 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgrammable Locking Cells (PLC) for Modular Robots with High Stiffness Tunability and Morphological Adaptability
Sep 09, 2025Robotic systems operating in unstructured environments require the ability to switch between compliant and rigid states to perform diverse tasks such as adaptive grasping, high-force manipulation, shape holding, and navigation in constrained spaces, among others. However, many existing variable stiffness solutions rely on complex actuation schemes, continuous input power, or monolithic designs, limiting their modularity and scalability. This paper presents the Programmable Locking Cell (PLC)-a modular, tendon-driven unit that achieves discrete stiffness modulation through mechanically interlocked joints actuated by cable tension. Each unit transitions between compliant and firm states via structural engagement, and the assembled system exhibits high stiffness variation-up to 950% per unit-without susceptibility to damage under high payload in the firm state. Multiple PLC units can be assembled into reconfigurable robotic structures with spatially programmable stiffness. We validate the design through two functional prototypes: (1) a variable-stiffness gripper capable of adaptive grasping, firm holding, and in-hand manipulation; and (2) a pipe-traversing robot composed of serial PLC units that achieves shape adaptability and stiffness control in confined environments. These results demonstrate the PLC as a scalable, structure-centric mechanism for programmable stiffness and motion, enabling robotic systems with reconfigurable morphology and task-adaptive interaction.
Unified Manipulability and Compliance Analysis of Modular Soft-Rigid Hybrid Fingers
Apr 18, 2025This paper presents a unified framework to analyze the manipulability and compliance of modular soft-rigid hybrid robotic fingers. The approach applies to both hydraulic and pneumatic actuation systems. A Jacobian-based formulation maps actuator inputs to joint and task-space responses. Hydraulic actuators are modeled under incompressible assumptions, while pneumatic actuators are described using nonlinear pressure-volume relations. The framework enables consistent evaluation of manipulability ellipsoids and compliance matrices across actuation modes. We validate the analysis using two representative hands: DexCo (hydraulic) and Edgy-2 (pneumatic). Results highlight actuation-dependent trade-offs in dexterity and passive stiffness. These findings provide insights for structure-aware design and actuator selection in soft-rigid robotic fingers.
Fish Mouth Inspired Origami Gripper for Robust Multi-Type Underwater Grasping
Mar 14, 2025



Robotic grasping and manipulation in underwater environments present unique challenges for robotic hands traditionally used on land. These challenges stem from dynamic water conditions, a wide range of object properties from soft to stiff, irregular object shapes, and varying surface frictions. One common approach involves developing finger-based hands with embedded compliance using underactuation and soft actuators. This study introduces an effective alternative solution that does not rely on finger-based hand designs. We present a fish mouth inspired origami gripper that utilizes a single degree of freedom to perform a variety of robust grasping tasks underwater. The innovative structure transforms a simple uniaxial pulling motion into a grasping action based on the Yoshimura crease pattern folding. The origami gripper offers distinct advantages, including scalable and optimizable design, grasping compliance, and robustness, with four grasping types: pinch, power grasp, simultaneous grasping of multiple objects, and scooping from the seabed. In this work, we detail the design, modeling, fabrication, and validation of a specialized underwater gripper capable of handling various marine creatures, including jellyfish, crabs, and abalone. By leveraging an origami and bio-inspired approach, the presented gripper demonstrates promising potential for robotic grasping and manipulation in underwater environments.
Prismatic-Bending Transformable (PBT) Joint for a Modular, Foldable Manipulator with Enhanced Reachability and Dexterity
Mar 07, 2025



Robotic manipulators, traditionally designed with classical joint-link articulated structures, excel in industrial applications but face challenges in human-centered and general-purpose tasks requiring greater dexterity and adaptability. Addressing these limitations, we introduce the Prismatic-Bending Transformable (PBT) Joint, a novel design inspired by the scissors mechanism, enabling transformable kinematic chains. Each PBT joint module provides three degrees of freedom-bending, rotation, and elongation/contraction-allowing scalable and reconfigurable assemblies to form diverse kinematic configurations tailored to specific tasks. This innovative design surpasses conventional systems, delivering superior flexibility and performance across various applications. We present the design, modeling, and experimental validation of the PBT joint, demonstrating its integration into modular and foldable robotic arms. The PBT joint functions as a single SKU, enabling manipulators to be constructed entirely from standardized PBT joints without additional customized components. It also serves as a modular extension for existing systems, such as wrist modules, streamlining design, deployment, transportation, and maintenance. Three sizes-large, medium, and small-have been developed and integrated into robotic manipulators, highlighting their enhanced dexterity, reachability, and adaptability for manipulation tasks. This work represents a significant advancement in robotic design, offering scalable and efficient solutions for dynamic and unstructured environments.
Few-shot Sim2Real Based on High Fidelity Rendering with Force Feedback Teleoperation
Mar 03, 2025Teleoperation offers a promising approach to robotic data collection and human-robot interaction. However, existing teleoperation methods for data collection are still limited by efficiency constraints in time and space, and the pipeline for simulation-based data collection remains unclear. The problem is how to enhance task performance while minimizing reliance on real-world data. To address this challenge, we propose a teleoperation pipeline for collecting robotic manipulation data in simulation and training a few-shot sim-to-real visual-motor policy. Force feedback devices are integrated into the teleoperation system to provide precise end-effector gripping force feedback. Experiments across various manipulation tasks demonstrate that force feedback significantly improves both success rates and execution efficiency, particularly in simulation. Furthermore, experiments with different levels of visual rendering quality reveal that enhanced visual realism in simulation substantially boosts task performance while reducing the need for real-world data.
Physics-Aware Robotic Palletization with Online Masking Inference
Feb 19, 2025The efficient planning of stacking boxes, especially in the online setting where the sequence of item arrivals is unpredictable, remains a critical challenge in modern warehouse and logistics management. Existing solutions often address box size variations, but overlook their intrinsic and physical properties, such as density and rigidity, which are crucial for real-world applications. We use reinforcement learning (RL) to solve this problem by employing action space masking to direct the RL policy toward valid actions. Unlike previous methods that rely on heuristic stability assessments which are difficult to assess in physical scenarios, our framework utilizes online learning to dynamically train the action space mask, eliminating the need for manual heuristic design. Extensive experiments demonstrate that our proposed method outperforms existing state-of-the-arts. Furthermore, we deploy our learned task planner in a real-world robotic palletizer, validating its practical applicability in operational settings.
Adaptive Energy Regularization for Autonomous Gait Transition and Energy-Efficient Quadruped Locomotion
Mar 29, 2024



In reinforcement learning for legged robot locomotion, crafting effective reward strategies is crucial. Pre-defined gait patterns and complex reward systems are widely used to stabilize policy training. Drawing from the natural locomotion behaviors of humans and animals, which adapt their gaits to minimize energy consumption, we propose a simplified, energy-centric reward strategy to foster the development of energy-efficient locomotion across various speeds in quadruped robots. By implementing an adaptive energy reward function and adjusting the weights based on velocity, we demonstrate that our approach enables ANYmal-C and Unitree Go1 robots to autonomously select appropriate gaits, such as four-beat walking at lower speeds and trotting at higher speeds, resulting in improved energy efficiency and stable velocity tracking compared to previous methods using complex reward designs and prior gait knowledge. The effectiveness of our policy is validated through simulations in the IsaacGym simulation environment and on real robots, demonstrating its potential to facilitate stable and adaptive locomotion.
Robust In-Hand Manipulation with Extrinsic Contacts
Mar 27, 2024

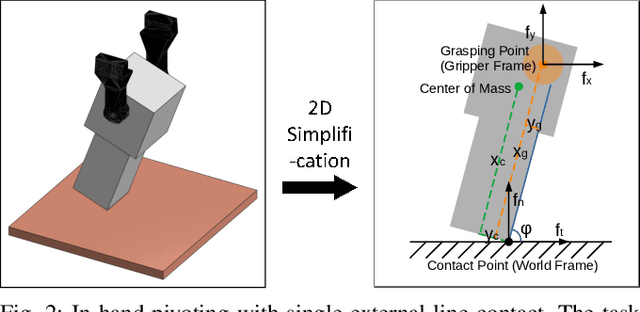
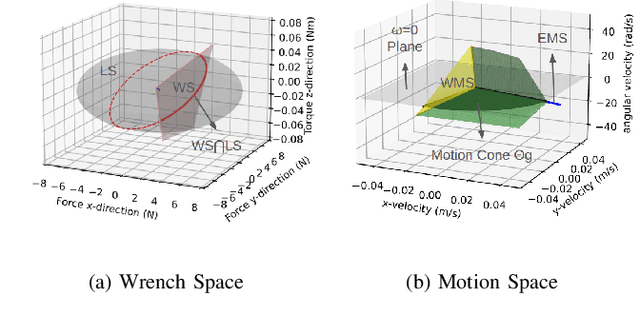
We present in-hand manipulation tasks where a robot moves an object in grasp, maintains its external contact mode with the environment, and adjusts its in-hand pose simultaneously. The proposed manipulation task leads to complex contact interactions which can be very susceptible to uncertainties in kinematic and physical parameters. Therefore, we propose a robust in-hand manipulation method, which consists of two parts. First, an in-gripper mechanics model that computes a na\"ive motion cone assuming all parameters are precise. Then, a robust planning method refines the motion cone to maintain desired contact mode regardless of parametric errors. Real-world experiments were conducted to illustrate the accuracy of the mechanics model and the effectiveness of the robust planning framework in the presence of kinematics parameter errors.
In-Hand Following of Deformable Linear Objects Using Dexterous Fingers with Tactile Sensing
Mar 19, 2024

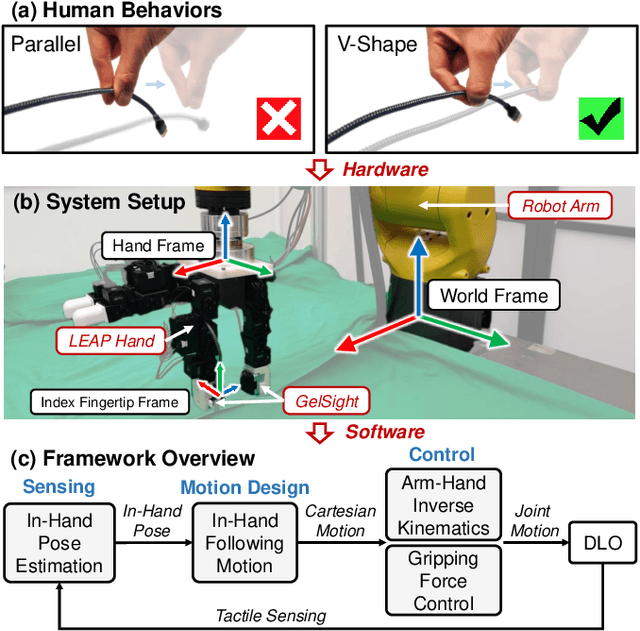
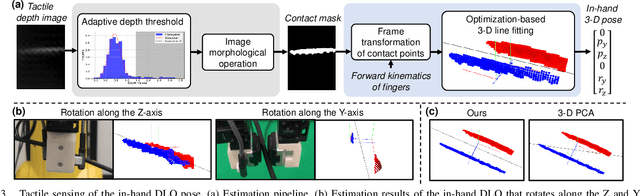
Most research on deformable linear object (DLO) manipulation assumes rigid grasping. However, beyond rigid grasping and re-grasping, in-hand following is also an essential skill that humans use to dexterously manipulate DLOs, which requires continuously changing the grasp point by in-hand sliding while holding the DLO to prevent it from falling. Achieving such a skill is very challenging for robots without using specially designed but not versatile end-effectors. Previous works have attempted using generic parallel grippers, but their robustness is unsatisfactory owing to the conflict between following and holding, which is hard to balance with a one-degree-of-freedom gripper. In this work, inspired by how humans use fingers to follow DLOs, we explore the usage of a generic dexterous hand with tactile sensing to imitate human skills and achieve robust in-hand DLO following. To enable the hardware system to function in the real world, we develop a framework that includes Cartesian-space arm-hand control, tactile-based in-hand 3-D DLO pose estimation, and task-specific motion design. Experimental results demonstrate the significant superiority of our method over using parallel grippers, as well as its great robustness, generalizability, and efficiency.