 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssumption-lean and Data-adaptive Post-Prediction Inference
Nov 23, 2023

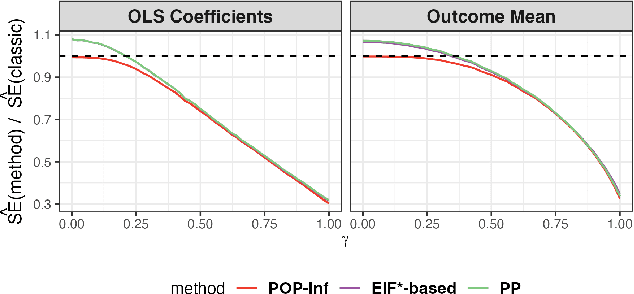

A primary challenge facing modern scientific research is the limited availability of gold-standard data which can be both costly and labor-intensive to obtain. With the rapid development of machine learning (ML), scientists have relied on ML algorithms to predict these gold-standard outcomes with easily obtained covariates. However, these predicted outcomes are often used directly in subsequent statistical analyses, ignoring imprecision and heterogeneity introduced by the prediction procedure. This will likely result in false positive findings and invalid scientific conclusions. In this work, we introduce an assumption-lean and data-adaptive Post-Prediction Inference (POP-Inf) procedure that allows valid and powerful inference based on ML-predicted outcomes. Its "assumption-lean" property guarantees reliable statistical inference without assumptions on the ML-prediction, for a wide range of statistical quantities. Its "data-adaptive'" feature guarantees an efficiency gain over existing post-prediction inference methods, regardless of the accuracy of ML-prediction. We demonstrate the superiority and applicability of our method through simulations and large-scale genomic data.
Source data selection for out-of-domain generalization
Feb 04, 2022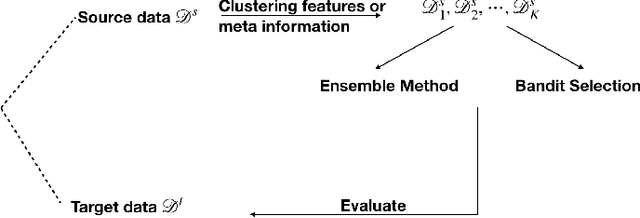

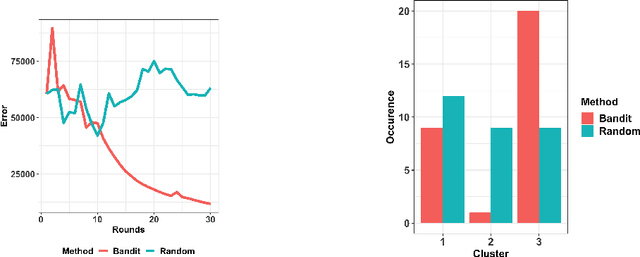

Models that perform out-of-domain generalization borrow knowledge from heterogeneous source data and apply it to a related but distinct target task. Transfer learning has proven effective for accomplishing this generalization in many applications. However, poor selection of a source dataset can lead to poor performance on the target, a phenomenon called negative transfer. In order to take full advantage of available source data, this work studies source data selection with respect to a target task. We propose two source selection methods that are based on the multi-bandit theory and random search, respectively. We conduct a thorough empirical evaluation on both simulated and real data. Our proposals can be also viewed as diagnostics for the existence of a reweighted source subsamples that perform better than the random selection of available samples.
Interactive Visualization and Representation Analysis Applied to Glacier Segmentation
Dec 11, 2021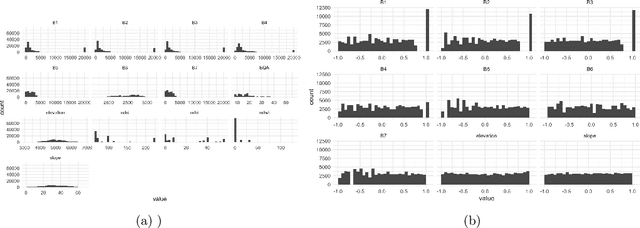
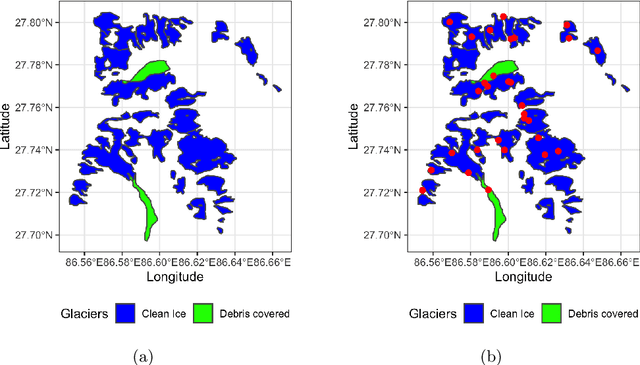
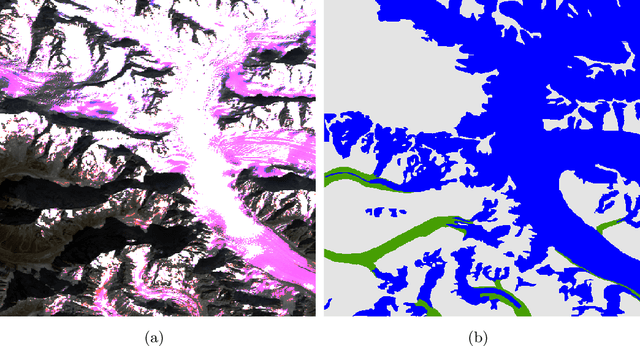
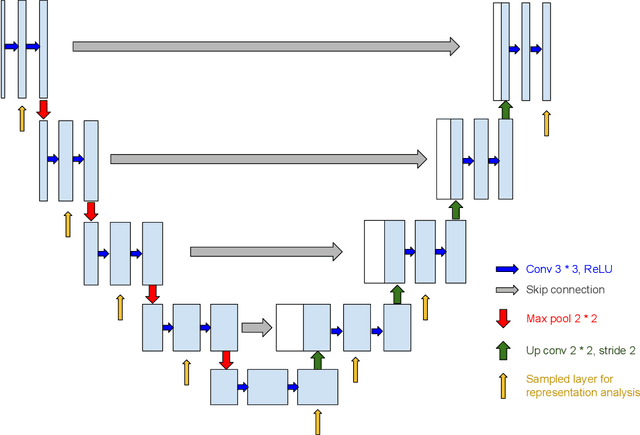
Interpretability has attracted increasing attention in earth observation problems. We apply interactive visualization and representation analysis to guide interpretation of glacier segmentation models. We visualize the activations from a U-Net to understand and evaluate the model performance. We build an online interface using the Shiny R package to provide comprehensive error analysis of the predictions. Users can interact with the panels and discover model failure modes. Further, we discuss how visualization can provide sanity checks during data preprocessing and model training.