 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPS3D: End-to-End Feed-Forward 3D Panoptic Segmentation
Jun 08, 2026This paper introduces EPS3D, a new end-to-end feed-forward framework for open-vocabulary 3D panoptic segmentation. Unlike existing methods relying on additional preprocessing, we design an end-to-end architecture, with a distillation-based training strategy on diverse 3D scenes to predict 3D-aware semantic and instance features from multi-view images, improving 3D consistency and avoiding error accumulation. We further propose a mutual enhancement module to enforce inherent semantic-instance consistency. By aligning semantics within instances (Ins2Sem) and refining instance features with semantic guidance (Sem2Ins), we achieve more coherent 3D scene understanding. Ultimately, EPS3D outperforms SOTA baselines on two benchmarks (e.g., +13% mIoU for semantics on Replica) with high efficiency (e.g., 1s per scene), supporting tasks like robotic manipulation and 3D scene editing.
PhyMix: Towards Physically Consistent Single-Image 3D Indoor Scene Generation with Implicit--Explicit Optimization
Apr 11, 2026Existing single-image 3D indoor scene generators often produce results that look visually plausible but fail to obey real-world physics, limiting their reliability in robotics, embodied AI, and design. To examine this gap, we introduce a unified Physics Evaluator that measures four main aspects: geometric priors, contact, stability, and deployability, which are further decomposed into nine sub-constraints, establishing the first benchmark to measure physical consistency. Based on this evaluator, our analysis shows that state-of-the-art methods remain largely physics-unaware. To overcome this limitation, we further propose a framework that integrates feedback from the Physics Evaluator into both training and inference, enhancing the physical plausibility of generated scenes. Specifically, we propose PhyMix, which is composed of two complementary components: (i) implicit alignment via Scene-GRPO, a critic-free group-relative policy optimization that leverages the Physics Evaluator as a preference signal and biases sampling towards physically feasible layouts, and (ii) explicit refinement via a plug-and-play Test-Time Optimizer (TTO) that uses differentiable evaluator signals to correct residual violations during generation. Overall, our method unifies evaluation, reward shaping, and inference-time correction, producing 3D indoor scenes that are visually faithful and physically plausible. Extensive synthetic evaluations confirm state-of-the-art performance in both visual fidelity and physical plausibility, and extensive qualitative examples in stylized and real-world images further showcase the robustness of the method. We will release codes and models upon publication.
coDrawAgents: A Multi-Agent Dialogue Framework for Compositional Image Generation
Mar 13, 2026Text-to-image generation has advanced rapidly, but existing models still struggle with faithfully composing multiple objects and preserving their attributes in complex scenes. We propose coDrawAgents, an interactive multi-agent dialogue framework with four specialized agents: Interpreter, Planner, Checker, and Painter that collaborate to improve compositional generation. The Interpreter adaptively decides between a direct text-to-image pathway and a layout-aware multi-agent process. In the layout-aware mode, it parses the prompt into attribute-rich object descriptors, ranks them by semantic salience, and groups objects with the same semantic priority level for joint generation. Guided by the Interpreter, the Planner adopts a divide-and-conquer strategy, incrementally proposing layouts for objects with the same semantic priority level while grounding decisions in the evolving visual context of the canvas. The Checker introduces an explicit error-correction mechanism by validating spatial consistency and attribute alignment, and refining layouts before they are rendered. Finally, the Painter synthesizes the image step by step, incorporating newly planned objects into the canvas to provide richer context for subsequent iterations. Together, these agents address three key challenges: reducing layout complexity, grounding planning in visual context, and enabling explicit error correction. Extensive experiments on benchmarks GenEval and DPG-Bench demonstrate that coDrawAgents substantially improves text-image alignment, spatial accuracy, and attribute binding compared to existing methods.
VisPhyWorld: Probing Physical Reasoning via Code-Driven Video Reconstruction
Feb 09, 2026Evaluating whether Multimodal Large Language Models (MLLMs) genuinely reason about physical dynamics remains challenging. Most existing benchmarks rely on recognition-style protocols such as Visual Question Answering (VQA) and Violation of Expectation (VoE), which can often be answered without committing to an explicit, testable physical hypothesis. We propose VisPhyWorld, an execution-based framework that evaluates physical reasoning by requiring models to generate executable simulator code from visual observations. By producing runnable code, the inferred world representation is directly inspectable, editable, and falsifiable. This separates physical reasoning from rendering. Building on this framework, we introduce VisPhyBench, comprising 209 evaluation scenes derived from 108 physical templates and a systematic protocol that evaluates how well models reconstruct appearance and reproduce physically plausible motion. Our pipeline produces valid reconstructed videos in 97.7% on the benchmark. Experiments show that while state-of-the-art MLLMs achieve strong semantic scene understanding, they struggle to accurately infer physical parameters and to simulate consistent physical dynamics.
PEGAsus: 3D Personalization of Geometry and Appearance
Feb 09, 2026We present PEGAsus, a new framework capable of generating Personalized 3D shapes by learning shape concepts at both Geometry and Appearance levels. First, we formulate 3D shape personalization as extracting reusable, category-agnostic geometric and appearance attributes from reference shapes, and composing these attributes with text to generate novel shapes. Second, we design a progressive optimization strategy to learn shape concepts at both the geometry and appearance levels, decoupling the shape concept learning process. Third, we extend our approach to region-wise concept learning, enabling flexible concept extraction, with context-aware and context-free losses. Extensive experimental results show that PEGAsus is able to effectively extract attributes from a wide range of reference shapes and then flexibly compose these concepts with text to synthesize new shapes. This enables fine-grained control over shape generation and supports the creation of diverse, personalized results, even in challenging cross-category scenarios. Both quantitative and qualitative experiments demonstrate that our approach outperforms existing state-of-the-art solutions.
Imagine a City: CityGenAgent for Procedural 3D City Generation
Feb 05, 2026The automated generation of interactive 3D cities is a critical challenge with broad applications in autonomous driving, virtual reality, and embodied intelligence. While recent advances in generative models and procedural techniques have improved the realism of city generation, existing methods often struggle with high-fidelity asset creation, controllability, and manipulation. In this work, we introduce CityGenAgent, a natural language-driven framework for hierarchical procedural generation of high-quality 3D cities. Our approach decomposes city generation into two interpretable components, Block Program and Building Program. To ensure structural correctness and semantic alignment, we adopt a two-stage learning strategy: (1) Supervised Fine-Tuning (SFT). We train BlockGen and BuildingGen to generate valid programs that adhere to schema constraints, including non-self-intersecting polygons and complete fields; (2) Reinforcement Learning (RL). We design Spatial Alignment Reward to enhance spatial reasoning ability and Visual Consistency Reward to bridge the gap between textual descriptions and the visual modality. Benefiting from the programs and the models' generalization, CityGenAgent supports natural language editing and manipulation. Comprehensive evaluations demonstrate superior semantic alignment, visual quality, and controllability compared to existing methods, establishing a robust foundation for scalable 3D city generation.
OPA-Pack: Object-Property-Aware Robotic Bin Packing
May 19, 2025Robotic bin packing aids in a wide range of real-world scenarios such as e-commerce and warehouses. Yet, existing works focus mainly on considering the shape of objects to optimize packing compactness and neglect object properties such as fragility, edibility, and chemistry that humans typically consider when packing objects. This paper presents OPA-Pack (Object-Property-Aware Packing framework), the first framework that equips the robot with object property considerations in planning the object packing. Technical-wise, we develop a novel object property recognition scheme with retrieval-augmented generation and chain-of-thought reasoning, and build a dataset with object property annotations for 1,032 everyday objects. Also, we formulate OPA-Net, aiming to jointly separate incompatible object pairs and reduce pressure on fragile objects, while compacting the packing. Further, OPA-Net consists of a property embedding layer to encode the property of candidate objects to be packed, together with a fragility heightmap and an avoidance heightmap to keep track of the packed objects. Then, we design a reward function and adopt a deep Q-learning scheme to train OPA-Net. Experimental results manifest that OPA-Pack greatly improves the accuracy of separating incompatible object pairs (from 52% to 95%) and largely reduces pressure on fragile objects (by 29.4%), while maintaining good packing compactness. Besides, we demonstrate the effectiveness of OPA-Pack on a real packing platform, showcasing its practicality in real-world scenarios.
Rethinking End-to-End 2D to 3D Scene Segmentation in Gaussian Splatting
Mar 18, 2025Lifting multi-view 2D instance segmentation to a radiance field has proven to be effective to enhance 3D understanding. Existing methods rely on direct matching for end-to-end lifting, yielding inferior results; or employ a two-stage solution constrained by complex pre- or post-processing. In this work, we design a new end-to-end object-aware lifting approach, named Unified-Lift that provides accurate 3D segmentation based on the 3D Gaussian representation. To start, we augment each Gaussian point with an additional Gaussian-level feature learned using a contrastive loss to encode instance information. Importantly, we introduce a learnable object-level codebook to account for individual objects in the scene for an explicit object-level understanding and associate the encoded object-level features with the Gaussian-level point features for segmentation predictions. While promising, achieving effective codebook learning is non-trivial and a naive solution leads to degraded performance. Therefore, we formulate the association learning module and the noisy label filtering module for effective and robust codebook learning. We conduct experiments on three benchmarks: LERF-Masked, Replica, and Messy Rooms datasets. Both qualitative and quantitative results manifest that our Unified-Lift clearly outperforms existing methods in terms of segmentation quality and time efficiency. The code is publicly available at \href{https://github.com/Runsong123/Unified-Lift}{https://github.com/Runsong123/Unified-Lift}.
WonderVerse: Extendable 3D Scene Generation with Video Generative Models
Mar 13, 2025We introduce \textit{WonderVerse}, a simple but effective framework for generating extendable 3D scenes. Unlike existing methods that rely on iterative depth estimation and image inpainting, often leading to geometric distortions and inconsistencies, WonderVerse leverages the powerful world-level priors embedded within video generative foundation models to create highly immersive and geometrically coherent 3D environments. Furthermore, we propose a new technique for controllable 3D scene extension to substantially increase the scale of the generated environments. Besides, we introduce a novel abnormal sequence detection module that utilizes camera trajectory to address geometric inconsistency in the generated videos. Finally, WonderVerse is compatible with various 3D reconstruction methods, allowing both efficient and high-quality generation. Extensive experiments on 3D scene generation demonstrate that our WonderVerse, with an elegant and simple pipeline, delivers extendable and highly-realistic 3D scenes, markedly outperforming existing works that rely on more complex architectures.
Not-So-Optimal Transport Flows for 3D Point Cloud Generation
Feb 18, 2025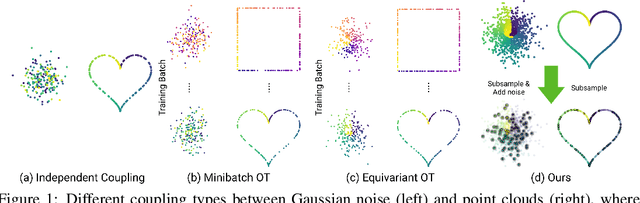
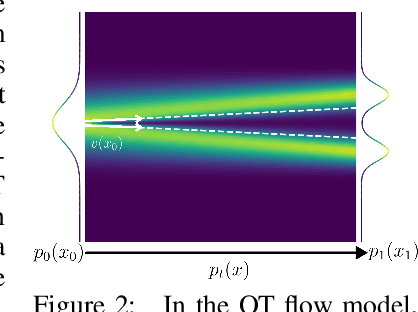
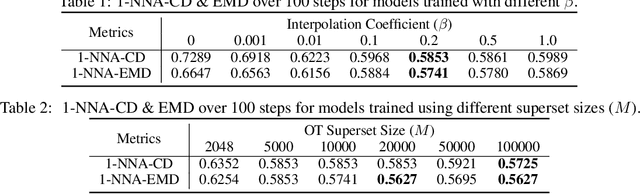
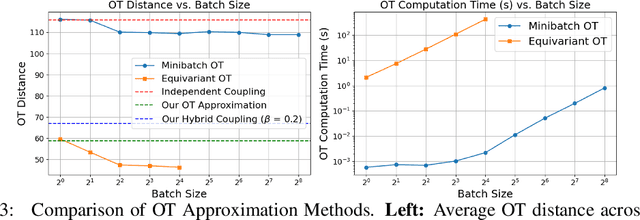
Learning generative models of 3D point clouds is one of the fundamental problems in 3D generative learning. One of the key properties of point clouds is their permutation invariance, i.e., changing the order of points in a point cloud does not change the shape they represent. In this paper, we analyze the recently proposed equivariant OT flows that learn permutation invariant generative models for point-based molecular data and we show that these models scale poorly on large point clouds. Also, we observe learning (equivariant) OT flows is generally challenging since straightening flow trajectories makes the learned flow model complex at the beginning of the trajectory. To remedy these, we propose not-so-optimal transport flow models that obtain an approximate OT by an offline OT precomputation, enabling an efficient construction of OT pairs for training. During training, we can additionally construct a hybrid coupling by combining our approximate OT and independent coupling to make the target flow models easier to learn. In an extensive empirical study, we show that our proposed model outperforms prior diffusion- and flow-based approaches on a wide range of unconditional generation and shape completion on the ShapeNet benchmark.