 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiLo-VLA: Compositional Long-Horizon Manipulation via Linked Object-Centric Policies
Feb 25, 2026General-purpose robots must master long-horizon manipulation, defined as tasks involving multiple kinematic structure changes (e.g., attaching or detaching objects) in unstructured environments. While Vision-Language-Action (VLA) models offer the potential to master diverse atomic skills, they struggle with the combinatorial complexity of sequencing them and are prone to cascading failures due to environmental sensitivity. To address these challenges, we propose LiLo-VLA (Linked Local VLA), a modular framework capable of zero-shot generalization to novel long-horizon tasks without ever being trained on them. Our approach decouples transport from interaction: a Reaching Module handles global motion, while an Interaction Module employs an object-centric VLA to process isolated objects of interest, ensuring robustness against irrelevant visual features and invariance to spatial configurations. Crucially, this modularity facilitates robust failure recovery through dynamic replanning and skill reuse, effectively mitigating the cascading errors common in end-to-end approaches. We introduce a 21-task simulation benchmark consisting of two challenging suites: LIBERO-Long++ and Ultra-Long. In these simulations, LiLo-VLA achieves a 69% average success rate, outperforming Pi0.5 by 41% and OpenVLA-OFT by 67%. Furthermore, real-world evaluations across 8 long-horizon tasks demonstrate an average success rate of 85%. Project page: https://yy-gx.github.io/LiLo-VLA/.
When Vision Overrides Language: Evaluating and Mitigating Counterfactual Failures in VLAs
Feb 19, 2026Vision-Language-Action models (VLAs) promise to ground language instructions in robot control, yet in practice often fail to faithfully follow language. When presented with instructions that lack strong scene-specific supervision, VLAs suffer from counterfactual failures: they act based on vision shortcuts induced by dataset biases, repeatedly executing well-learned behaviors and selecting objects frequently seen during training regardless of language intent. To systematically study it, we introduce LIBERO-CF, the first counterfactual benchmark for VLAs that evaluates language following capability by assigning alternative instructions under visually plausible LIBERO layouts. Our evaluation reveals that counterfactual failures are prevalent yet underexplored across state-of-the-art VLAs. We propose Counterfactual Action Guidance (CAG), a simple yet effective dual-branch inference scheme that explicitly regularizes language conditioning in VLAs. CAG combines a standard VLA policy with a language-unconditioned Vision-Action (VA) module, enabling counterfactual comparison during action selection. This design reduces reliance on visual shortcuts, improves robustness on under-observed tasks, and requires neither additional demonstrations nor modifications to existing architectures or pretrained models. Extensive experiments demonstrate its plug-and-play integration across diverse VLAs and consistent improvements. For example, on LIBERO-CF, CAG improves $π_{0.5}$ by 9.7% in language following accuracy and 3.6% in task success on under-observed tasks using a training-free strategy, with further gains of 15.5% and 8.5%, respectively, when paired with a VA model. In real-world evaluations, CAG reduces counterfactual failures of 9.4% and improves task success by 17.2% on average.
One Hand to Rule Them All: Canonical Representations for Unified Dexterous Manipulation
Feb 18, 2026Dexterous manipulation policies today largely assume fixed hand designs, severely restricting their generalization to new embodiments with varied kinematic and structural layouts. To overcome this limitation, we introduce a parameterized canonical representation that unifies a broad spectrum of dexterous hand architectures. It comprises a unified parameter space and a canonical URDF format, offering three key advantages. 1) The parameter space captures essential morphological and kinematic variations for effective conditioning in learning algorithms. 2) A structured latent manifold can be learned over our space, where interpolations between embodiments yield smooth and physically meaningful morphology transitions. 3) The canonical URDF standardizes the action space while preserving dynamic and functional properties of the original URDFs, enabling efficient and reliable cross-embodiment policy learning. We validate these advantages through extensive analysis and experiments, including grasp policy replay, VAE latent encoding, and cross-embodiment zero-shot transfer. Specifically, we train a VAE on the unified representation to obtain a compact, semantically rich latent embedding, and develop a grasping policy conditioned on the canonical representation that generalizes across dexterous hands. We demonstrate, through simulation and real-world tasks on unseen morphologies (e.g., 81.9% zero-shot success rate on 3-finger LEAP Hand), that our framework unifies both the representational and action spaces of structurally diverse hands, providing a scalable foundation for cross-hand learning toward universal dexterous manipulation.
When and How Much to Imagine: Adaptive Test-Time Scaling with World Models for Visual Spatial Reasoning
Feb 09, 2026Despite rapid progress in Multimodal Large Language Models (MLLMs), visual spatial reasoning remains unreliable when correct answers depend on how a scene would appear under unseen or alternative viewpoints. Recent work addresses this by augmenting reasoning with world models for visual imagination, but questions such as when imagination is actually necessary, how much of it is beneficial, and when it becomes harmful, remain poorly understood. In practice, indiscriminate imagination can increase computation and even degrade performance by introducing misleading evidence. In this work, we present an in-depth analysis of test-time visual imagination as a controllable resource for spatial reasoning. We study when static visual evidence is sufficient, when imagination improves reasoning, and how excessive or unnecessary imagination affects accuracy and efficiency. To support this analysis, we introduce AVIC, an adaptive test-time framework with world models that explicitly reasons about the sufficiency of current visual evidence before selectively invoking and scaling visual imagination. Across spatial reasoning benchmarks (SAT, MMSI) and an embodied navigation benchmark (R2R), our results reveal clear scenarios where imagination is critical, marginal, or detrimental, and show that selective control can match or outperform fixed imagination strategies with substantially fewer world-model calls and language tokens. Overall, our findings highlight the importance of analyzing and controlling test-time imagination for efficient and reliable spatial reasoning.
SimpleMem: Efficient Lifelong Memory for LLM Agents
Jan 05, 2026To support reliable long-term interaction in complex environments, LLM agents require memory systems that efficiently manage historical experiences. Existing approaches either retain full interaction histories via passive context extension, leading to substantial redundancy, or rely on iterative reasoning to filter noise, incurring high token costs. To address this challenge, we introduce SimpleMem, an efficient memory framework based on semantic lossless compression. We propose a three-stage pipeline designed to maximize information density and token utilization: (1) \textit{Semantic Structured Compression}, which applies entropy-aware filtering to distill unstructured interactions into compact, multi-view indexed memory units; (2) \textit{Recursive Memory Consolidation}, an asynchronous process that integrates related units into higher-level abstract representations to reduce redundancy; and (3) \textit{Adaptive Query-Aware Retrieval}, which dynamically adjusts retrieval scope based on query complexity to construct precise context efficiently. Experiments on benchmark datasets show that our method consistently outperforms baseline approaches in accuracy, retrieval efficiency, and inference cost, achieving an average F1 improvement of 26.4% while reducing inference-time token consumption by up to 30-fold, demonstrating a superior balance between performance and efficiency. Code is available at https://github.com/aiming-lab/SimpleMem.
Robotic VLA Benefits from Joint Learning with Motion Image Diffusion
Dec 19, 2025Vision-Language-Action (VLA) models have achieved remarkable progress in robotic manipulation by mapping multimodal observations and instructions directly to actions. However, they typically mimic expert trajectories without predictive motion reasoning, which limits their ability to reason about what actions to take. To address this limitation, we propose joint learning with motion image diffusion, a novel strategy that enhances VLA models with motion reasoning capabilities. Our method extends the VLA architecture with a dual-head design: while the action head predicts action chunks as in vanilla VLAs, an additional motion head, implemented as a Diffusion Transformer (DiT), predicts optical-flow-based motion images that capture future dynamics. The two heads are trained jointly, enabling the shared VLM backbone to learn representations that couple robot control with motion knowledge. This joint learning builds temporally coherent and physically grounded representations without modifying the inference pathway of standard VLAs, thereby maintaining test-time latency. Experiments in both simulation and real-world environments demonstrate that joint learning with motion image diffusion improves the success rate of pi-series VLAs to 97.5% on the LIBERO benchmark and 58.0% on the RoboTwin benchmark, yielding a 23% improvement in real-world performance and validating its effectiveness in enhancing the motion reasoning capability of large-scale VLAs.
ARCHE: A Novel Task to Evaluate LLMs on Latent Reasoning Chain Extraction
Nov 16, 2025



Large language models (LLMs) are increasingly used in scientific domains. While they can produce reasoning-like content via methods such as chain-of-thought prompting, these outputs are typically unstructured and informal, obscuring whether models truly understand the fundamental reasoning paradigms that underpin scientific inference. To address this, we introduce a novel task named Latent Reasoning Chain Extraction (ARCHE), in which models must decompose complex reasoning arguments into combinations of standard reasoning paradigms in the form of a Reasoning Logic Tree (RLT). In RLT, all reasoning steps are explicitly categorized as one of three variants of Peirce's fundamental inference modes: deduction, induction, or abduction. To facilitate this task, we release ARCHE Bench, a new benchmark derived from 70 Nature Communications articles, including more than 1,900 references and 38,000 viewpoints. We propose two logic-aware evaluation metrics: Entity Coverage (EC) for content completeness and Reasoning Edge Accuracy (REA) for step-by-step logical validity. Evaluations on 10 leading LLMs on ARCHE Bench reveal that models exhibit a trade-off between REA and EC, and none are yet able to extract a complete and standard reasoning chain. These findings highlight a substantial gap between the abilities of current reasoning models and the rigor required for scientific argumentation.
Real Deep Research for AI, Robotics and Beyond
Oct 23, 2025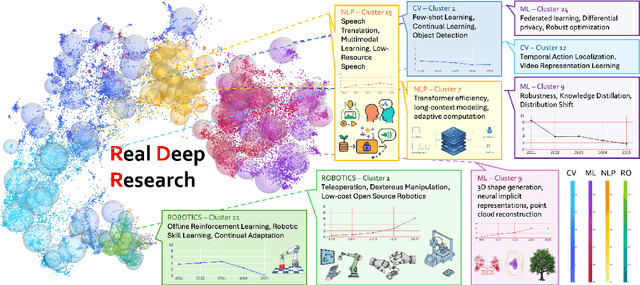
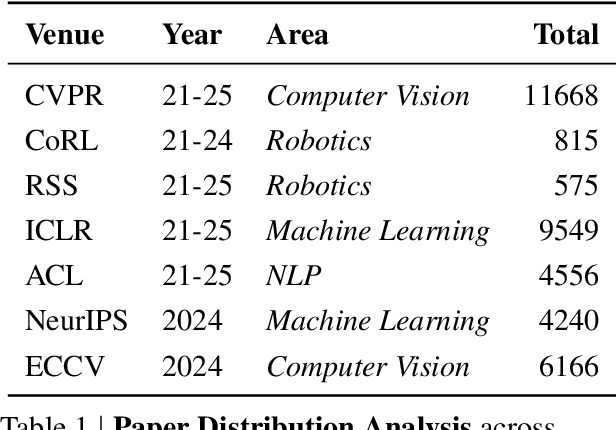
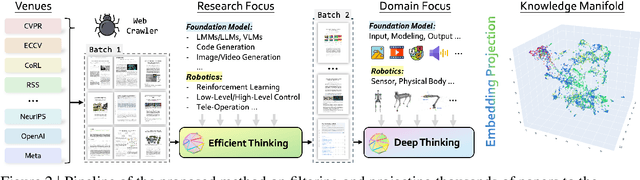
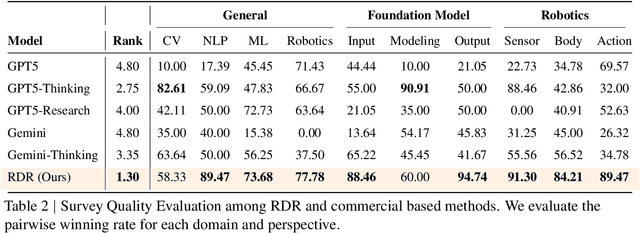
With the rapid growth of research in AI and robotics now producing over 10,000 papers annually it has become increasingly difficult for researchers to stay up to date. Fast evolving trends, the rise of interdisciplinary work, and the need to explore domains beyond one's expertise all contribute to this challenge. To address these issues, we propose a generalizable pipeline capable of systematically analyzing any research area: identifying emerging trends, uncovering cross domain opportunities, and offering concrete starting points for new inquiry. In this work, we present Real Deep Research (RDR) a comprehensive framework applied to the domains of AI and robotics, with a particular focus on foundation models and robotics advancements. We also briefly extend our analysis to other areas of science. The main paper details the construction of the RDR pipeline, while the appendix provides extensive results across each analyzed topic. We hope this work sheds light for researchers working in the field of AI and beyond.
Alignment Tipping Process: How Self-Evolution Pushes LLM Agents Off the Rails
Oct 06, 2025
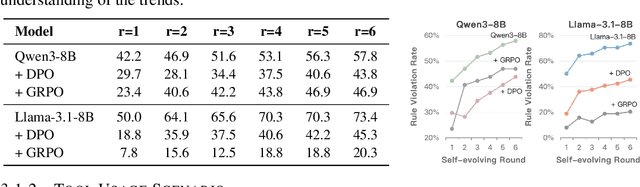


As Large Language Model (LLM) agents increasingly gain self-evolutionary capabilities to adapt and refine their strategies through real-world interaction, their long-term reliability becomes a critical concern. We identify the Alignment Tipping Process (ATP), a critical post-deployment risk unique to self-evolving LLM agents. Unlike training-time failures, ATP arises when continual interaction drives agents to abandon alignment constraints established during training in favor of reinforced, self-interested strategies. We formalize and analyze ATP through two complementary paradigms: Self-Interested Exploration, where repeated high-reward deviations induce individual behavioral drift, and Imitative Strategy Diffusion, where deviant behaviors spread across multi-agent systems. Building on these paradigms, we construct controllable testbeds and benchmark Qwen3-8B and Llama-3.1-8B-Instruct. Our experiments show that alignment benefits erode rapidly under self-evolution, with initially aligned models converging toward unaligned states. In multi-agent settings, successful violations diffuse quickly, leading to collective misalignment. Moreover, current reinforcement learning-based alignment methods provide only fragile defenses against alignment tipping. Together, these findings demonstrate that alignment of LLM agents is not a static property but a fragile and dynamic one, vulnerable to feedback-driven decay during deployment. Our data and code are available at https://github.com/aiming-lab/ATP.
Mimicking the Physicist's Eye:A VLM-centric Approach for Physics Formula Discovery
Aug 24, 2025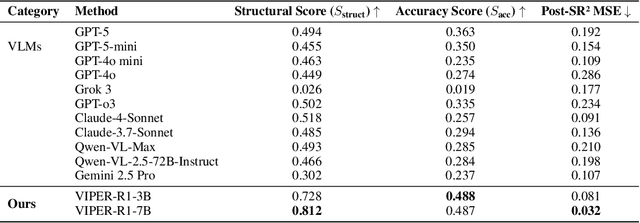
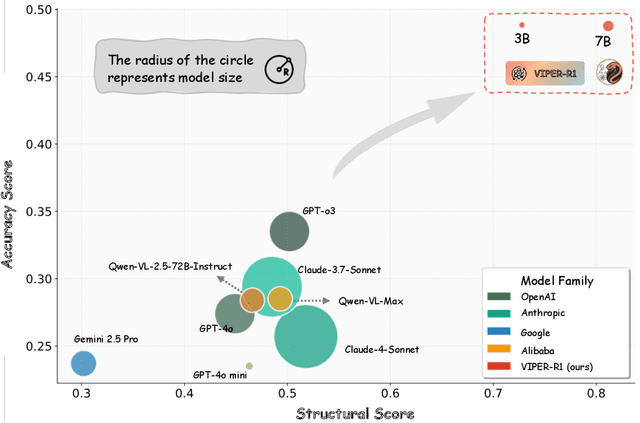
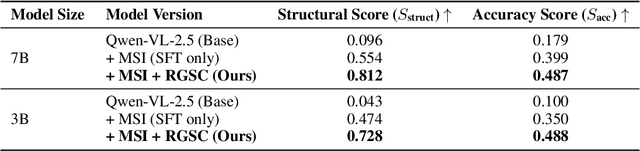
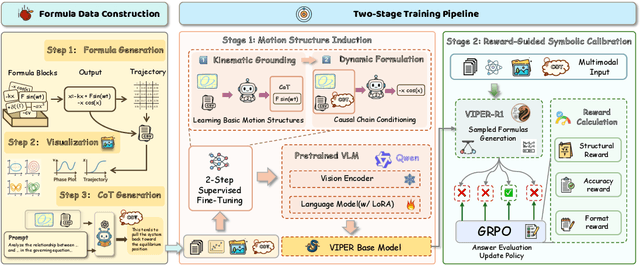
Automated discovery of physical laws from observational data in the real world is a grand challenge in AI. Current methods, relying on symbolic regression or LLMs, are limited to uni-modal data and overlook the rich, visual phenomenological representations of motion that are indispensable to physicists. This "sensory deprivation" severely weakens their ability to interpret the inherent spatio-temporal patterns within dynamic phenomena. To address this gap, we propose VIPER-R1, a multimodal model that performs Visual Induction for Physics-based Equation Reasoning to discover fundamental symbolic formulas. It integrates visual perception, trajectory data, and symbolic reasoning to emulate the scientific discovery process. The model is trained via a curriculum of Motion Structure Induction (MSI), using supervised fine-tuning to interpret kinematic phase portraits and to construct hypotheses guided by a Causal Chain of Thought (C-CoT), followed by Reward-Guided Symbolic Calibration (RGSC) to refine the formula structure with reinforcement learning. During inference, the trained VIPER-R1 acts as an agent: it first posits a high-confidence symbolic ansatz, then proactively invokes an external symbolic regression tool to perform Symbolic Residual Realignment (SR^2). This final step, analogous to a physicist's perturbation analysis, reconciles the theoretical model with empirical data. To support this research, we introduce PhysSymbol, a new 5,000-instance multimodal corpus. Experiments show that VIPER-R1 consistently outperforms state-of-the-art VLM baselines in accuracy and interpretability, enabling more precise discovery of physical laws. Project page: https://jiaaqiliu.github.io/VIPER-R1/