 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Variable Clustering for High-Dimensional Matrix Valued Data
Dec 24, 2021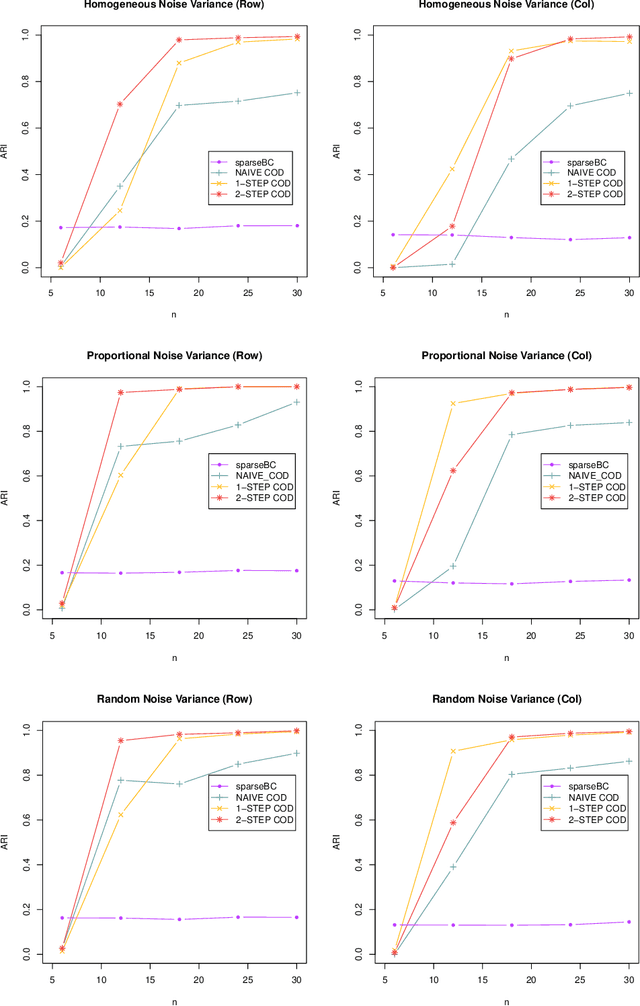
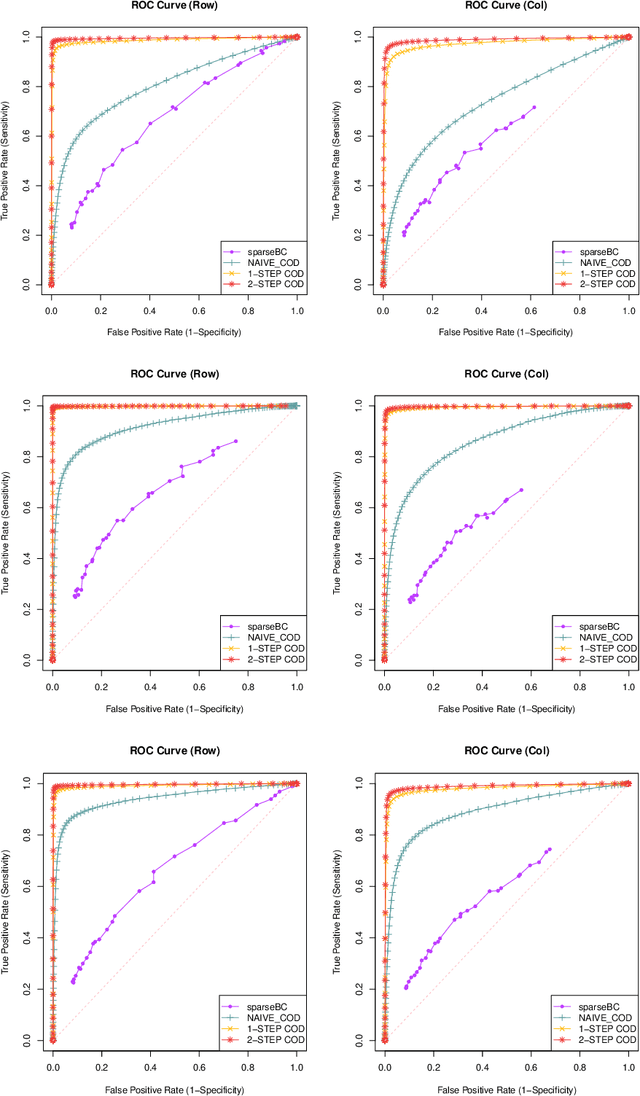
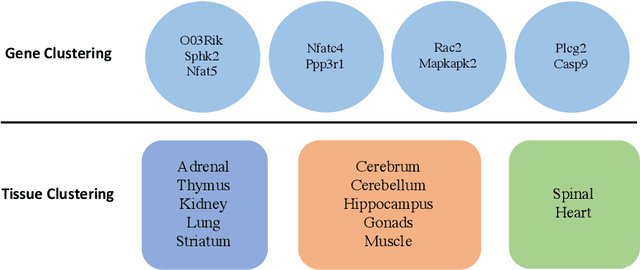
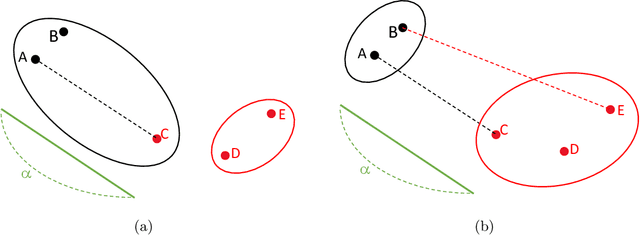
Matrix valued data has become increasingly prevalent in many applications. Most of the existing clustering methods for this type of data are tailored to the mean model and do not account for the dependence structure of the features, which can be very informative, especially in high-dimensional settings. To extract the information from the dependence structure for clustering, we propose a new latent variable model for the features arranged in matrix form, with some unknown membership matrices representing the clusters for the rows and columns. Under this model, we further propose a class of hierarchical clustering algorithms using the difference of a weighted covariance matrix as the dissimilarity measure. Theoretically, we show that under mild conditions, our algorithm attains clustering consistency in the high-dimensional setting. While this consistency result holds for our algorithm with a broad class of weighted covariance matrices, the conditions for this result depend on the choice of the weight. To investigate how the weight affects the theoretical performance of our algorithm, we establish the minimax lower bound for clustering under our latent variable model. Given these results, we identify the optimal weight in the sense that using this weight guarantees our algorithm to be minimax rate-optimal in terms of the magnitude of some cluster separation metric. The practical implementation of our algorithm with the optimal weight is also discussed. Finally, we conduct simulation studies to evaluate the finite sample performance of our algorithm and apply the method to a genomic dataset.
Optimal Semi-supervised Estimation and Inference for High-dimensional Linear Regression
Nov 28, 2020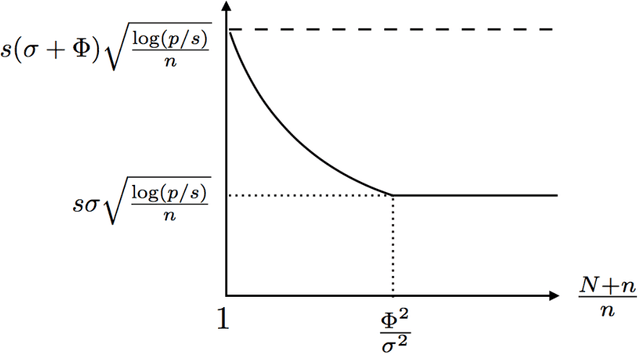
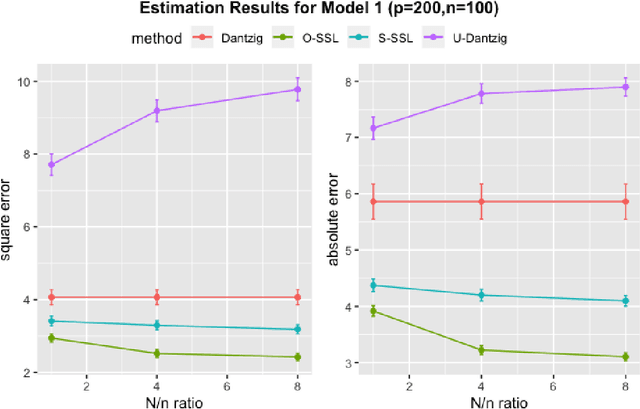
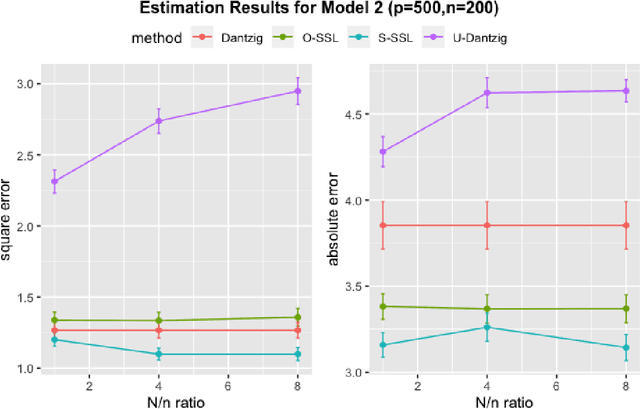

There are many scenarios such as the electronic health records where the outcome is much more difficult to collect than the covariates. In this paper, we consider the linear regression problem with such a data structure under the high dimensionality. Our goal is to investigate when and how the unlabeled data can be exploited to improve the estimation and inference of the regression parameters in linear models, especially in light of the fact that such linear models may be misspecified in data analysis. In particular, we address the following two important questions. (1) Can we use the labeled data as well as the unlabeled data to construct a semi-supervised estimator such that its convergence rate is faster than the supervised estimators? (2) Can we construct confidence intervals or hypothesis tests that are guaranteed to be more efficient or powerful than the supervised estimators? To address the first question, we establish the minimax lower bound for parameter estimation in the semi-supervised setting. We show that the upper bound from the supervised estimators that only use the labeled data cannot attain this lower bound. We close this gap by proposing a new semi-supervised estimator which attains the lower bound. To address the second question, based on our proposed semi-supervised estimator, we propose two additional estimators for semi-supervised inference, the efficient estimator and the safe estimator. The former is fully efficient if the unknown conditional mean function is estimated consistently, but may not be more efficient than the supervised approach otherwise. The latter usually does not aim to provide fully efficient inference, but is guaranteed to be no worse than the supervised approach, no matter whether the linear model is correctly specified or the conditional mean function is consistently estimated.