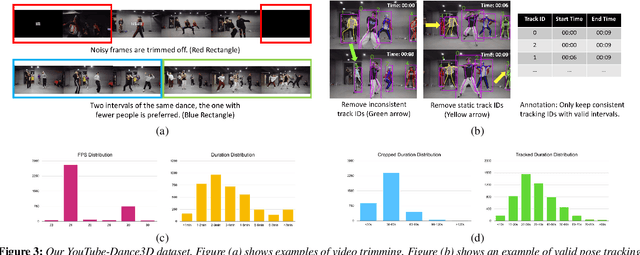
With the ongoing pandemic, virtual concerts and live events using digitized performances of musicians are getting traction on massive multiplayer online worlds. However, well choreographed dance movements are extremely complex to animate and would involve an expensive and tedious production process. In addition to the use of complex motion capture systems, it typically requires a collaborative effort between animators, dancers, and choreographers. We introduce a complete system for dance motion synthesis, which can generate complex and highly diverse dance sequences given an input music sequence. As motion capture data is limited for the range of dance motions and styles, we introduce a massive dance motion data set that is created from YouTube videos. We also present a novel two-stream motion transformer generative model, which can generate motion sequences with high flexibility. We also introduce new evaluation metrics for the quality of synthesized dance motions, and demonstrate that our system can outperform state-of-the-art methods. Our system provides high-quality animations suitable for large crowds for virtual concerts and can also be used as reference for professional animation pipelines. Most importantly, we show that vast online videos can be effective in training dance motion models.
Neural Turtle Graphics for Modeling City Road Layouts
Oct 04, 2019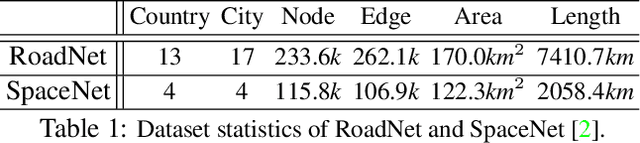
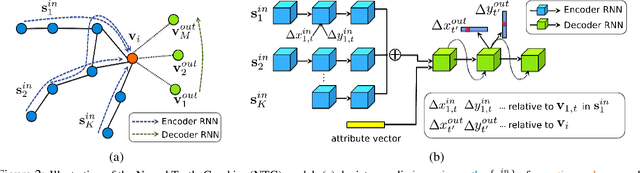
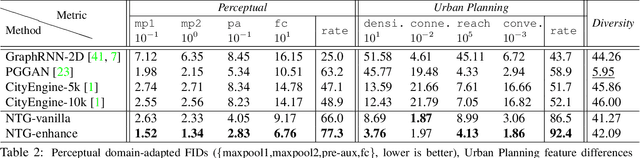

We propose Neural Turtle Graphics (NTG), a novel generative model for spatial graphs, and demonstrate its applications in modeling city road layouts. Specifically, we represent the road layout using a graph where nodes in the graph represent control points and edges in the graph represent road segments. NTG is a sequential generative model parameterized by a neural network. It iteratively generates a new node and an edge connecting to an existing node conditioned on the current graph. We train NTG on Open Street Map data and show that it outperforms existing approaches using a set of diverse performance metrics. Moreover, our method allows users to control styles of generated road layouts mimicking existing cities as well as to sketch parts of the city road layout to be synthesized. In addition to synthesis, the proposed NTG finds uses in an analytical task of aerial road parsing. Experimental results show that it achieves state-of-the-art performance on the SpaceNet dataset.