 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake-A-Shape: a Ten-Million-scale 3D Shape Model
Paper and Code
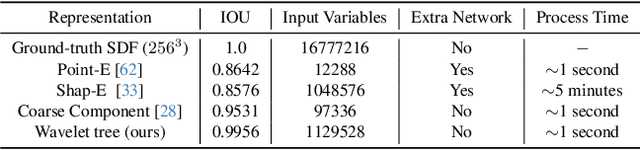

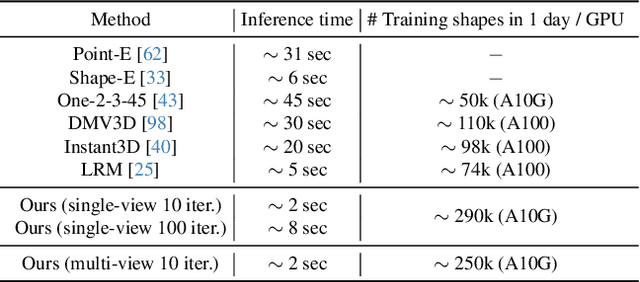
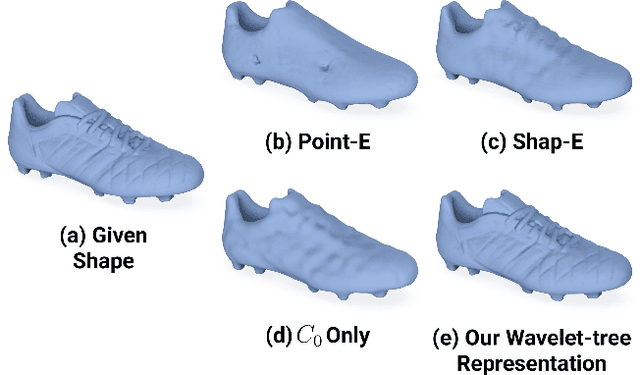
Significant progress has been made in training large generative models for natural language and images. Yet, the advancement of 3D generative models is hindered by their substantial resource demands for training, along with inefficient, non-compact, and less expressive representations. This paper introduces Make-A-Shape, a new 3D generative model designed for efficient training on a vast scale, capable of utilizing 10 millions publicly-available shapes. Technical-wise, we first innovate a wavelet-tree representation to compactly encode shapes by formulating the subband coefficient filtering scheme to efficiently exploit coefficient relations. We then make the representation generatable by a diffusion model by devising the subband coefficients packing scheme to layout the representation in a low-resolution grid. Further, we derive the subband adaptive training strategy to train our model to effectively learn to generate coarse and detail wavelet coefficients. Last, we extend our framework to be controlled by additional input conditions to enable it to generate shapes from assorted modalities, e.g., single/multi-view images, point clouds, and low-resolution voxels. In our extensive set of experiments, we demonstrate various applications, such as unconditional generation, shape completion, and conditional generation on a wide range of modalities. Our approach not only surpasses the state of the art in delivering high-quality results but also efficiently generates shapes within a few seconds, often achieving this in just 2 seconds for most conditions.