 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSumo: Dynamic and Generalizable Whole-Body Loco-Manipulation
Apr 09, 2026This paper presents a sim-to-real approach that enables legged robots to dynamically manipulate large and heavy objects with whole-body dexterity. Our key insight is that by performing test-time steering of a pre-trained whole-body control policy with a sample-based planner, we can enable these robots to solve a variety of dynamic loco-manipulation tasks. Interestingly, we find our method generalizes to a diverse set of objects and tasks with no additional tuning or training, and can be further enhanced by flexibly adjusting the cost function at test time. We demonstrate the capabilities of our approach through a variety of challenging loco-manipulation tasks on a Spot quadruped robot in the real world, including uprighting a tire heavier than the robot's nominal lifting capacity and dragging a crowd-control barrier larger and taller than the robot itself. Additionally, we show that the same approach can be generalized to humanoid loco-manipulation tasks, such as opening a door and pushing a table, in simulation. Project code and videos are available at \href{https://sumo.rai-inst.com/}{https://sumo.rai-inst.com/}.
SAGA: Open-World Mobile Manipulation via Structured Affordance Grounding
Dec 14, 2025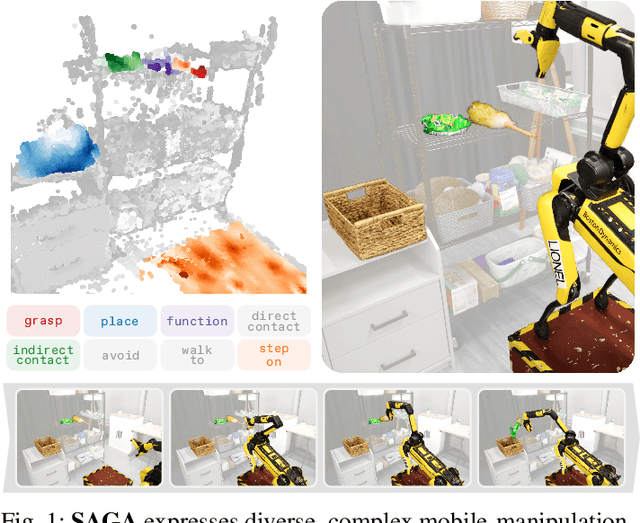
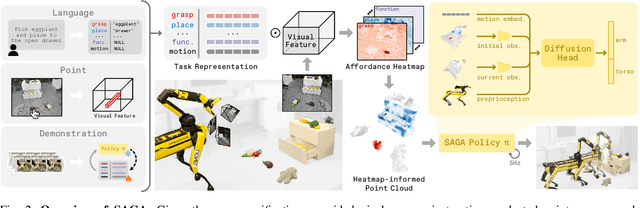
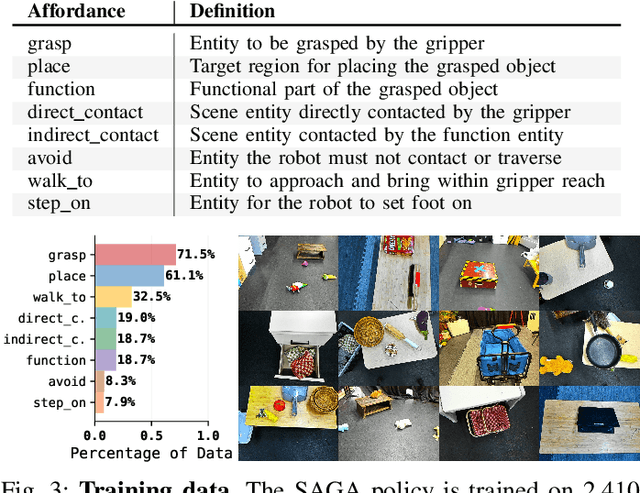
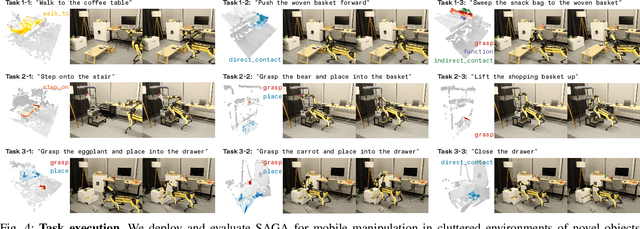
We present SAGA, a versatile and adaptive framework for visuomotor control that can generalize across various environments, task objectives, and user specifications. To efficiently learn such capability, our key idea is to disentangle high-level semantic intent from low-level visuomotor control by explicitly grounding task objectives in the observed environment. Using an affordance-based task representation, we express diverse and complex behaviors in a unified, structured form. By leveraging multimodal foundation models, SAGA grounds the proposed task representation to the robot's visual observation as 3D affordance heatmaps, highlighting task-relevant entities while abstracting away spurious appearance variations that would hinder generalization. These grounded affordances enable us to effectively train a conditional policy on multi-task demonstration data for whole-body control. In a unified framework, SAGA can solve tasks specified in different forms, including language instructions, selected points, and example demonstrations, enabling both zero-shot execution and few-shot adaptation. We instantiate SAGA on a quadrupedal manipulator and conduct extensive experiments across eleven real-world tasks. SAGA consistently outperforms end-to-end and modular baselines by substantial margins. Together, these results demonstrate that structured affordance grounding offers a scalable and effective pathway toward generalist mobile manipulation.
Ask-to-Clarify: Resolving Instruction Ambiguity through Multi-turn Dialogue
Sep 18, 2025The ultimate goal of embodied agents is to create collaborators that can interact with humans, not mere executors that passively follow instructions. This requires agents to communicate, coordinate, and adapt their actions based on human feedback. Recently, advances in VLAs have offered a path toward this goal. However, most current VLA-based embodied agents operate in a one-way mode: they receive an instruction and execute it without feedback. This approach fails in real-world scenarios where instructions are often ambiguous. In this paper, we address this problem with the Ask-to-Clarify framework. Our framework first resolves ambiguous instructions by asking questions in a multi-turn dialogue. Then it generates low-level actions end-to-end. Specifically, the Ask-to-Clarify framework consists of two components, one VLM for collaboration and one diffusion for action. We also introduce a connection module that generates conditions for the diffusion based on the output of the VLM. This module adjusts the observation by instructions to create reliable conditions. We train our framework with a two-stage knowledge-insulation strategy. First, we fine-tune the collaboration component using ambiguity-solving dialogue data to handle ambiguity. Then, we integrate the action component while freezing the collaboration one. This preserves the interaction abilities while fine-tuning the diffusion to generate actions. The training strategy guarantees our framework can first ask questions, then generate actions. During inference, a signal detector functions as a router that helps our framework switch between asking questions and taking actions. We evaluate the Ask-to-Clarify framework in 8 real-world tasks, where it outperforms existing state-of-the-art VLAs. The results suggest that our proposed framework, along with the training strategy, provides a path toward collaborative embodied agents.
Versatile Loco-Manipulation through Flexible Interlimb Coordination
Jun 09, 2025The ability to flexibly leverage limbs for loco-manipulation is essential for enabling autonomous robots to operate in unstructured environments. Yet, prior work on loco-manipulation is often constrained to specific tasks or predetermined limb configurations. In this work, we present Reinforcement Learning for Interlimb Coordination (ReLIC), an approach that enables versatile loco-manipulation through flexible interlimb coordination. The key to our approach is an adaptive controller that seamlessly bridges the execution of manipulation motions and the generation of stable gaits based on task demands. Through the interplay between two controller modules, ReLIC dynamically assigns each limb for manipulation or locomotion and robustly coordinates them to achieve the task success. Using efficient reinforcement learning in simulation, ReLIC learns to perform stable gaits in accordance with the manipulation goals in the real world. To solve diverse and complex tasks, we further propose to interface the learned controller with different types of task specifications, including target trajectories, contact points, and natural language instructions. Evaluated on 12 real-world tasks that require diverse and complex coordination patterns, ReLIC demonstrates its versatility and robustness by achieving a success rate of 78.9% on average. Videos and code can be found at https://relic-locoman.github.io/.
Robust Model-Based In-Hand Manipulation with Integrated Real-Time Motion-Contact Planning and Tracking
May 08, 2025Robotic dexterous in-hand manipulation, where multiple fingers dynamically make and break contact, represents a step toward human-like dexterity in real-world robotic applications. Unlike learning-based approaches that rely on large-scale training or extensive data collection for each specific task, model-based methods offer an efficient alternative. Their online computing nature allows for ready application to new tasks without extensive retraining. However, due to the complexity of physical contacts, existing model-based methods encounter challenges in efficient online planning and handling modeling errors, which limit their practical applications. To advance the effectiveness and robustness of model-based contact-rich in-hand manipulation, this paper proposes a novel integrated framework that mitigates these limitations. The integration involves two key aspects: 1) integrated real-time planning and tracking achieved by a hierarchical structure; and 2) joint optimization of motions and contacts achieved by integrated motion-contact modeling. Specifically, at the high level, finger motion and contact force references are jointly generated using contact-implicit model predictive control. The high-level module facilitates real-time planning and disturbance recovery. At the low level, these integrated references are concurrently tracked using a hand force-motion model and actual tactile feedback. The low-level module compensates for modeling errors and enhances the robustness of manipulation. Extensive experiments demonstrate that our approach outperforms existing model-based methods in terms of accuracy, robustness, and real-time performance. Our method successfully completes five challenging tasks in real-world environments, even under appreciable external disturbances.
ReBot: Scaling Robot Learning with Real-to-Sim-to-Real Robotic Video Synthesis
Mar 15, 2025Vision-language-action (VLA) models present a promising paradigm by training policies directly on real robot datasets like Open X-Embodiment. However, the high cost of real-world data collection hinders further data scaling, thereby restricting the generalizability of VLAs. In this paper, we introduce ReBot, a novel real-to-sim-to-real approach for scaling real robot datasets and adapting VLA models to target domains, which is the last-mile deployment challenge in robot manipulation. Specifically, ReBot replays real-world robot trajectories in simulation to diversify manipulated objects (real-to-sim), and integrates the simulated movements with inpainted real-world background to synthesize physically realistic and temporally consistent robot videos (sim-to-real). Our approach has several advantages: 1) it enjoys the benefit of real data to minimize the sim-to-real gap; 2) it leverages the scalability of simulation; and 3) it can generalize a pretrained VLA to a target domain with fully automated data pipelines. Extensive experiments in both simulation and real-world environments show that ReBot significantly enhances the performance and robustness of VLAs. For example, in SimplerEnv with the WidowX robot, ReBot improved the in-domain performance of Octo by 7.2% and OpenVLA by 21.8%, and out-of-domain generalization by 19.9% and 9.4%, respectively. For real-world evaluation with a Franka robot, ReBot increased the success rates of Octo by 17% and OpenVLA by 20%. More information can be found at: https://yuffish.github.io/rebot/
Residual Policy Gradient: A Reward View of KL-regularized Objective
Mar 14, 2025



Reinforcement Learning and Imitation Learning have achieved widespread success in many domains but remain constrained during real-world deployment. One of the main issues is the additional requirements that were not considered during training. To address this challenge, policy customization has been introduced, aiming to adapt a prior policy while preserving its inherent properties and meeting new task-specific requirements. A principled approach to policy customization is Residual Q-Learning (RQL), which formulates the problem as a Markov Decision Process (MDP) and derives a family of value-based learning algorithms. However, RQL has not yet been applied to policy gradient methods, which restricts its applicability, especially in tasks where policy gradient has already proven more effective. In this work, we first derive a concise form of Soft Policy Gradient as a preliminary. Building on this, we introduce Residual Policy Gradient (RPG), which extends RQL to policy gradient methods, allowing policy customization in gradient-based RL settings. With the view of RPG, we rethink the KL-regularized objective widely used in RL fine-tuning. We show that under certain assumptions, KL-regularized objective leads to a maximum-entropy policy that balances the inherent properties and task-specific requirements on a reward-level. Our experiments in MuJoCo demonstrate the effectiveness of Soft Policy Gradient and Residual Policy Gradient.
Planning-Guided Diffusion Policy Learning for Generalizable Contact-Rich Bimanual Manipulation
Dec 03, 2024



Contact-rich bimanual manipulation involves precise coordination of two arms to change object states through strategically selected contacts and motions. Due to the inherent complexity of these tasks, acquiring sufficient demonstration data and training policies that generalize to unseen scenarios remain a largely unresolved challenge. Building on recent advances in planning through contacts, we introduce Generalizable Planning-Guided Diffusion Policy Learning (GLIDE), an approach that effectively learns to solve contact-rich bimanual manipulation tasks by leveraging model-based motion planners to generate demonstration data in high-fidelity physics simulation. Through efficient planning in randomized environments, our approach generates large-scale and high-quality synthetic motion trajectories for tasks involving diverse objects and transformations. We then train a task-conditioned diffusion policy via behavior cloning using these demonstrations. To tackle the sim-to-real gap, we propose a set of essential design options in feature extraction, task representation, action prediction, and data augmentation that enable learning robust prediction of smooth action sequences and generalization to unseen scenarios. Through experiments in both simulation and the real world, we demonstrate that our approach can enable a bimanual robotic system to effectively manipulate objects of diverse geometries, dimensions, and physical properties. Website: https://glide-manip.github.io/
DexH2R: Task-oriented Dexterous Manipulation from Human to Robots
Nov 07, 2024Dexterous manipulation is a critical aspect of human capability, enabling interaction with a wide variety of objects. Recent advancements in learning from human demonstrations and teleoperation have enabled progress for robots in such ability. However, these approaches either require complex data collection such as costly human effort for eye-robot contact, or suffer from poor generalization when faced with novel scenarios. To solve both challenges, we propose a framework, DexH2R, that combines human hand motion retargeting with a task-oriented residual action policy, improving task performance by bridging the embodiment gap between human and robotic dexterous hands. Specifically, DexH2R learns the residual policy directly from retargeted primitive actions and task-oriented rewards, eliminating the need for labor-intensive teleoperation systems. Moreover, we incorporate test-time guidance for novel scenarios by taking in desired trajectories of human hands and objects, allowing the dexterous hand to acquire new skills with high generalizability. Extensive experiments in both simulation and real-world environments demonstrate the effectiveness of our work, outperforming prior state-of-the-arts by 40% across various settings.
Adaptive Energy Regularization for Autonomous Gait Transition and Energy-Efficient Quadruped Locomotion
Mar 29, 2024



In reinforcement learning for legged robot locomotion, crafting effective reward strategies is crucial. Pre-defined gait patterns and complex reward systems are widely used to stabilize policy training. Drawing from the natural locomotion behaviors of humans and animals, which adapt their gaits to minimize energy consumption, we propose a simplified, energy-centric reward strategy to foster the development of energy-efficient locomotion across various speeds in quadruped robots. By implementing an adaptive energy reward function and adjusting the weights based on velocity, we demonstrate that our approach enables ANYmal-C and Unitree Go1 robots to autonomously select appropriate gaits, such as four-beat walking at lower speeds and trotting at higher speeds, resulting in improved energy efficiency and stable velocity tracking compared to previous methods using complex reward designs and prior gait knowledge. The effectiveness of our policy is validated through simulations in the IsaacGym simulation environment and on real robots, demonstrating its potential to facilitate stable and adaptive locomotion.