 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCadVLM: Bridging Language and Vision in the Generation of Parametric CAD Sketches
Sep 26, 2024



Parametric Computer-Aided Design (CAD) is central to contemporary mechanical design. However, it encounters challenges in achieving precise parametric sketch modeling and lacks practical evaluation metrics suitable for mechanical design. We harness the capabilities of pre-trained foundation models, renowned for their successes in natural language processing and computer vision, to develop generative models specifically for CAD. These models are adept at understanding complex geometries and design reasoning, a crucial advancement in CAD technology. In this paper, we propose CadVLM, an end-to-end vision language model for CAD generation. Our approach involves adapting pre-trained foundation models to manipulate engineering sketches effectively, integrating both sketch primitive sequences and sketch images. Extensive experiments demonstrate superior performance on multiple CAD sketch generation tasks such as CAD autocompletion, CAD autoconstraint, and image conditional generation. To our knowledge, this is the first instance of a multimodal Large Language Model (LLM) being successfully applied to parametric CAD generation, representing a pioneering step in the field of computer-aided mechanical design.
TextCraft: Zero-Shot Generation of High-Fidelity and Diverse Shapes from Text
Nov 04, 2022



Language is one of the primary means by which we describe the 3D world around us. While rapid progress has been made in text-to-2D-image synthesis, similar progress in text-to-3D-shape synthesis has been hindered by the lack of paired (text, shape) data. Moreover, extant methods for text-to-shape generation have limited shape diversity and fidelity. We introduce TextCraft, a method to address these limitations by producing high-fidelity and diverse 3D shapes without the need for (text, shape) pairs for training. TextCraft achieves this by using CLIP and using a multi-resolution approach by first generating in a low-dimensional latent space and then upscaling to a higher resolution, improving the fidelity of the generated shape. To improve shape diversity, we use a discrete latent space which is modelled using a bidirectional transformer conditioned on the interchangeable image-text embedding space induced by CLIP. Moreover, we present a novel variant of classifier-free guidance, which further improves the accuracy-diversity trade-off. Finally, we perform extensive experiments that demonstrate that TextCraft outperforms state-of-the-art baselines.
Mates2Motion: Learning How Mechanical CAD Assemblies Work
Aug 02, 2022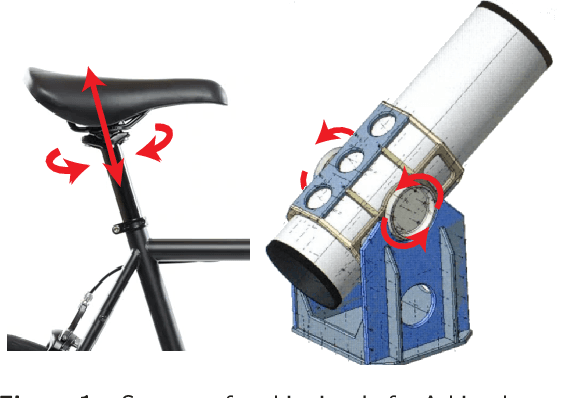
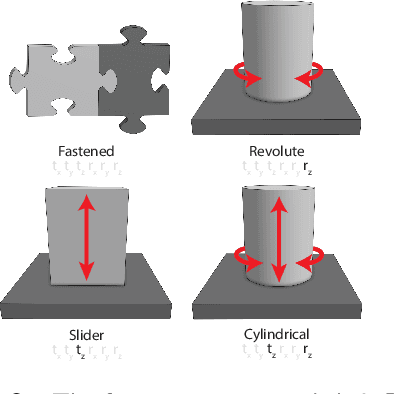
We describe our work on inferring the degrees of freedom between mated parts in mechanical assemblies using deep learning on CAD representations. We train our model using a large dataset of real-world mechanical assemblies consisting of CAD parts and mates joining them together. We present methods for re-defining these mates to make them better reflect the motion of the assembly, as well as narrowing down the possible axes of motion. We also conduct a user study to create a motion-annotated test set with more reliable labels.