 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgecoDrawAgents: A Multi-Agent Dialogue Framework for Compositional Image Generation
Mar 13, 2026Text-to-image generation has advanced rapidly, but existing models still struggle with faithfully composing multiple objects and preserving their attributes in complex scenes. We propose coDrawAgents, an interactive multi-agent dialogue framework with four specialized agents: Interpreter, Planner, Checker, and Painter that collaborate to improve compositional generation. The Interpreter adaptively decides between a direct text-to-image pathway and a layout-aware multi-agent process. In the layout-aware mode, it parses the prompt into attribute-rich object descriptors, ranks them by semantic salience, and groups objects with the same semantic priority level for joint generation. Guided by the Interpreter, the Planner adopts a divide-and-conquer strategy, incrementally proposing layouts for objects with the same semantic priority level while grounding decisions in the evolving visual context of the canvas. The Checker introduces an explicit error-correction mechanism by validating spatial consistency and attribute alignment, and refining layouts before they are rendered. Finally, the Painter synthesizes the image step by step, incorporating newly planned objects into the canvas to provide richer context for subsequent iterations. Together, these agents address three key challenges: reducing layout complexity, grounding planning in visual context, and enabling explicit error correction. Extensive experiments on benchmarks GenEval and DPG-Bench demonstrate that coDrawAgents substantially improves text-image alignment, spatial accuracy, and attribute binding compared to existing methods.
OPA-Pack: Object-Property-Aware Robotic Bin Packing
May 19, 2025Robotic bin packing aids in a wide range of real-world scenarios such as e-commerce and warehouses. Yet, existing works focus mainly on considering the shape of objects to optimize packing compactness and neglect object properties such as fragility, edibility, and chemistry that humans typically consider when packing objects. This paper presents OPA-Pack (Object-Property-Aware Packing framework), the first framework that equips the robot with object property considerations in planning the object packing. Technical-wise, we develop a novel object property recognition scheme with retrieval-augmented generation and chain-of-thought reasoning, and build a dataset with object property annotations for 1,032 everyday objects. Also, we formulate OPA-Net, aiming to jointly separate incompatible object pairs and reduce pressure on fragile objects, while compacting the packing. Further, OPA-Net consists of a property embedding layer to encode the property of candidate objects to be packed, together with a fragility heightmap and an avoidance heightmap to keep track of the packed objects. Then, we design a reward function and adopt a deep Q-learning scheme to train OPA-Net. Experimental results manifest that OPA-Pack greatly improves the accuracy of separating incompatible object pairs (from 52% to 95%) and largely reduces pressure on fragile objects (by 29.4%), while maintaining good packing compactness. Besides, we demonstrate the effectiveness of OPA-Pack on a real packing platform, showcasing its practicality in real-world scenarios.
Incentivizing Multimodal Reasoning in Large Models for Direct Robot Manipulation
May 19, 2025Recent Large Multimodal Models have demonstrated remarkable reasoning capabilities, especially in solving complex mathematical problems and realizing accurate spatial perception. Our key insight is that these emerging abilities can naturally extend to robotic manipulation by enabling LMMs to directly infer the next goal in language via reasoning, rather than relying on a separate action head. However, this paradigm meets two main challenges: i) How to make LMMs understand the spatial action space, and ii) How to fully exploit the reasoning capacity of LMMs in solving these tasks. To tackle the former challenge, we propose a novel task formulation, which inputs the current states of object parts and the gripper, and reformulates rotation by a new axis representation instead of traditional Euler angles. This representation is more compatible with spatial reasoning and easier to interpret within a unified language space. For the latter challenge, we design a pipeline to utilize cutting-edge LMMs to generate a small but high-quality reasoning dataset of multi-round dialogues that successfully solve manipulation tasks for supervised fine-tuning. Then, we perform reinforcement learning by trial-and-error interactions in simulation to further enhance the model's reasoning abilities for robotic manipulation. Our resulting reasoning model built upon a 7B backbone, named ReasonManip, demonstrates three notable advantages driven by its system-2 level reasoning capabilities: i) exceptional generalizability to out-of-distribution environments, objects, and tasks; ii) inherent sim-to-real transfer ability enabled by the unified language representation shared across domains; iii) transparent interpretability connecting high-level reasoning and low-level control. Extensive experiments demonstrate the effectiveness of the proposed paradigm and its potential to advance LMM-driven robotic manipulation.
WonderVerse: Extendable 3D Scene Generation with Video Generative Models
Mar 13, 2025We introduce \textit{WonderVerse}, a simple but effective framework for generating extendable 3D scenes. Unlike existing methods that rely on iterative depth estimation and image inpainting, often leading to geometric distortions and inconsistencies, WonderVerse leverages the powerful world-level priors embedded within video generative foundation models to create highly immersive and geometrically coherent 3D environments. Furthermore, we propose a new technique for controllable 3D scene extension to substantially increase the scale of the generated environments. Besides, we introduce a novel abnormal sequence detection module that utilizes camera trajectory to address geometric inconsistency in the generated videos. Finally, WonderVerse is compatible with various 3D reconstruction methods, allowing both efficient and high-quality generation. Extensive experiments on 3D scene generation demonstrate that our WonderVerse, with an elegant and simple pipeline, delivers extendable and highly-realistic 3D scenes, markedly outperforming existing works that rely on more complex architectures.
Embodiment-Agnostic Action Planning via Object-Part Scene Flow
Sep 16, 2024



Observing that the key for robotic action planning is to understand the target-object motion when its associated part is manipulated by the end effector, we propose to generate the 3D object-part scene flow and extract its transformations to solve the action trajectories for diverse embodiments. The advantage of our approach is that it derives the robot action explicitly from object motion prediction, yielding a more robust policy by understanding the object motions. Also, beyond policies trained on embodiment-centric data, our method is embodiment-agnostic, generalizable across diverse embodiments, and being able to learn from human demonstrations. Our method comprises three components: an object-part predictor to locate the part for the end effector to manipulate, an RGBD video generator to predict future RGBD videos, and a trajectory planner to extract embodiment-agnostic transformation sequences and solve the trajectory for diverse embodiments. Trained on videos even without trajectory data, our method still outperforms existing works significantly by 27.7% and 26.2% on the prevailing virtual environments MetaWorld and Franka-Kitchen, respectively. Furthermore, we conducted real-world experiments, showing that our policy, trained only with human demonstration, can be deployed to various embodiments.
SDF-Pack: Towards Compact Bin Packing with Signed-Distance-Field Minimization
Jul 14, 2023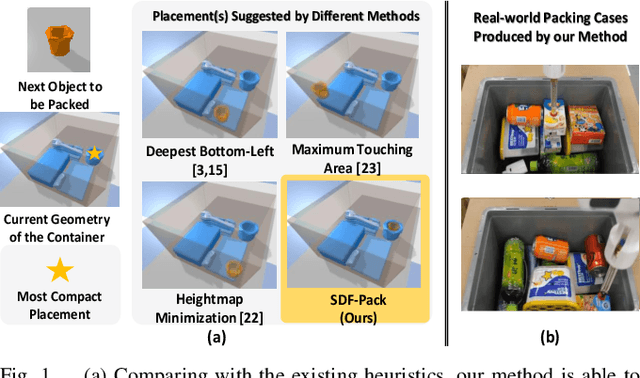
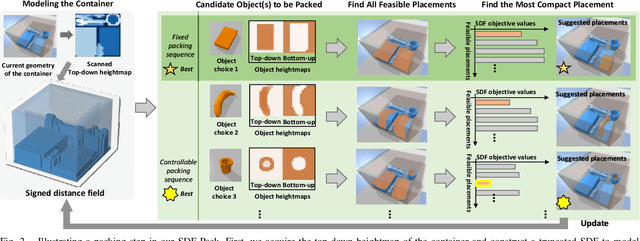

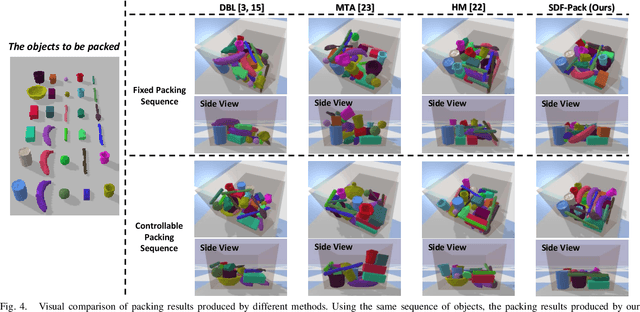
Robotic bin packing is very challenging, especially when considering practical needs such as object variety and packing compactness. This paper presents SDF-Pack, a new approach based on signed distance field (SDF) to model the geometric condition of objects in a container and compute the object placement locations and packing orders for achieving a more compact bin packing. Our method adopts a truncated SDF representation to localize the computation, and based on it, we formulate the SDF minimization heuristic to find optimized placements to compactly pack objects with the existing ones. To further improve space utilization, if the packing sequence is controllable, our method can suggest which object to be packed next. Experimental results on a large variety of everyday objects show that our method can consistently achieve higher packing compactness over 1,000 packing cases, enabling us to pack more objects into the container, compared with the existing heuristics under various packing settings.