 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssumption-lean and Data-adaptive Post-Prediction Inference
Paper and Code


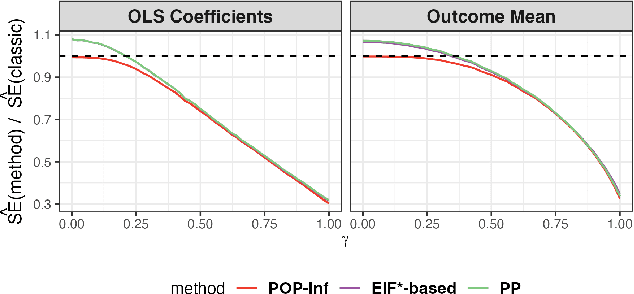

A primary challenge facing modern scientific research is the limited availability of gold-standard data which can be both costly and labor-intensive to obtain. With the rapid development of machine learning (ML), scientists have relied on ML algorithms to predict these gold-standard outcomes with easily obtained covariates. However, these predicted outcomes are often used directly in subsequent statistical analyses, ignoring imprecision and heterogeneity introduced by the prediction procedure. This will likely result in false positive findings and invalid scientific conclusions. In this work, we introduce an assumption-lean and data-adaptive Post-Prediction Inference (POP-Inf) procedure that allows valid and powerful inference based on ML-predicted outcomes. Its "assumption-lean" property guarantees reliable statistical inference without assumptions on the ML-prediction, for a wide range of statistical quantities. Its "data-adaptive'" feature guarantees an efficiency gain over existing post-prediction inference methods, regardless of the accuracy of ML-prediction. We demonstrate the superiority and applicability of our method through simulations and large-scale genomic data.