 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Agnostic Machine Learning-Assisted Inference
May 30, 2024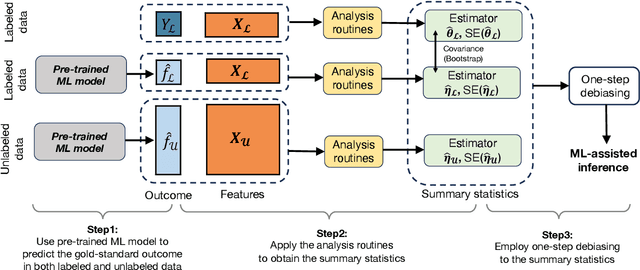
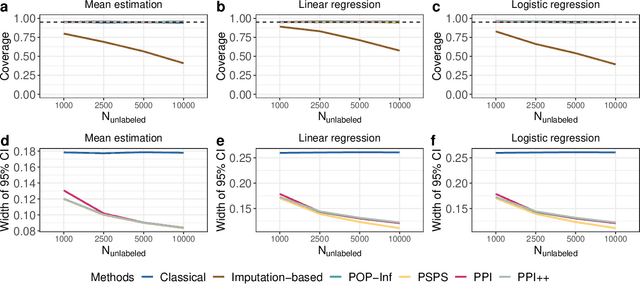
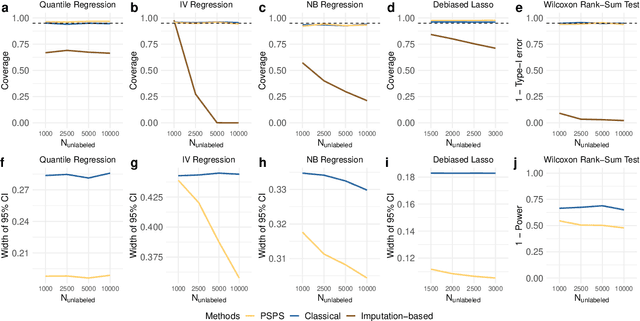
Machine learning (ML) is playing an increasingly important role in scientific research. In conjunction with classical statistical approaches, ML-assisted analytical strategies have shown great promise in accelerating research findings. This has also opened up a whole new field of methodological research focusing on integrative approaches that leverage both ML and statistics to tackle data science challenges. One type of study that has quickly gained popularity employs ML to predict unobserved outcomes in massive samples and then uses the predicted outcomes in downstream statistical inference. However, existing methods designed to ensure the validity of this type of post-prediction inference are limited to very basic tasks such as linear regression analysis. This is because any extension of these approaches to new, more sophisticated statistical tasks requires task-specific algebraic derivations and software implementations, which ignores the massive library of existing software tools already developed for complex inference tasks and severely constrains the scope of post-prediction inference in real applications. To address this challenge, we propose a novel statistical framework for task-agnostic ML-assisted inference. It provides a post-prediction inference solution that can be easily plugged into almost any established data analysis routine. It delivers valid and efficient inference that is robust to arbitrary choices of ML models, while allowing nearly all existing analytical frameworks to be incorporated into the analysis of ML-predicted outcomes. Through extensive experiments, we showcase the validity, versatility, and superiority of our method compared to existing approaches.
Assumption-lean and Data-adaptive Post-Prediction Inference
Nov 23, 2023

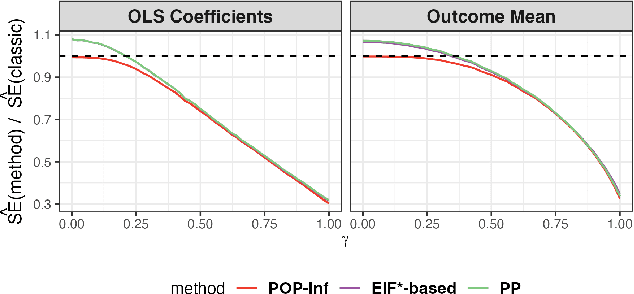

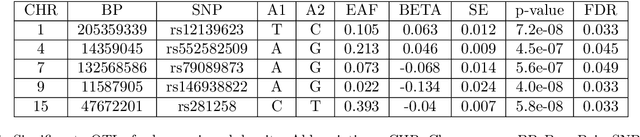
A primary challenge facing modern scientific research is the limited availability of gold-standard data which can be both costly and labor-intensive to obtain. With the rapid development of machine learning (ML), scientists have relied on ML algorithms to predict these gold-standard outcomes with easily obtained covariates. However, these predicted outcomes are often used directly in subsequent statistical analyses, ignoring imprecision and heterogeneity introduced by the prediction procedure. This will likely result in false positive findings and invalid scientific conclusions. In this work, we introduce an assumption-lean and data-adaptive Post-Prediction Inference (POP-Inf) procedure that allows valid and powerful inference based on ML-predicted outcomes. Its "assumption-lean" property guarantees reliable statistical inference without assumptions on the ML-prediction, for a wide range of statistical quantities. Its "data-adaptive'" feature guarantees an efficiency gain over existing post-prediction inference methods, regardless of the accuracy of ML-prediction. We demonstrate the superiority and applicability of our method through simulations and large-scale genomic data.