 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgee-SimFT: Alignment of Generative Models with Simulation Feedback for Pareto-Front Design Exploration
Feb 04, 2025



Deep generative models have recently shown success in solving complex engineering design problems where models predict solutions that address the design requirements specified as input. However, there remains a challenge in aligning such models for effective design exploration. For many design problems, finding a solution that meets all the requirements is infeasible. In such a case, engineers prefer to obtain a set of Pareto optimal solutions with respect to those requirements, but uniform sampling of generative models may not yield a useful Pareto front. To address this gap, we introduce a new framework for Pareto-front design exploration with simulation fine-tuned generative models. First, the framework adopts preference alignment methods developed for Large Language Models (LLMs) and showcases the first application in fine-tuning a generative model for engineering design. The important distinction here is that we use a simulator instead of humans to provide accurate and scalable feedback. Next, we propose epsilon-sampling, inspired by the epsilon-constraint method used for Pareto-front generation with classical optimization algorithms, to construct a high-quality Pareto front with the fine-tuned models. Our framework, named e-SimFT, is shown to produce better-quality Pareto fronts than existing multi-objective alignment methods.
Synthetic Vision: Training Vision-Language Models to Understand Physics
Dec 11, 2024



Physical reasoning, which involves the interpretation, understanding, and prediction of object behavior in dynamic environments, remains a significant challenge for current Vision-Language Models (VLMs). In this work, we propose two methods to enhance VLMs' physical reasoning capabilities using simulated data. First, we fine-tune a pre-trained VLM using question-answer (QA) pairs generated from simulations relevant to physical reasoning tasks. Second, we introduce Physics Context Builders (PCBs), specialized VLMs fine-tuned to create scene descriptions enriched with physical properties and processes. During physical reasoning tasks, these PCBs can be leveraged as context to assist a Large Language Model (LLM) to improve its performance. We evaluate both of our approaches using multiple benchmarks, including a new stability detection QA dataset called Falling Tower, which includes both simulated and real-world scenes, and CLEVRER. We demonstrate that a small QA fine-tuned VLM can significantly outperform larger state-of-the-art foundational models. We also show that integrating PCBs boosts the performance of foundational LLMs on physical reasoning tasks. Using the real-world scenes from the Falling Tower dataset, we also validate the robustness of both approaches in Sim2Real transfer. Our results highlight the utility that simulated data can have in the creation of learning systems capable of advanced physical reasoning.
TextCraft: Zero-Shot Generation of High-Fidelity and Diverse Shapes from Text
Nov 04, 2022



Language is one of the primary means by which we describe the 3D world around us. While rapid progress has been made in text-to-2D-image synthesis, similar progress in text-to-3D-shape synthesis has been hindered by the lack of paired (text, shape) data. Moreover, extant methods for text-to-shape generation have limited shape diversity and fidelity. We introduce TextCraft, a method to address these limitations by producing high-fidelity and diverse 3D shapes without the need for (text, shape) pairs for training. TextCraft achieves this by using CLIP and using a multi-resolution approach by first generating in a low-dimensional latent space and then upscaling to a higher resolution, improving the fidelity of the generated shape. To improve shape diversity, we use a discrete latent space which is modelled using a bidirectional transformer conditioned on the interchangeable image-text embedding space induced by CLIP. Moreover, we present a novel variant of classifier-free guidance, which further improves the accuracy-diversity trade-off. Finally, we perform extensive experiments that demonstrate that TextCraft outperforms state-of-the-art baselines.
SimCURL: Simple Contrastive User Representation Learning from Command Sequences
Jul 29, 2022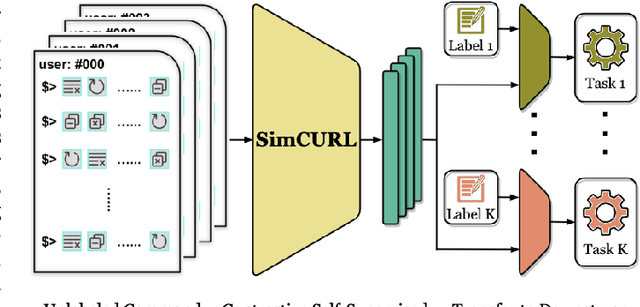

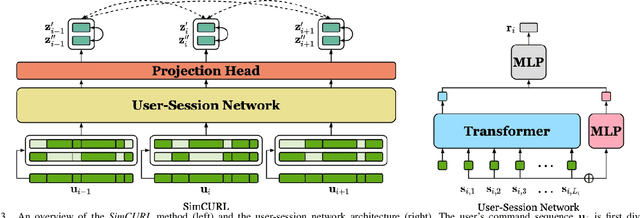

User modeling is crucial to understanding user behavior and essential for improving user experience and personalized recommendations. When users interact with software, vast amounts of command sequences are generated through logging and analytics systems. These command sequences contain clues to the users' goals and intents. However, these data modalities are highly unstructured and unlabeled, making it difficult for standard predictive systems to learn from. We propose SimCURL, a simple yet effective contrastive self-supervised deep learning framework that learns user representation from unlabeled command sequences. Our method introduces a user-session network architecture, as well as session dropout as a novel way of data augmentation. We train and evaluate our method on a real-world command sequence dataset of more than half a billion commands. Our method shows significant improvement over existing methods when the learned representation is transferred to downstream tasks such as experience and expertise classification.
Learning Graph Augmentations to Learn Graph Representations
Jan 24, 2022



Devising augmentations for graph contrastive learning is challenging due to their irregular structure, drastic distribution shifts, and nonequivalent feature spaces across datasets. We introduce LG2AR, Learning Graph Augmentations to Learn Graph Representations, which is an end-to-end automatic graph augmentation framework that helps encoders learn generalizable representations on both node and graph levels. LG2AR consists of a probabilistic policy that learns a distribution over augmentations and a set of probabilistic augmentation heads that learn distributions over augmentation parameters. We show that LG2AR achieves state-of-the-art results on 18 out of 20 graph-level and node-level benchmarks compared to previous unsupervised models under both linear and semi-supervised evaluation protocols. The source code will be released here: https://github.com/kavehhassani/lg2ar
Group-disentangled Representation Learning with Weakly-Supervised Regularization
Oct 23, 2021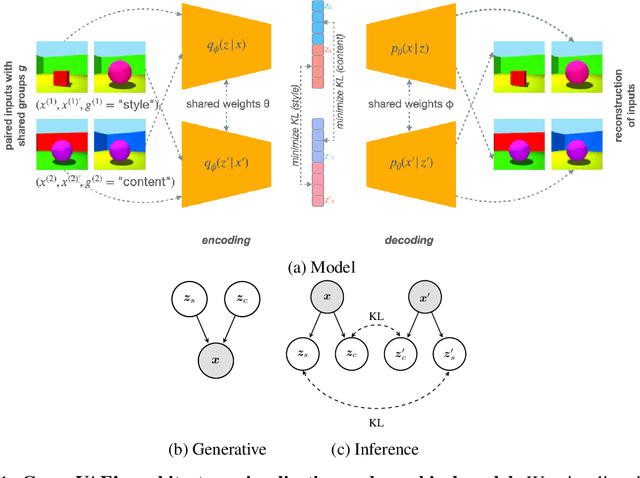
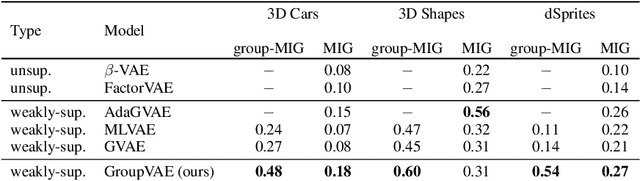
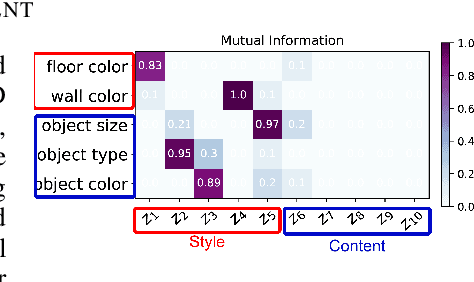
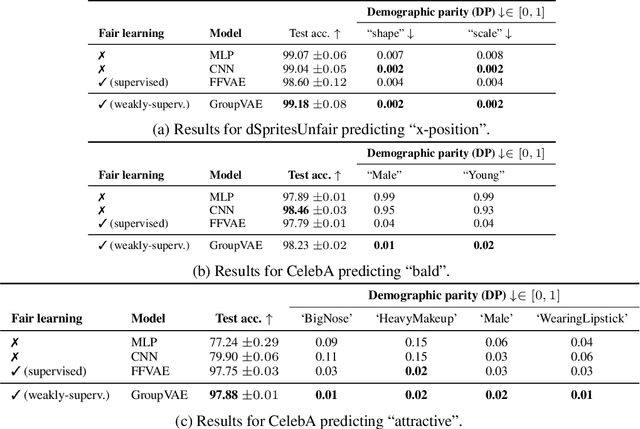
Learning interpretable and human-controllable representations that uncover factors of variation in data remains an ongoing key challenge in representation learning. We investigate learning group-disentangled representations for groups of factors with weak supervision. Existing techniques to address this challenge merely constrain the approximate posterior by averaging over observations of a shared group. As a result, observations with a common set of variations are encoded to distinct latent representations, reducing their capacity to disentangle and generalize to downstream tasks. In contrast to previous works, we propose GroupVAE, a simple yet effective Kullback-Leibler (KL) divergence-based regularization across shared latent representations to enforce consistent and disentangled representations. We conduct a thorough evaluation and demonstrate that our GroupVAE significantly improves group disentanglement. Further, we demonstrate that learning group-disentangled representations improve upon downstream tasks, including fair classification and 3D shape-related tasks such as reconstruction, classification, and transfer learning, and is competitive to supervised methods.
PointMask: Towards Interpretable and Bias-Resilient Point Cloud Processing
Jul 09, 2020

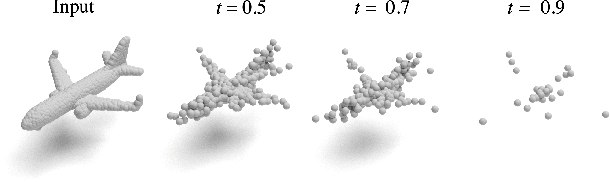

Deep classifiers tend to associate a few discriminative input variables with their objective function, which in turn, may hurt their generalization capabilities. To address this, one can design systematic experiments and/or inspect the models via interpretability methods. In this paper, we investigate both of these strategies on deep models operating on point clouds. We propose PointMask, a model-agnostic interpretable information-bottleneck approach for attribution in point cloud models. PointMask encourages exploring the majority of variation factors in the input space while gradually converging to a general solution. More specifically, PointMask introduces a regularization term that minimizes the mutual information between the input and the latent features used to masks out irrelevant variables. We show that coupling a PointMask layer with an arbitrary model can discern the points in the input space which contribute the most to the prediction score, thereby leading to interpretability. Through designed bias experiments, we also show that thanks to its gradual masking feature, our proposed method is effective in handling data bias.
Contrastive Multi-View Representation Learning on Graphs
Jun 10, 2020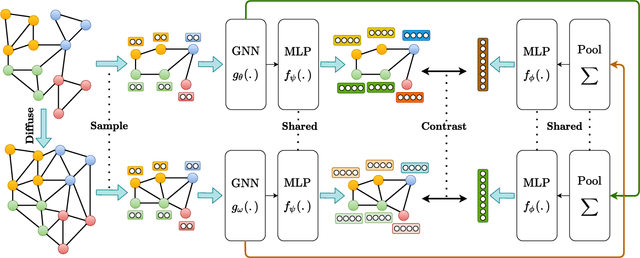
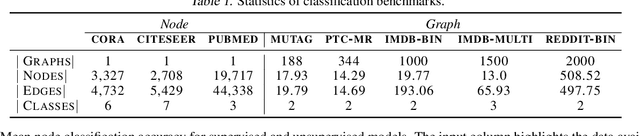

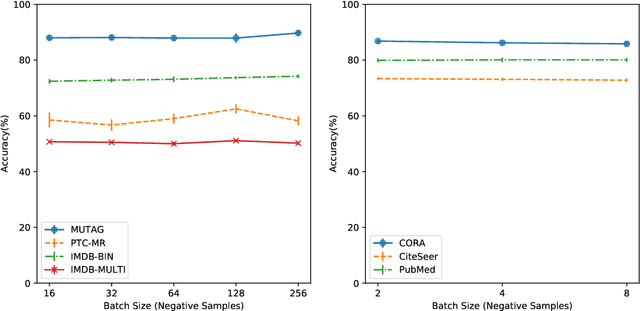
We introduce a self-supervised approach for learning node and graph level representations by contrasting structural views of graphs. We show that unlike visual representation learning, increasing the number of views to more than two or contrasting multi-scale encodings do not improve performance, and the best performance is achieved by contrasting encodings from first-order neighbors and a graph diffusion. We achieve new state-of-the-art results in self-supervised learning on 8 out of 8 node and graph classification benchmarks under the linear evaluation protocol. For example, on Cora (node) and Reddit-Binary (graph) classification benchmarks, we achieve 86.8% and 84.5% accuracy, which are 5.5% and 2.4% relative improvements over previous state-of-the-art. When compared to supervised baselines, our approach outperforms them in 4 out of 8 benchmarks. Source code is released at: https://github.com/kavehhassani/mvgrl
Memory-Based Graph Networks
Feb 21, 2020



Graph neural networks (GNNs) are a class of deep models that operate on data with arbitrary topology represented as graphs. We introduce an efficient memory layer for GNNs that can jointly learn node representations and coarsen the graph. We also introduce two new networks based on this layer: memory-based GNN (MemGNN) and graph memory network (GMN) that can learn hierarchical graph representations. The experimental results shows that the proposed models achieve state-of-the-art results in eight out of nine graph classification and regression benchmarks. We also show that the learned representations could correspond to chemical features in the molecule data. Code and reference implementations are released at: https://github.com/amirkhas/GraphMemoryNet