 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelet Latent Diffusion (Wala): Billion-Parameter 3D Generative Model with Compact Wavelet Encodings
Nov 12, 2024



Large-scale 3D generative models require substantial computational resources yet often fall short in capturing fine details and complex geometries at high resolutions. We attribute this limitation to the inefficiency of current representations, which lack the compactness required to model the generative models effectively. To address this, we introduce a novel approach called Wavelet Latent Diffusion, or WaLa, that encodes 3D shapes into wavelet-based, compact latent encodings. Specifically, we compress a $256^3$ signed distance field into a $12^3 \times 4$ latent grid, achieving an impressive 2427x compression ratio with minimal loss of detail. This high level of compression allows our method to efficiently train large-scale generative networks without increasing the inference time. Our models, both conditional and unconditional, contain approximately one billion parameters and successfully generate high-quality 3D shapes at $256^3$ resolution. Moreover, WaLa offers rapid inference, producing shapes within two to four seconds depending on the condition, despite the model's scale. We demonstrate state-of-the-art performance across multiple datasets, with significant improvements in generation quality, diversity, and computational efficiency. We open-source our code and, to the best of our knowledge, release the largest pretrained 3D generative models across different modalities.
Make-A-Shape: a Ten-Million-scale 3D Shape Model
Jan 20, 2024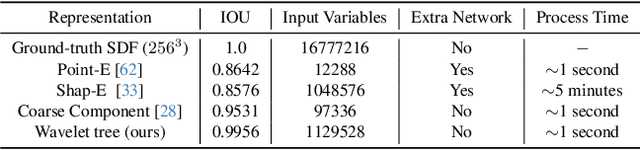

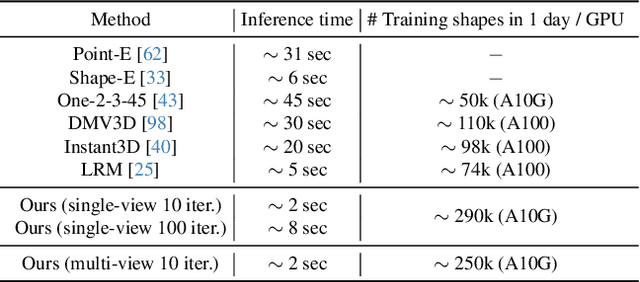
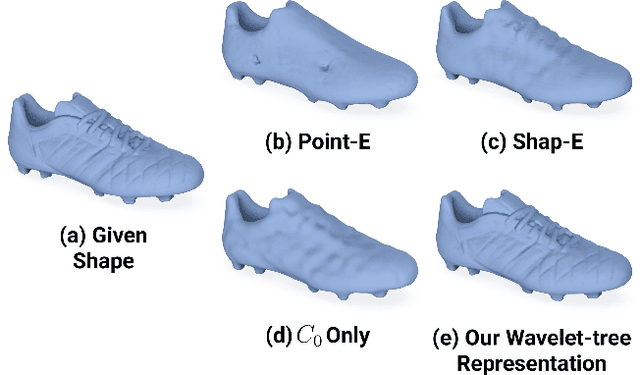
Significant progress has been made in training large generative models for natural language and images. Yet, the advancement of 3D generative models is hindered by their substantial resource demands for training, along with inefficient, non-compact, and less expressive representations. This paper introduces Make-A-Shape, a new 3D generative model designed for efficient training on a vast scale, capable of utilizing 10 millions publicly-available shapes. Technical-wise, we first innovate a wavelet-tree representation to compactly encode shapes by formulating the subband coefficient filtering scheme to efficiently exploit coefficient relations. We then make the representation generatable by a diffusion model by devising the subband coefficients packing scheme to layout the representation in a low-resolution grid. Further, we derive the subband adaptive training strategy to train our model to effectively learn to generate coarse and detail wavelet coefficients. Last, we extend our framework to be controlled by additional input conditions to enable it to generate shapes from assorted modalities, e.g., single/multi-view images, point clouds, and low-resolution voxels. In our extensive set of experiments, we demonstrate various applications, such as unconditional generation, shape completion, and conditional generation on a wide range of modalities. Our approach not only surpasses the state of the art in delivering high-quality results but also efficiently generates shapes within a few seconds, often achieving this in just 2 seconds for most conditions.
SLiMe: Segment Like Me
Sep 06, 2023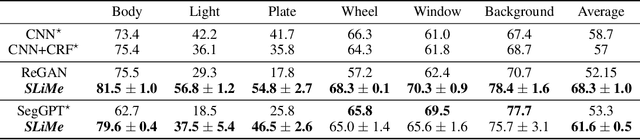

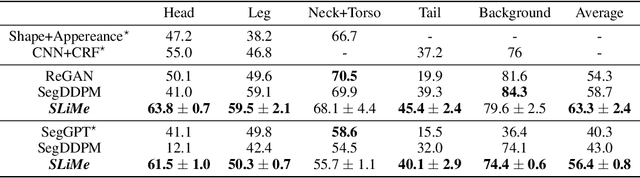

Significant strides have been made using large vision-language models, like Stable Diffusion (SD), for a variety of downstream tasks, including image editing, image correspondence, and 3D shape generation. Inspired by these advancements, we explore leveraging these extensive vision-language models for segmenting images at any desired granularity using as few as one annotated sample by proposing SLiMe. SLiMe frames this problem as an optimization task. Specifically, given a single training image and its segmentation mask, we first extract attention maps, including our novel "weighted accumulated self-attention map" from the SD prior. Then, using the extracted attention maps, the text embeddings of Stable Diffusion are optimized such that, each of them, learn about a single segmented region from the training image. These learned embeddings then highlight the segmented region in the attention maps, which in turn can then be used to derive the segmentation map. This enables SLiMe to segment any real-world image during inference with the granularity of the segmented region in the training image, using just one example. Moreover, leveraging additional training data when available, i.e. few-shot, improves the performance of SLiMe. We carried out a knowledge-rich set of experiments examining various design factors and showed that SLiMe outperforms other existing one-shot and few-shot segmentation methods.
Learned Visual Features to Textual Explanations
Sep 01, 2023Interpreting the learned features of vision models has posed a longstanding challenge in the field of machine learning. To address this issue, we propose a novel method that leverages the capabilities of large language models (LLMs) to interpret the learned features of pre-trained image classifiers. Our method, called TExplain, tackles this task by training a neural network to establish a connection between the feature space of image classifiers and LLMs. Then, during inference, our approach generates a vast number of sentences to explain the features learned by the classifier for a given image. These sentences are then used to extract the most frequent words, providing a comprehensive understanding of the learned features and patterns within the classifier. Our method, for the first time, utilizes these frequent words corresponding to a visual representation to provide insights into the decision-making process of the independently trained classifier, enabling the detection of spurious correlations, biases, and a deeper comprehension of its behavior. To validate the effectiveness of our approach, we conduct experiments on diverse datasets, including ImageNet-9L and Waterbirds. The results demonstrate the potential of our method to enhance the interpretability and robustness of image classifiers.
Sketch-A-Shape: Zero-Shot Sketch-to-3D Shape Generation
Jul 08, 2023



Significant progress has recently been made in creative applications of large pre-trained models for downstream tasks in 3D vision, such as text-to-shape generation. This motivates our investigation of how these pre-trained models can be used effectively to generate 3D shapes from sketches, which has largely remained an open challenge due to the limited sketch-shape paired datasets and the varying level of abstraction in the sketches. We discover that conditioning a 3D generative model on the features (obtained from a frozen large pre-trained vision model) of synthetic renderings during training enables us to effectively generate 3D shapes from sketches at inference time. This suggests that the large pre-trained vision model features carry semantic signals that are resilient to domain shifts, i.e., allowing us to use only RGB renderings, but generalizing to sketches at inference time. We conduct a comprehensive set of experiments investigating different design factors and demonstrate the effectiveness of our straightforward approach for generation of multiple 3D shapes per each input sketch regardless of their level of abstraction without requiring any paired datasets during training.
TextCraft: Zero-Shot Generation of High-Fidelity and Diverse Shapes from Text
Nov 04, 2022



Language is one of the primary means by which we describe the 3D world around us. While rapid progress has been made in text-to-2D-image synthesis, similar progress in text-to-3D-shape synthesis has been hindered by the lack of paired (text, shape) data. Moreover, extant methods for text-to-shape generation have limited shape diversity and fidelity. We introduce TextCraft, a method to address these limitations by producing high-fidelity and diverse 3D shapes without the need for (text, shape) pairs for training. TextCraft achieves this by using CLIP and using a multi-resolution approach by first generating in a low-dimensional latent space and then upscaling to a higher resolution, improving the fidelity of the generated shape. To improve shape diversity, we use a discrete latent space which is modelled using a bidirectional transformer conditioned on the interchangeable image-text embedding space induced by CLIP. Moreover, we present a novel variant of classifier-free guidance, which further improves the accuracy-diversity trade-off. Finally, we perform extensive experiments that demonstrate that TextCraft outperforms state-of-the-art baselines.
Reconstructing editable prismatic CAD from rounded voxel models
Sep 02, 2022
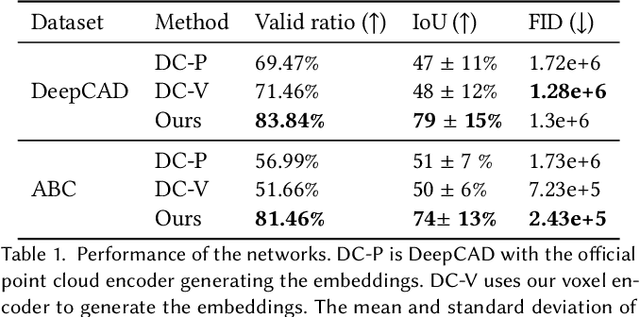
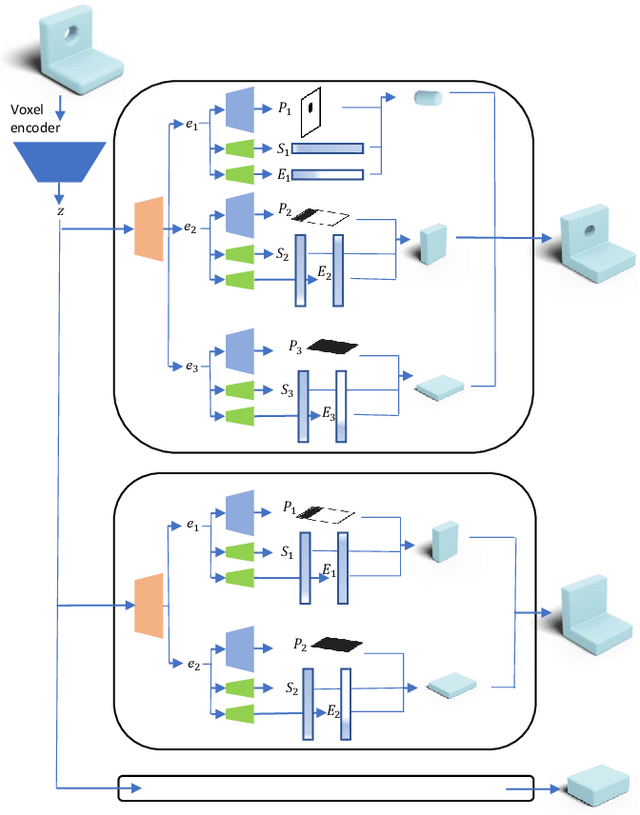
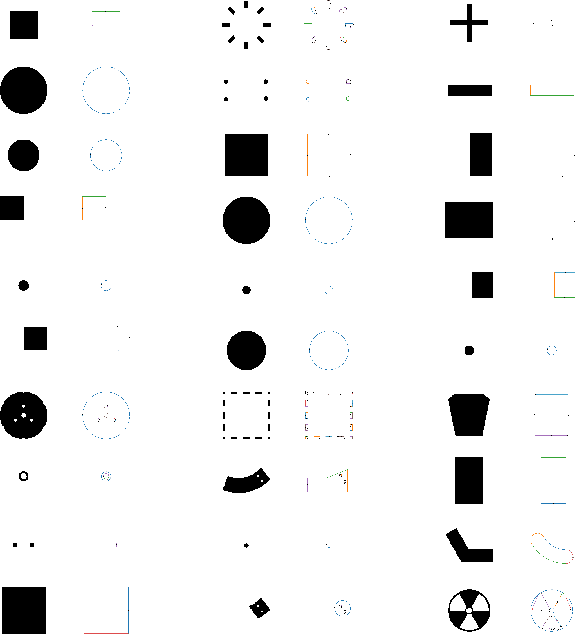
Reverse Engineering a CAD shape from other representations is an important geometric processing step for many downstream applications. In this work, we introduce a novel neural network architecture to solve this challenging task and approximate a smoothed signed distance function with an editable, constrained, prismatic CAD model. During training, our method reconstructs the input geometry in the voxel space by decomposing the shape into a series of 2D profile images and 1D envelope functions. These can then be recombined in a differentiable way allowing a geometric loss function to be defined. During inference, we obtain the CAD data by first searching a database of 2D constrained sketches to find curves which approximate the profile images, then extrude them and use Boolean operations to build the final CAD model. Our method approximates the target shape more closely than other methods and outputs highly editable constrained parametric sketches which are compatible with existing CAD software.
SolidGen: An Autoregressive Model for Direct B-rep Synthesis
Mar 26, 2022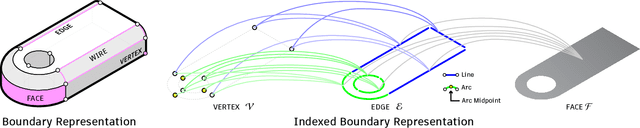
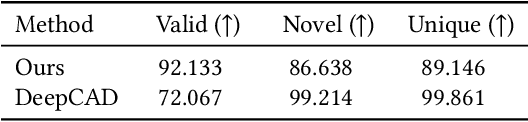
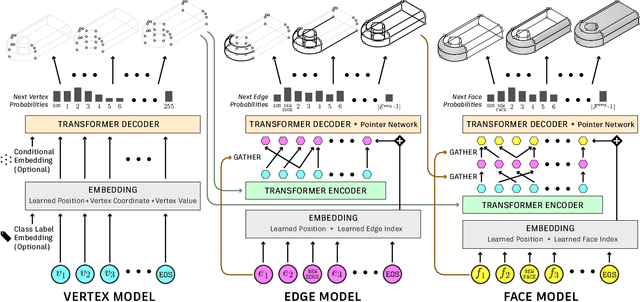

The Boundary representation (B-rep) format is the de-facto shape representation in computer-aided design (CAD) to model watertight solid objects. Recent approaches to generating CAD models have focused on learning sketch-and-extrude modeling sequences that are executed by a solid modeling kernel in postprocess to recover a B-rep. In this paper we present a new approach that enables learning from and synthesizing B-reps without the need for supervision through CAD modeling sequence data. Our method SolidGen, is an autoregressive neural network that models the B-rep directly by predicting the vertices, edges and faces using Transformer-based and pointer neural networks. Key to achieving this is our Indexed Boundary Representation that references B-rep vertices, edges and faces in a well-defined hierarchy to capture the geometric and topological relations suitable for use with machine learning. SolidGen can be easily conditioned on contexts e.g., class labels thanks to its probabilistic modeling of the B-rep distribution. We demonstrate qualitatively, quantitatively and through perceptual evaluation by human subjects that SolidGen can produce high quality, realistic looking CAD models.
UNIST: Unpaired Neural Implicit Shape Translation Network
Dec 10, 2021
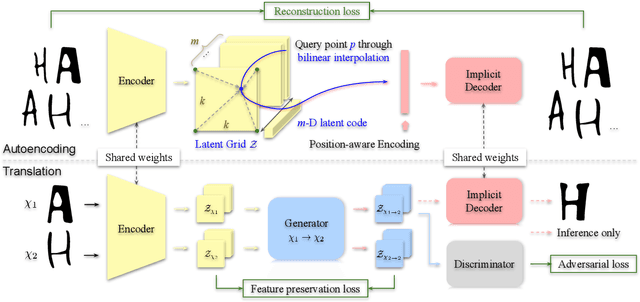
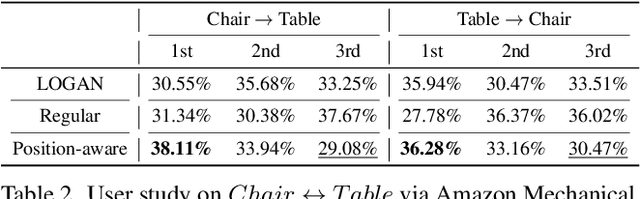
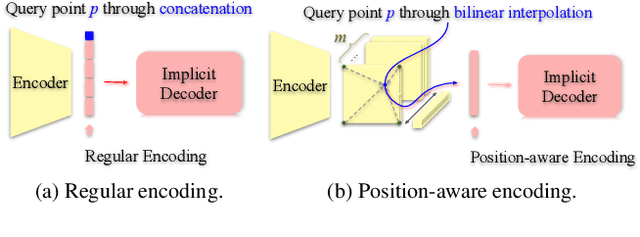
We introduce UNIST, the first deep neural implicit model for general-purpose, unpaired shape-to-shape translation, in both 2D and 3D domains. Our model is built on autoencoding implicit fields, rather than point clouds which represents the state of the art. Furthermore, our translation network is trained to perform the task over a latent grid representation which combines the merits of both latent-space processing and position awareness, to not only enable drastic shape transforms but also well preserve spatial features and fine local details for natural shape translations. With the same network architecture and only dictated by the input domain pairs, our model can learn both style-preserving content alteration and content-preserving style transfer. We demonstrate the generality and quality of the translation results, and compare them to well-known baselines.
JoinABLe: Learning Bottom-up Assembly of Parametric CAD Joints
Nov 24, 2021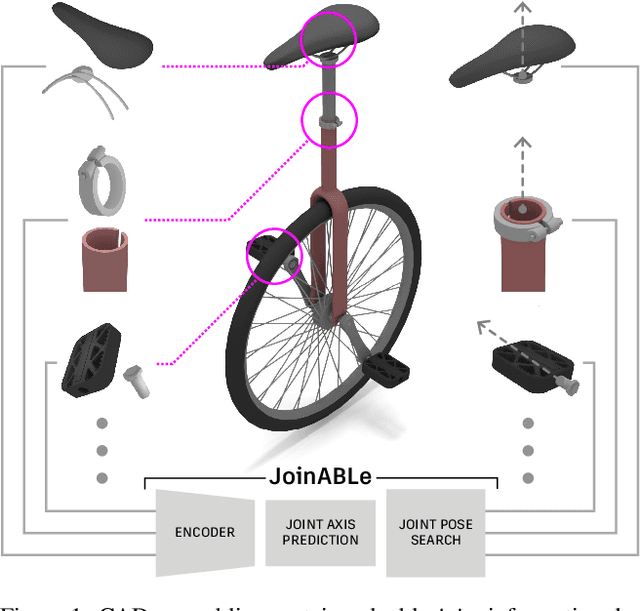
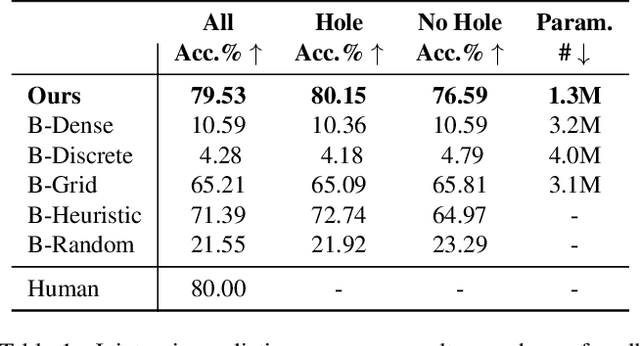
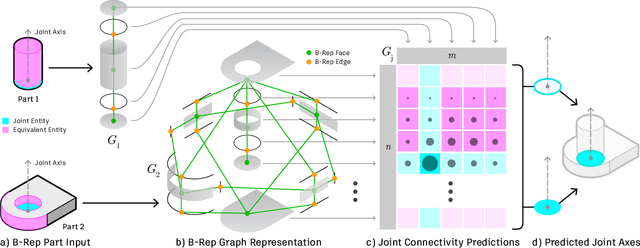
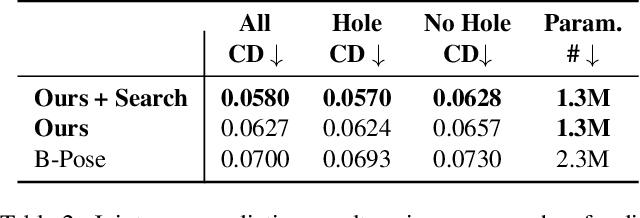
Physical products are often complex assemblies combining a multitude of 3D parts modeled in computer-aided design (CAD) software. CAD designers build up these assemblies by aligning individual parts to one another using constraints called joints. In this paper we introduce JoinABLe, a learning-based method that assembles parts together to form joints. JoinABLe uses the weak supervision available in standard parametric CAD files without the help of object class labels or human guidance. Our results show that by making network predictions over a graph representation of solid models we can outperform multiple baseline methods with an accuracy (79.53%) that approaches human performance (80%). Finally, to support future research we release the Fusion 360 Gallery assembly dataset, containing assemblies with rich information on joints, contact surfaces, holes, and the underlying assembly graph structure.