 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFronthaul-Efficient Distributed Cooperative 3D Positioning with Quantized Latent CSI Embeddings
Jan 31, 2026High-precision three-dimensional (3D) positioning in dense urban non-line-of-sight (NLOS) environments benefits significantly from cooperation among multiple distributed base stations (BSs). However, forwarding raw CSI from multiple BSs to a central unit (CU) incurs prohibitive fronthaul overhead, which limits scalable cooperative positioning in practice. This paper proposes a learning-based edge-cloud cooperative positioning framework under limited-capacity fronthaul constraints. In the proposed architecture, a neural network is deployed at each BS to compress the locally estimated CSI into a quantized representation subject to a fixed fronthaul payload. The quantized CSI is transmitted to the CU, which performs cooperative 3D positioning by jointly processing the compressed CSI received from multiple BSs. The proposed framework adopts a two-stage training strategy consisting of self-supervised local training at the BSs and end-to-end joint training for positioning at the CU. Simulation results based on a 3.5~GHz 5G NR compliant urban ray-tracing scenario with six BSs and 20~MHz bandwidth show that the proposed method achieves a mean 3D positioning error of 0.48~m and a 90th-percentile error of 0.83~m, while reducing the fronthaul payload to 6.25% of lossless CSI forwarding. The achieved performance is close to that of cooperative positioning with full CSI exchange.
CMANet: Channel-Masked Attention Network for Cooperative Multi-Base-Station 3D Positioning
Jan 31, 2026Achieving ubiquitous high-accuracy localization is crucial for next-generation wireless systems, yet remains challenging in multipath-rich urban environments. By exploiting the fine-grained multipath characteristics embedded in channel state information (CSI), more reliable and precise localization can be achieved. To address this, we present CMANet, a multi-BS cooperative positioning architecture that performs feature-level fusion of raw CSI using the proposed Channel Masked Attention (CMA) mechanism. The CMA encoder injects a physically grounded prior--per-BS channel gain--into the attention weights, thus emphasizing reliable links and suppressing spurious multipath. A lightweight LSTM decoder then treats subcarriers as a sequence to accumulate frequency-domain evidence into a final 3D position estimate. In a typical 5G NR-compliant urban simulation, CMANet achieves less than 0.5m median error and 1.0m 90th-percentile error, outperforming state-of-the-art benchmarks. Ablations verify the necessity of CMA and frequency accumulation. CMANet is edge-deployable and exemplifies an Integrated Sensing and Communication (ISAC)-aligned, cooperative paradigm for multi-BS CSI positioning.
Modality-AGnostic Image Cascade (MAGIC) for Multi-Modality Cardiac Substructure Segmentation
Jun 12, 2025Cardiac substructures are essential in thoracic radiation therapy planning to minimize risk of radiation-induced heart disease. Deep learning (DL) offers efficient methods to reduce contouring burden but lacks generalizability across different modalities and overlapping structures. This work introduces and validates a Modality-AGnostic Image Cascade (MAGIC) for comprehensive and multi-modal cardiac substructure segmentation. MAGIC is implemented through replicated encoding and decoding branches of an nnU-Net-based, U-shaped backbone conserving the function of a single model. Twenty cardiac substructures (heart, chambers, great vessels (GVs), valves, coronary arteries (CAs), and conduction nodes) from simulation CT (Sim-CT), low-field MR-Linac, and cardiac CT angiography (CCTA) modalities were manually delineated and used to train (n=76), validate (n=15), and test (n=30) MAGIC. Twelve comparison models (four segmentation subgroups across three modalities) were equivalently trained. All methods were compared for training efficiency and against reference contours using the Dice Similarity Coefficient (DSC) and two-tailed Wilcoxon Signed-Rank test (threshold, p<0.05). Average DSC scores were 0.75(0.16) for Sim-CT, 0.68(0.21) for MR-Linac, and 0.80(0.16) for CCTA. MAGIC outperforms the comparison in 57% of cases, with limited statistical differences. MAGIC offers an effective and accurate segmentation solution that is lightweight and capable of segmenting multiple modalities and overlapping structures in a single model. MAGIC further enables clinical implementation by simplifying the computational requirements and offering unparalleled flexibility for clinical settings.
Coverage Analysis of Downlink Transmission in Multi-Connectivity Cellular V2X Networks
May 27, 2024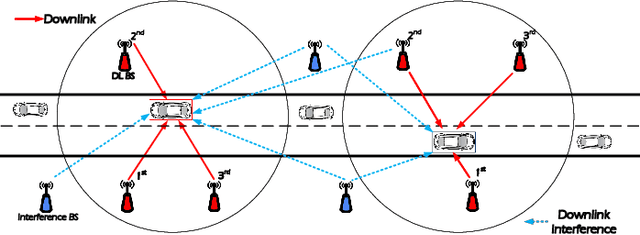

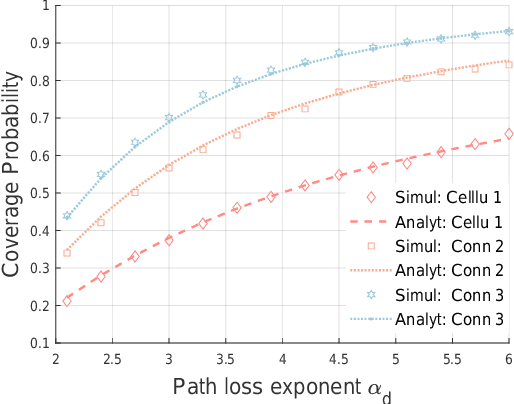
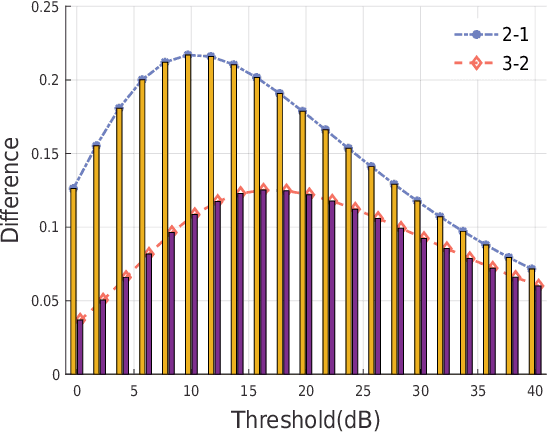
With the increasing of connected vehicles in the fifth-generation mobile communication networks (5G) and beyond 5G (B5G), ensuring the reliable and high-speed cellular vehicle-to-everything (C-V2X) communication has posed significant challenges due to the high mobility of vehicles. For improving the network performance and reliability, multi-connectivity technology has emerged as a crucial transmission mode for C-V2X in the 5G era. To this end, this paper proposes a framework for analyzing the performance of multi-connectivity in C-V2X downlink transmission, with a focus on the performance indicators of joint distance distribution and coverage probability. Specifically, we first derive the joint distance distribution of multi-connectivity. By leveraging the tools of stochastic geometry, we then obtain the analytical expressions of coverage probability based on the previous results for general multi-connectivity cases in C-V2X. Subsequently, we evaluate the effect of path loss exponent and downlink base station density on coverage probability based on the proposed analytical framework. Finally, extensive Monte Carlo simulations are conducted to validate the effectiveness of the proposed analytical framework and the simulation results reveal that multi-connectivity technology can significantly enhance the coverage probability in C-V2X.
* 6 pagers, 5 figures. arXiv admin note: substantial text overlap with arXiv:2404.17823
Performance Analysis for Downlink Transmission in Multi-Connectivity Cellular V2X Networks
Apr 27, 2024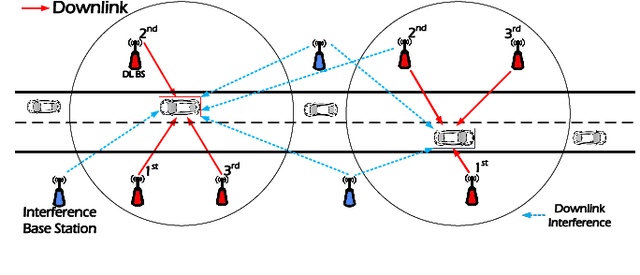

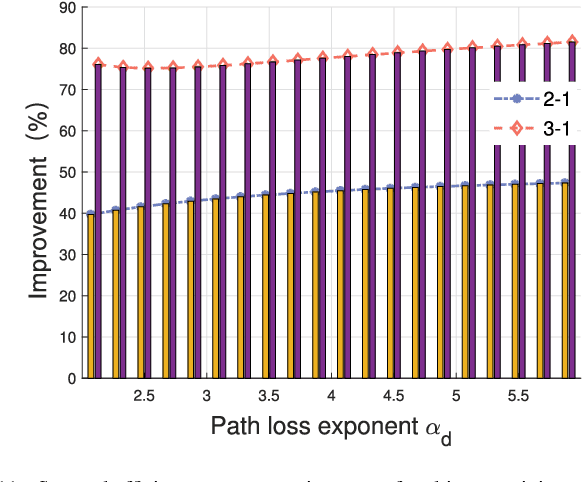
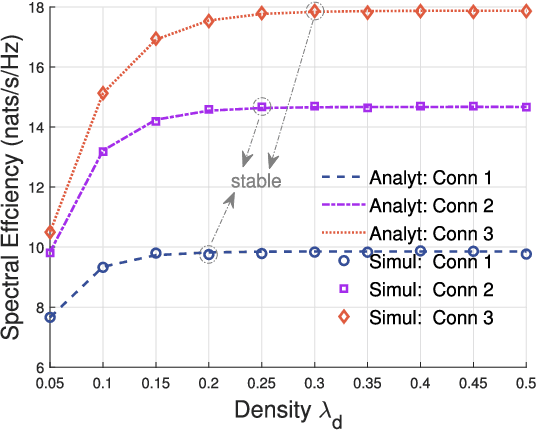
With the ever-increasing number of connected vehicles in the fifth-generation mobile communication networks (5G) and beyond 5G (B5G), ensuring the reliability and high-speed demand of cellular vehicle-to-everything (C-V2X) communication in scenarios where vehicles are moving at high speeds poses a significant challenge.Recently, multi-connectivity technology has become a promising network access paradigm for improving network performance and reliability for C-V2X in the 5G and B5G era. To this end, this paper proposes an analytical framework for the performance of downlink in multi-connectivity C-V2X networks. Specifically, by modeling the vehicles and base stations as one-dimensional Poisson point processes, we first derive and analyze the joint distance distribution of multi-connectivity. Then through leveraging the tools of stochastic geometry, the coverage probability and spectral efficiency are obtained based on the previous results for general multi-connectivity cases in C-V2X. Additionally, we evaluate the effect of path loss exponent and the density of downlink base station on system performance indicators. We demonstrate through extensive Monte Carlo simulations that multi-connectivity technology can effectively enhance network performance in C-V2X. Our findings have important implications for the research and application of multi-connectivity C-V2X in the 5G and B5G era.
ReTaSA: A Nonparametric Functional Estimation Approach for Addressing Continuous Target Shift
Jan 29, 2024


The presence of distribution shifts poses a significant challenge for deploying modern machine learning models in real-world applications. This work focuses on the target shift problem in a regression setting (Zhang et al., 2013; Nguyen et al., 2016). More specifically, the target variable y (also known as the response variable), which is continuous, has different marginal distributions in the training source and testing domain, while the conditional distribution of features x given y remains the same. While most literature focuses on classification tasks with finite target space, the regression problem has an infinite dimensional target space, which makes many of the existing methods inapplicable. In this work, we show that the continuous target shift problem can be addressed by estimating the importance weight function from an ill-posed integral equation. We propose a nonparametric regularized approach named ReTaSA to solve the ill-posed integral equation and provide theoretical justification for the estimated importance weight function. The effectiveness of the proposed method has been demonstrated with extensive numerical studies on synthetic and real-world datasets.
Channel-Feedback-Free Transmission for Downlink FD-RAN: A Radio Map based Complex-valued Precoding Network Approach
Nov 30, 2023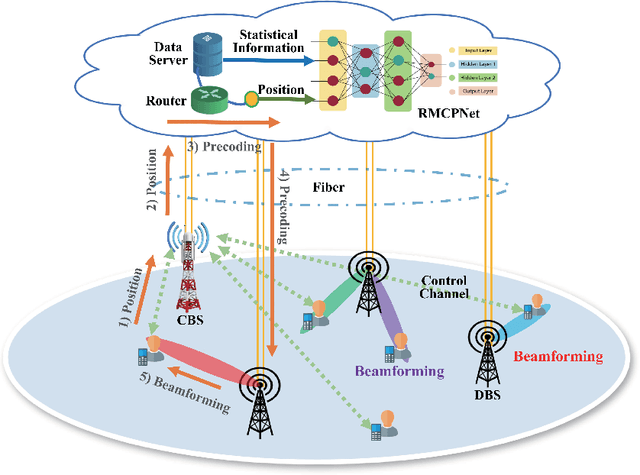
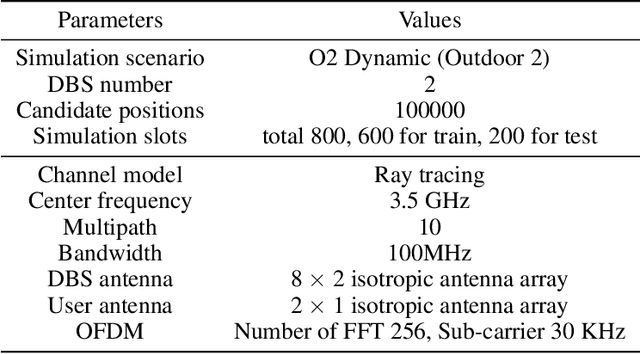
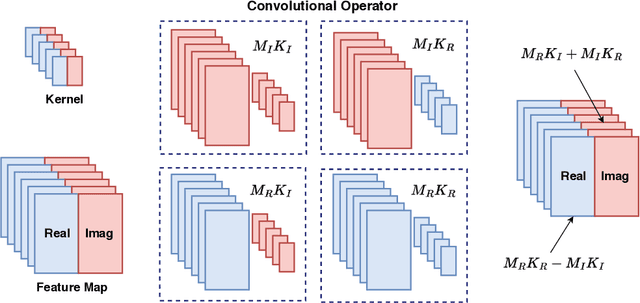
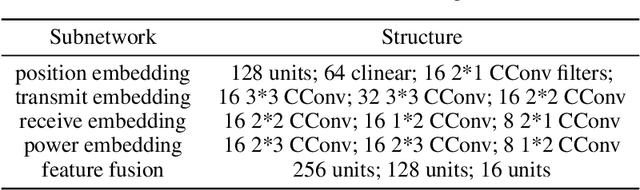
As the demand for high-quality services proliferates, an innovative network architecture, the fully-decoupled RAN (FD-RAN), has emerged for more flexible spectrum resource utilization and lower network costs. However, with the decoupling of uplink base stations and downlink base stations in FD-RAN, the traditional transmission mechanism, which relies on real-time channel feedback, is not suitable as the receiver is not able to feedback accurate and timely channel state information to the transmitter. This paper proposes a novel transmission scheme without relying on physical layer channel feedback. Specifically, we design a radio map based complex-valued precoding network~(RMCPNet) model, which outputs the base station precoding based on user location. RMCPNet comprises multiple subnets, with each subnet responsible for extracting unique modal features from diverse input modalities. Furthermore, the multi-modal embeddings derived from these distinct subnets are integrated within the information fusion layer, culminating in a unified representation. We also develop a specific RMCPNet training algorithm that employs the negative spectral efficiency as the loss function. We evaluate the performance of the proposed scheme on the public DeepMIMO dataset and show that RMCPNet can achieve 16\% and 76\% performance improvements over the conventional real-valued neural network and statistical codebook approach, respectively.
Assumption-lean and Data-adaptive Post-Prediction Inference
Nov 23, 2023

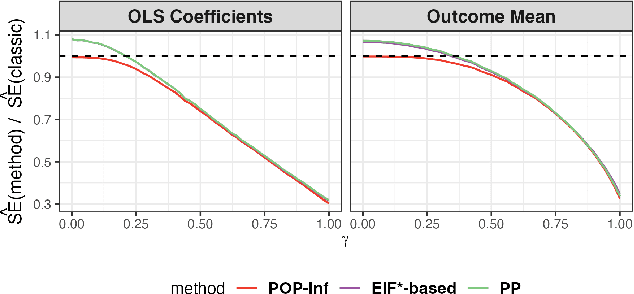

A primary challenge facing modern scientific research is the limited availability of gold-standard data which can be both costly and labor-intensive to obtain. With the rapid development of machine learning (ML), scientists have relied on ML algorithms to predict these gold-standard outcomes with easily obtained covariates. However, these predicted outcomes are often used directly in subsequent statistical analyses, ignoring imprecision and heterogeneity introduced by the prediction procedure. This will likely result in false positive findings and invalid scientific conclusions. In this work, we introduce an assumption-lean and data-adaptive Post-Prediction Inference (POP-Inf) procedure that allows valid and powerful inference based on ML-predicted outcomes. Its "assumption-lean" property guarantees reliable statistical inference without assumptions on the ML-prediction, for a wide range of statistical quantities. Its "data-adaptive'" feature guarantees an efficiency gain over existing post-prediction inference methods, regardless of the accuracy of ML-prediction. We demonstrate the superiority and applicability of our method through simulations and large-scale genomic data.
Sufficient Identification Conditions and Semiparametric Estimation under Missing Not at Random Mechanisms
Jun 10, 2023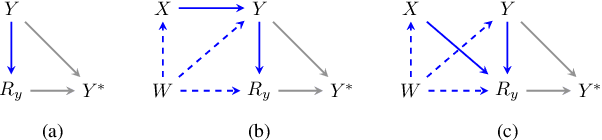
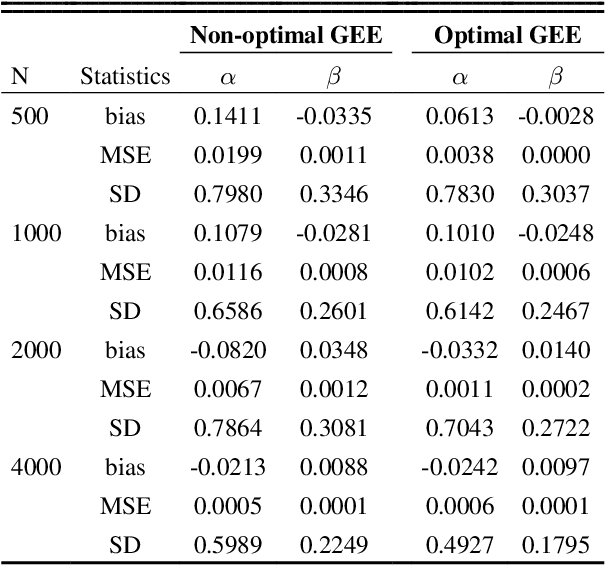
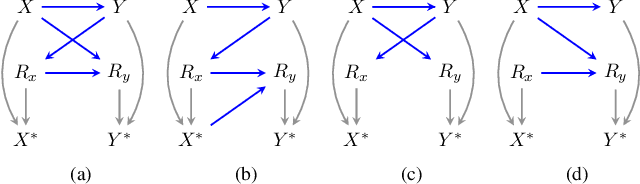
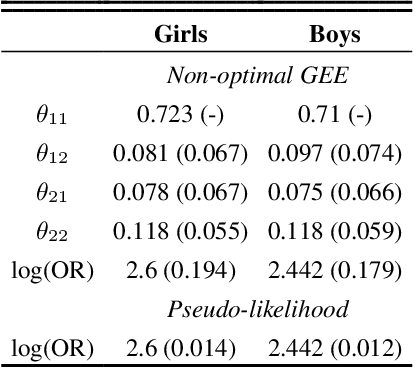
Conducting valid statistical analyses is challenging in the presence of missing-not-at-random (MNAR) data, where the missingness mechanism is dependent on the missing values themselves even conditioned on the observed data. Here, we consider a MNAR model that generalizes several prior popular MNAR models in two ways: first, it is less restrictive in terms of statistical independence assumptions imposed on the underlying joint data distribution, and second, it allows for all variables in the observed sample to have missing values. This MNAR model corresponds to a so-called criss-cross structure considered in the literature on graphical models of missing data that prevents nonparametric identification of the entire missing data model. Nonetheless, part of the complete-data distribution remains nonparametrically identifiable. By exploiting this fact and considering a rich class of exponential family distributions, we establish sufficient conditions for identification of the complete-data distribution as well as the entire missingness mechanism. We then propose methods for testing the independence restrictions encoded in such models using odds ratio as our parameter of interest. We adopt two semiparametric approaches for estimating the odds ratio parameter and establish the corresponding asymptotic theories: one involves maximizing a conditional likelihood with order statistics and the other uses estimating equations. The utility of our methods is illustrated via simulation studies.
ELSA: Efficient Label Shift Adaptation through the Lens of Semiparametric Models
May 30, 2023We study the domain adaptation problem with label shift in this work. Under the label shift context, the marginal distribution of the label varies across the training and testing datasets, while the conditional distribution of features given the label is the same. Traditional label shift adaptation methods either suffer from large estimation errors or require cumbersome post-prediction calibrations. To address these issues, we first propose a moment-matching framework for adapting the label shift based on the geometry of the influence function. Under such a framework, we propose a novel method named \underline{E}fficient \underline{L}abel \underline{S}hift \underline{A}daptation (ELSA), in which the adaptation weights can be estimated by solving linear systems. Theoretically, the ELSA estimator is $\sqrt{n}$-consistent ($n$ is the sample size of the source data) and asymptotically normal. Empirically, we show that ELSA can achieve state-of-the-art estimation performances without post-prediction calibrations, thus, gaining computational efficiency.