 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Active Perception as Reasoning for Omni-Modal Understanding
Jun 17, 2026Passive models for long video understanding typically rely on a "watch-it-all" paradigm, processing frames uniformly regardless of query difficulty, causing computational cost to grow with video duration. Although interactive frameworks have emerged, they often rely on global pre-scanning, and their context cost still scales with video length. We propose OmniAgent, the first native omni-modal agent that formulates video understanding as a POMDP-based iterative Observation-Thought-Action cycle. OmniAgent executes on-demand actions to selectively distill audio-visual cues into a persistent textual memory, effectively decoupling reasoning complexity from raw video duration. To operationalize this, we introduce (1) Agentic Supervised Fine-Tuning to bootstrap native active perception via best-of-N trajectory synthesis with dual-stage quality control, and (2) Agentic Reinforcement Learning with TAURA (Turn-aware Adaptive Uncertainty Rescaled Advantage), which leverages turn-level entropy to steer credit assignment toward pivotal discovery turns. Crucially, OmniAgent exhibits positive test-time scaling, where performance improves as the number of reasoning turns increases, validating the efficacy of active perception. Empirical results across ten benchmarks (e.g., VideoMME, LVBench) demonstrate that OmniAgent achieves state-of-the-art performance among open-source models. Notably, on LVBench, our 7B agent outperforms the 10$\times$ larger Qwen2.5-VL-72B (50.5% vs. 47.3%).
EPS3D: End-to-End Feed-Forward 3D Panoptic Segmentation
Jun 08, 2026This paper introduces EPS3D, a new end-to-end feed-forward framework for open-vocabulary 3D panoptic segmentation. Unlike existing methods relying on additional preprocessing, we design an end-to-end architecture, with a distillation-based training strategy on diverse 3D scenes to predict 3D-aware semantic and instance features from multi-view images, improving 3D consistency and avoiding error accumulation. We further propose a mutual enhancement module to enforce inherent semantic-instance consistency. By aligning semantics within instances (Ins2Sem) and refining instance features with semantic guidance (Sem2Ins), we achieve more coherent 3D scene understanding. Ultimately, EPS3D outperforms SOTA baselines on two benchmarks (e.g., +13% mIoU for semantics on Replica) with high efficiency (e.g., 1s per scene), supporting tasks like robotic manipulation and 3D scene editing.
CHOIR: Contact-aware 4D Hand-Object Interaction Reconstruction
May 21, 2026We ask whether everyday open-world monocular videos can be turned into reusable 4D interaction primitives: articulated hand motion, object shape with 6D pose over time, and the when/where of contact. Such a capability would enable scalable mining of real interactions and, beyond reconstruction, support scene-aware synthesis and planning. However, reconstructing hand-object interaction (HOI) from challenging monocular videos remains difficult: methods often assume known objects or curated scenes, and separately estimated hands and objects easily become misaligned under clutter, occlusion, and unseen object geometries. Targeting this setting, we present CHOIR, a Contact-aware HOI Reconstruction framework for a monocular camera, using contact as an explicit coupling signal between hands and objects. CHOIR first initializes a coarse, contact-agnostic 4D HOI sequence from open-world visual priors. It then introduces a generative HOI spatial rectification module to predict ray-depth corrections and rectify hand-object relative placement, then derive initial per-frame contact correspondences on the rectified geometry. Last, a contact-aware joint optimization with dynamically updated contact constraints enforces geometric, temporal, and contact consistency. Experiments on controlled and challenging videos show that CHOIR improves object reconstruction, physical plausibility, and temporal consistency over state-of-the-art methods.
OmniShow: Unifying Multimodal Conditions for Human-Object Interaction Video Generation
Apr 13, 2026In this work, we study Human-Object Interaction Video Generation (HOIVG), which aims to synthesize high-quality human-object interaction videos conditioned on text, reference images, audio, and pose. This task holds significant practical value for automating content creation in real-world applications, such as e-commerce demonstrations, short video production, and interactive entertainment. However, existing approaches fail to accommodate all these requisite conditions. We present OmniShow, an end-to-end framework tailored for this practical yet challenging task, capable of harmonizing multimodal conditions and delivering industry-grade performance. To overcome the trade-off between controllability and quality, we introduce Unified Channel-wise Conditioning for efficient image and pose injection, and Gated Local-Context Attention to ensure precise audio-visual synchronization. To effectively address data scarcity, we develop a Decoupled-Then-Joint Training strategy that leverages a multi-stage training process with model merging to efficiently harness heterogeneous sub-task datasets. Furthermore, to fill the evaluation gap in this field, we establish HOIVG-Bench, a dedicated and comprehensive benchmark for HOIVG. Extensive experiments demonstrate that OmniShow achieves overall state-of-the-art performance across various multimodal conditioning settings, setting a solid standard for the emerging HOIVG task.
PEGAsus: 3D Personalization of Geometry and Appearance
Feb 09, 2026We present PEGAsus, a new framework capable of generating Personalized 3D shapes by learning shape concepts at both Geometry and Appearance levels. First, we formulate 3D shape personalization as extracting reusable, category-agnostic geometric and appearance attributes from reference shapes, and composing these attributes with text to generate novel shapes. Second, we design a progressive optimization strategy to learn shape concepts at both the geometry and appearance levels, decoupling the shape concept learning process. Third, we extend our approach to region-wise concept learning, enabling flexible concept extraction, with context-aware and context-free losses. Extensive experimental results show that PEGAsus is able to effectively extract attributes from a wide range of reference shapes and then flexibly compose these concepts with text to synthesize new shapes. This enables fine-grained control over shape generation and supports the creation of diverse, personalized results, even in challenging cross-category scenarios. Both quantitative and qualitative experiments demonstrate that our approach outperforms existing state-of-the-art solutions.
EgoHandICL: Egocentric 3D Hand Reconstruction with In-Context Learning
Jan 27, 2026Robust 3D hand reconstruction in egocentric vision is challenging due to depth ambiguity, self-occlusion, and complex hand-object interactions. Prior methods mitigate these issues by scaling training data or adding auxiliary cues, but they often struggle in unseen contexts. We present EgoHandICL, the first in-context learning (ICL) framework for 3D hand reconstruction that improves semantic alignment, visual consistency, and robustness under challenging egocentric conditions. EgoHandICL introduces complementary exemplar retrieval guided by vision-language models (VLMs), an ICL-tailored tokenizer for multimodal context, and a masked autoencoder (MAE)-based architecture trained with hand-guided geometric and perceptual objectives. Experiments on ARCTIC and EgoExo4D show consistent gains over state-of-the-art methods. We also demonstrate real-world generalization and improve EgoVLM hand-object interaction reasoning by using reconstructed hands as visual prompts. Code and data: https://github.com/Nicous20/EgoHandICL
IdentityStory: Taming Your Identity-Preserving Generator for Human-Centric Story Generation
Dec 29, 2025Recent visual generative models enable story generation with consistent characters from text, but human-centric story generation faces additional challenges, such as maintaining detailed and diverse human face consistency and coordinating multiple characters across different images. This paper presents IdentityStory, a framework for human-centric story generation that ensures consistent character identity across multiple sequential images. By taming identity-preserving generators, the framework features two key components: Iterative Identity Discovery, which extracts cohesive character identities, and Re-denoising Identity Injection, which re-denoises images to inject identities while preserving desired context. Experiments on the ConsiStory-Human benchmark demonstrate that IdentityStory outperforms existing methods, particularly in face consistency, and supports multi-character combinations. The framework also shows strong potential for applications such as infinite-length story generation and dynamic character composition.
OpenView: Empowering MLLMs with Out-of-view VQA
Dec 21, 2025Recent multimodal large language models (MLLMs) show great potential in natural image understanding. Yet, they perform well, mainly on reasoning in-view contents within the image frame. This paper presents the first study on out-of-view (OOV) understanding, i.e., the ability to reason objects, activities, and scenes beyond the visible frame of a perspective view. Our technical contributions are threefold. First, we design OpenView, a four-stage pipeline to massively generate multi-choice VQA by leveraging panoramic imagery to enable context-rich and spatial-grounded VQA synthesis with free-view framing. Second, we curate OpenView-Dataset, a high-quality synthetic dataset from diverse real-world panoramas to empower MLLMs upon supervised fine-tuning. Third, we build OpenView-Bench, a benchmark that jointly measures choice and rationale accuracy for interpretable and diagnosable evaluation. Experimental results show that despite having a large gap from human performance in OOV VQA answer selection, upon empowered by OpenView, multiple MLLMs can consistently boost their performance, uplifted from 48.6% to 64.1% on average. Code, benchmark, and data will be available at https://github.com/q1xiangchen/OpenView.
DisCo-Layout: Disentangling and Coordinating Semantic and Physical Refinement in a Multi-Agent Framework for 3D Indoor Layout Synthesis
Oct 02, 2025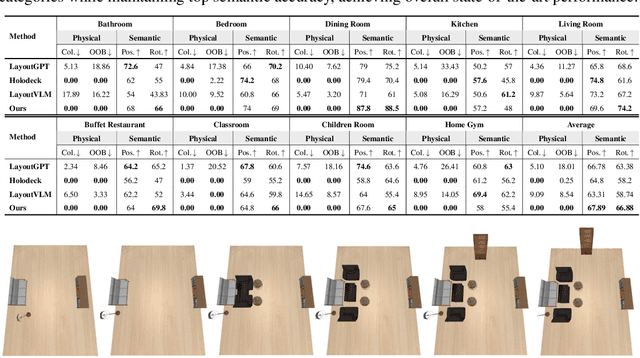
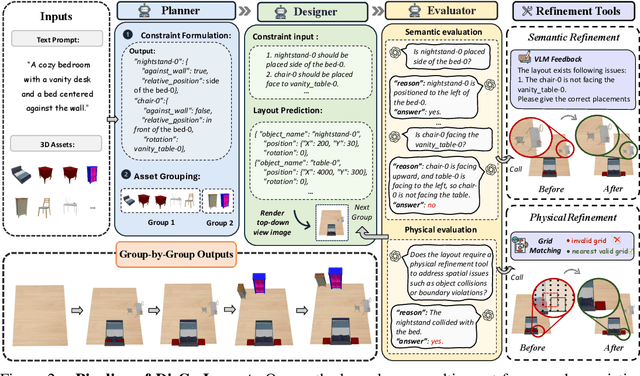
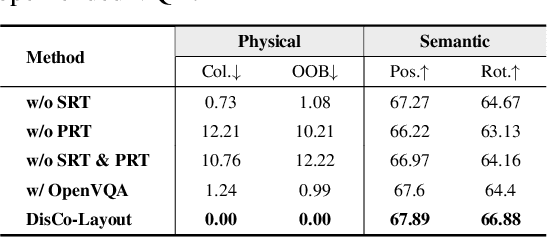
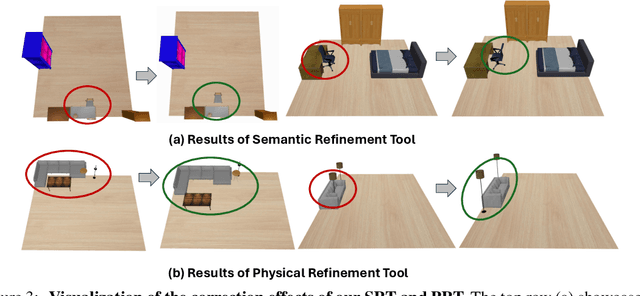
3D indoor layout synthesis is crucial for creating virtual environments. Traditional methods struggle with generalization due to fixed datasets. While recent LLM and VLM-based approaches offer improved semantic richness, they often lack robust and flexible refinement, resulting in suboptimal layouts. We develop DisCo-Layout, a novel framework that disentangles and coordinates physical and semantic refinement. For independent refinement, our Semantic Refinement Tool (SRT) corrects abstract object relationships, while the Physical Refinement Tool (PRT) resolves concrete spatial issues via a grid-matching algorithm. For collaborative refinement, a multi-agent framework intelligently orchestrates these tools, featuring a planner for placement rules, a designer for initial layouts, and an evaluator for assessment. Experiments demonstrate DisCo-Layout's state-of-the-art performance, generating realistic, coherent, and generalizable 3D indoor layouts. Our code will be publicly available.
Silence is Not Consensus: Disrupting Agreement Bias in Multi-Agent LLMs via Catfish Agent for Clinical Decision Making
May 27, 2025Large language models (LLMs) have demonstrated strong potential in clinical question answering, with recent multi-agent frameworks further improving diagnostic accuracy via collaborative reasoning. However, we identify a recurring issue of Silent Agreement, where agents prematurely converge on diagnoses without sufficient critical analysis, particularly in complex or ambiguous cases. We present a new concept called Catfish Agent, a role-specialized LLM designed to inject structured dissent and counter silent agreement. Inspired by the ``catfish effect'' in organizational psychology, the Catfish Agent is designed to challenge emerging consensus to stimulate deeper reasoning. We formulate two mechanisms to encourage effective and context-aware interventions: (i) a complexity-aware intervention that modulates agent engagement based on case difficulty, and (ii) a tone-calibrated intervention articulated to balance critique and collaboration. Evaluations on nine medical Q&A and three medical VQA benchmarks show that our approach consistently outperforms both single- and multi-agent LLMs frameworks, including leading commercial models such as GPT-4o and DeepSeek-R1.