 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-Image-2.0 Technical Report
May 11, 2026We present Qwen-Image-2.0, an omni-capable image generation foundation model that unifies high-fidelity generation and precise image editing within a single framework. Despite recent progress, existing models still struggle with ultra-long text rendering, multilingual typography, high-resolution photorealism, robust instruction following, and efficient deployment, especially in text-rich and compositionally complex scenarios. Qwen-Image-2.0 addresses these challenges by coupling Qwen3-VL as the condition encoder with a Multimodal Diffusion Transformer for joint condition-target modeling, supported by large-scale data curation and a customized multi-stage training pipeline. This enables strong multimodal understanding while preserving flexible generation and editing capabilities. The model supports instructions of up to 1K tokens for generating text-rich content such as slides, posters, infographics, and comics, while significantly improving multilingual text fidelity and typography. It also enhances photorealistic generation with richer details, more realistic textures, and coherent lighting, and follows complex prompts more reliably across diverse styles. Extensive human evaluations show that Qwen-Image-2.0 substantially outperforms previous Qwen-Image models in both generation and editing, marking a step toward more general, reliable, and practical image generation foundation models.
Moaw: Unleashing Motion Awareness for Video Diffusion Models
Jan 19, 2026Video diffusion models, trained on large-scale datasets, naturally capture correspondences of shared features across frames. Recent works have exploited this property for tasks such as optical flow prediction and tracking in a zero-shot setting. Motivated by these findings, we investigate whether supervised training can more fully harness the tracking capability of video diffusion models. To this end, we propose Moaw, a framework that unleashes motion awareness for video diffusion models and leverages it to facilitate motion transfer. Specifically, we train a diffusion model for motion perception, shifting its modality from image-to-video generation to video-to-dense-tracking. We then construct a motion-labeled dataset to identify features that encode the strongest motion information, and inject them into a structurally identical video generation model. Owing to the homogeneity between the two networks, these features can be naturally adapted in a zero-shot manner, enabling motion transfer without additional adapters. Our work provides a new paradigm for bridging generative modeling and motion understanding, paving the way for more unified and controllable video learning frameworks.
FaTRQ: Tiered Residual Quantization for LLM Vector Search in Far-Memory-Aware ANNS Systems
Jan 15, 2026Approximate Nearest-Neighbor Search (ANNS) is a key technique in retrieval-augmented generation (RAG), enabling rapid identification of the most relevant high-dimensional embeddings from massive vector databases. Modern ANNS engines accelerate this process using prebuilt indexes and store compressed vector-quantized representations in fast memory. However, they still rely on a costly second-pass refinement stage that reads full-precision vectors from slower storage like SSDs. For modern text and multimodal embeddings, these reads now dominate the latency of the entire query. We propose FaTRQ, a far-memory-aware refinement system using tiered memory that eliminates the need to fetch full vectors from storage. It introduces a progressive distance estimator that refines coarse scores using compact residuals streamed from far memory. Refinement stops early once a candidate is provably outside the top-k. To support this, we propose tiered residual quantization, which encodes residuals as ternary values stored efficiently in far memory. A custom accelerator is deployed in a CXL Type-2 device to perform low-latency refinement locally. Together, FaTRQ improves the storage efficiency by 2.4$\times$ and improves the throughput by up to 9$ \times$ than SOTA GPU ANNS system.
Physics-Aware Robotic Palletization with Online Masking Inference
Feb 19, 2025The efficient planning of stacking boxes, especially in the online setting where the sequence of item arrivals is unpredictable, remains a critical challenge in modern warehouse and logistics management. Existing solutions often address box size variations, but overlook their intrinsic and physical properties, such as density and rigidity, which are crucial for real-world applications. We use reinforcement learning (RL) to solve this problem by employing action space masking to direct the RL policy toward valid actions. Unlike previous methods that rely on heuristic stability assessments which are difficult to assess in physical scenarios, our framework utilizes online learning to dynamically train the action space mask, eliminating the need for manual heuristic design. Extensive experiments demonstrate that our proposed method outperforms existing state-of-the-arts. Furthermore, we deploy our learned task planner in a real-world robotic palletizer, validating its practical applicability in operational settings.
Predictive Lagrangian Optimization for Constrained Reinforcement Learning
Jan 25, 2025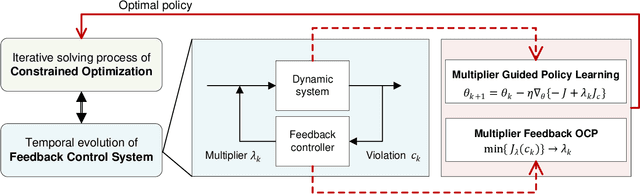
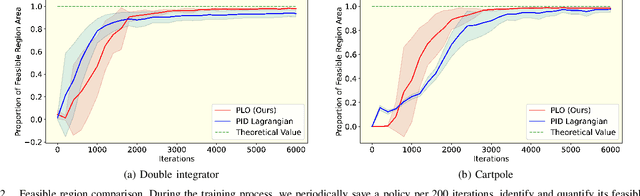
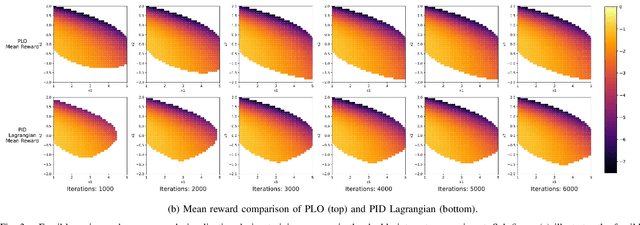

Constrained optimization is popularly seen in reinforcement learning for addressing complex control tasks. From the perspective of dynamic system, iteratively solving a constrained optimization problem can be framed as the temporal evolution of a feedback control system. Classical constrained optimization methods, such as penalty and Lagrangian approaches, inherently use proportional and integral feedback controllers. In this paper, we propose a more generic equivalence framework to build the connection between constrained optimization and feedback control system, for the purpose of developing more effective constrained RL algorithms. Firstly, we define that each step of the system evolution determines the Lagrange multiplier by solving a multiplier feedback optimal control problem (MFOCP). In this problem, the control input is multiplier, the state is policy parameters, the dynamics is described by policy gradient descent, and the objective is to minimize constraint violations. Then, we introduce a multiplier guided policy learning (MGPL) module to perform policy parameters updating. And we prove that the resulting optimal policy, achieved through alternating MFOCP and MGPL, aligns with the solution of the primal constrained RL problem, thereby establishing our equivalence framework. Furthermore, we point out that the existing PID Lagrangian is merely one special case within our framework that utilizes a PID controller. We also accommodate the integration of other various feedback controllers, thereby facilitating the development of new algorithms. As a representative, we employ model predictive control (MPC) as the feedback controller and consequently propose a new algorithm called predictive Lagrangian optimization (PLO). Numerical experiments demonstrate its superiority over the PID Lagrangian method, achieving a larger feasible region up to 7.2% and a comparable average reward.
Fine-grained graph representation learning for heterogeneous mobile networks with attentive fusion and contrastive learning
Dec 10, 2024



AI becomes increasingly vital for telecom industry, as the burgeoning complexity of upcoming mobile communication networks places immense pressure on network operators. While there is a growing consensus that intelligent network self-driving holds the key, it heavily relies on expert experience and knowledge extracted from network data. In an effort to facilitate convenient analytics and utilization of wireless big data, we introduce the concept of knowledge graphs into the field of mobile networks, giving rise to what we term as wireless data knowledge graphs (WDKGs). However, the heterogeneous and dynamic nature of communication networks renders manual WDKG construction both prohibitively costly and error-prone, presenting a fundamental challenge. In this context, we propose an unsupervised data-and-model driven graph structure learning (DMGSL) framework, aimed at automating WDKG refinement and updating. Tackling WDKG heterogeneity involves stratifying the network into homogeneous layers and refining it at a finer granularity. Furthermore, to capture WDKG dynamics effectively, we segment the network into static snapshots based on the coherence time and harness the power of recurrent neural networks to incorporate historical information. Extensive experiments conducted on the established WDKG demonstrate the superiority of the DMGSL over the baselines, particularly in terms of node classification accuracy.
SBoRA: Low-Rank Adaptation with Regional Weight Updates
Jul 10, 2024



This paper introduces Standard Basis LoRA (SBoRA), a novel parameter-efficient fine-tuning approach for Large Language Models that builds upon the pioneering works of Low-Rank Adaptation (LoRA) and Orthogonal Adaptation. SBoRA further reduces the computational and memory requirements of LoRA while enhancing learning performance. By leveraging orthogonal standard basis vectors to initialize one of the low-rank matrices, either A or B, SBoRA enables regional weight updates and memory-efficient fine-tuning. This approach gives rise to two variants, SBoRA-FA and SBoRA-FB, where only one of the matrices is updated, resulting in a sparse update matrix with a majority of zero rows or columns. Consequently, the majority of the fine-tuned model's weights remain unchanged from the pre-trained weights. This characteristic of SBoRA, wherein regional weight updates occur, is reminiscent of the modular organization of the human brain, which efficiently adapts to new tasks. Our empirical results demonstrate the superiority of SBoRA-FA over LoRA in various fine-tuning tasks, including commonsense reasoning and arithmetic reasoning. Furthermore, we evaluate the effectiveness of QSBoRA on quantized LLaMA models of varying scales, highlighting its potential for efficient adaptation to new tasks. Code is available at https://github.com/cityuhkai/SBoRA
Spatial-Temporal Attention Model for Traffic State Estimation with Sparse Internet of Vehicles
Jul 10, 2024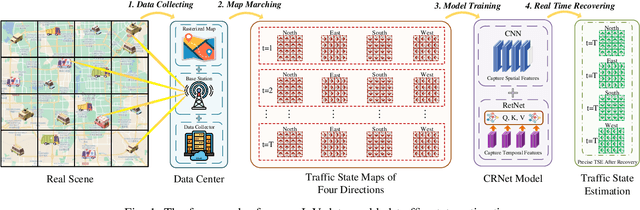
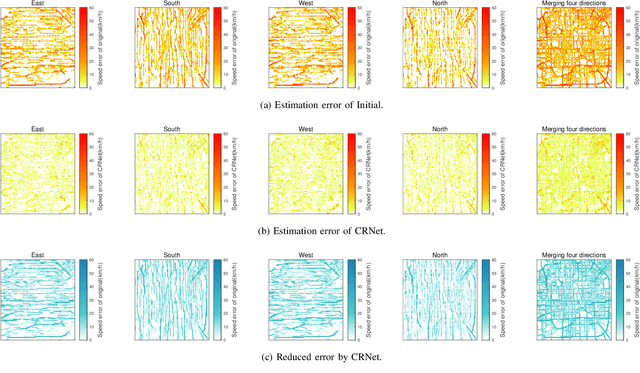
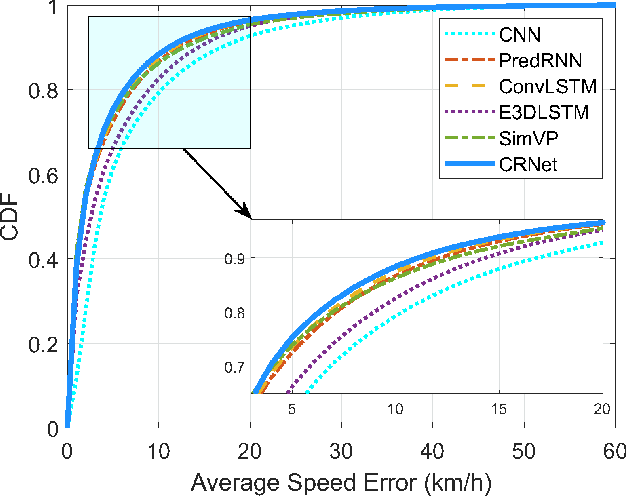

The growing number of connected vehicles offers an opportunity to leverage internet of vehicles (IoV) data for traffic state estimation (TSE) which plays a crucial role in intelligent transportation systems (ITS). By utilizing only a portion of IoV data instead of the entire dataset, the significant overheads associated with collecting and processing large amounts of data can be avoided. In this paper, we introduce a novel framework that utilizes sparse IoV data to achieve cost-effective TSE. Particularly, we propose a novel spatial-temporal attention model called the convolutional retentive network (CRNet) to improve the TSE accuracy by mining spatial-temporal traffic state correlations. The model employs the convolutional neural network (CNN) for spatial correlation aggregation and the retentive network (RetNet) based on the attention mechanism to extract temporal correlations. Extensive simulations on a real-world IoV dataset validate the advantage of the proposed TSE approach in achieving accurate TSE using sparse IoV data, demonstrating its cost effectiveness and practicality for real-world applications.
Coverage Analysis of Downlink Transmission in Multi-Connectivity Cellular V2X Networks
May 27, 2024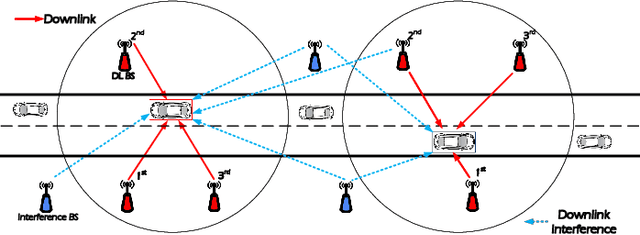

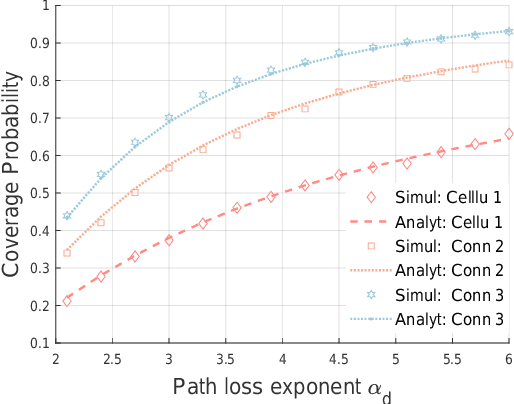
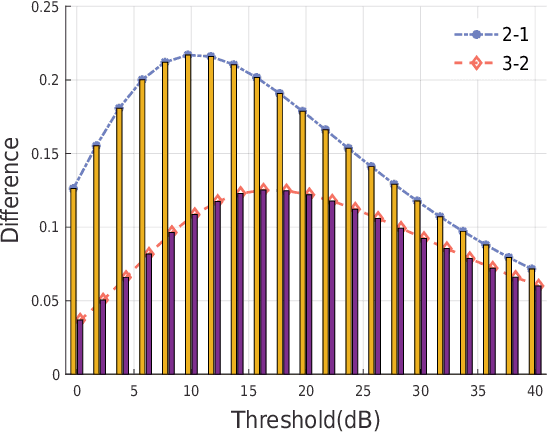
With the increasing of connected vehicles in the fifth-generation mobile communication networks (5G) and beyond 5G (B5G), ensuring the reliable and high-speed cellular vehicle-to-everything (C-V2X) communication has posed significant challenges due to the high mobility of vehicles. For improving the network performance and reliability, multi-connectivity technology has emerged as a crucial transmission mode for C-V2X in the 5G era. To this end, this paper proposes a framework for analyzing the performance of multi-connectivity in C-V2X downlink transmission, with a focus on the performance indicators of joint distance distribution and coverage probability. Specifically, we first derive the joint distance distribution of multi-connectivity. By leveraging the tools of stochastic geometry, we then obtain the analytical expressions of coverage probability based on the previous results for general multi-connectivity cases in C-V2X. Subsequently, we evaluate the effect of path loss exponent and downlink base station density on coverage probability based on the proposed analytical framework. Finally, extensive Monte Carlo simulations are conducted to validate the effectiveness of the proposed analytical framework and the simulation results reveal that multi-connectivity technology can significantly enhance the coverage probability in C-V2X.
* 6 pagers, 5 figures. arXiv admin note: substantial text overlap with arXiv:2404.17823
Performance Analysis for Downlink Transmission in Multi-Connectivity Cellular V2X Networks
Apr 27, 2024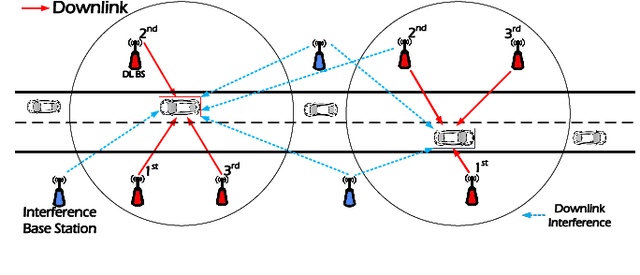

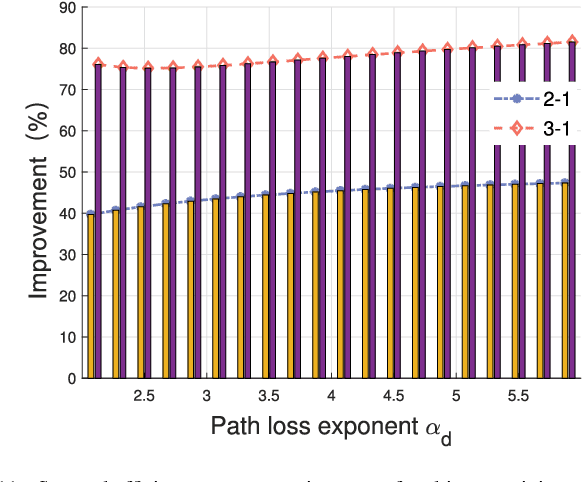
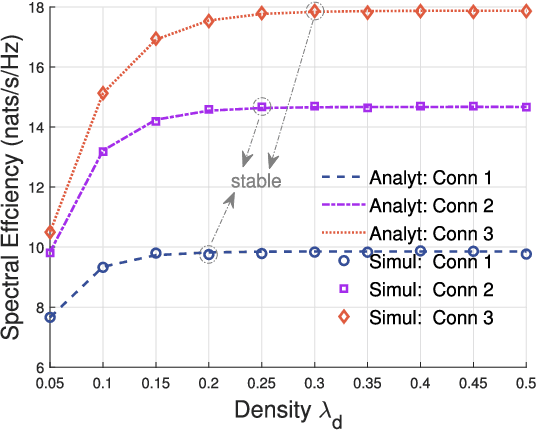
With the ever-increasing number of connected vehicles in the fifth-generation mobile communication networks (5G) and beyond 5G (B5G), ensuring the reliability and high-speed demand of cellular vehicle-to-everything (C-V2X) communication in scenarios where vehicles are moving at high speeds poses a significant challenge.Recently, multi-connectivity technology has become a promising network access paradigm for improving network performance and reliability for C-V2X in the 5G and B5G era. To this end, this paper proposes an analytical framework for the performance of downlink in multi-connectivity C-V2X networks. Specifically, by modeling the vehicles and base stations as one-dimensional Poisson point processes, we first derive and analyze the joint distance distribution of multi-connectivity. Then through leveraging the tools of stochastic geometry, the coverage probability and spectral efficiency are obtained based on the previous results for general multi-connectivity cases in C-V2X. Additionally, we evaluate the effect of path loss exponent and the density of downlink base station on system performance indicators. We demonstrate through extensive Monte Carlo simulations that multi-connectivity technology can effectively enhance network performance in C-V2X. Our findings have important implications for the research and application of multi-connectivity C-V2X in the 5G and B5G era.