 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Eavesdroppers Reason: Agentic Eavesdropping Attacks on Semantic Communication
May 04, 2026Semantic communication (SemCom) has emerged as a promising paradigm for next-generation networks. However, its typical end-to-end joint source--channel coding (JSCC) architecture also raises serious privacy concerns. To guide future secure SemCom design, it is important to understand how serious such leakage can be. Nevertheless, existing eavesdropping attacks mainly rely on fixed-configuration solvers and often require instantaneous wiretap channel state information (CSI) to achieve effective privacy inference. This may lead future secure SemCom designs to overlook potentially severe risks. To address this, we propose a large language model (LLM)-orchestrated agentic eavesdropper. Specifically, the proposed eavesdropper forms a closed-loop workflow with three functional agents. The optimization agent adaptively performs joint semantic-and-channel inversion to recover private information from the intercepted signal without requiring wiretap CSI. The perception agent evaluates the effectiveness of the optimization agent and assesses whether the recovered private semantics are reasonable, providing feedback to the optimization agent. The refinement agent further analyzes the recovered content and uses a generative prior to refine promising candidates into more realistic and complete private reconstructions while preserving consistency with the intercepted signal. Simulation results over a MIMO Rayleigh fading channel show that the proposed eavesdropper achieves more than $75\%$ eavesdropping success rate at $\mathrm{SNR}\geq 5$~dB even without wiretap CSI, highlighting a severe privacy threat that future secure SemCom systems must address.
VoI-Driven Joint Optimization of Control and Communication in Vehicular Digital Twin Network
May 12, 2025The vision of sixth-generation (6G) wireless networks paves the way for the seamless integration of digital twins into vehicular networks, giving rise to a Vehicular Digital Twin Network (VDTN). The large amount of computing resources as well as the massive amount of spatial-temporal data in Digital Twin (DT) domain can be utilized to enhance the communication and control performance of Internet of Vehicle (IoV) systems. In this article, we first propose the architecture of VDTN, emphasizing key modules that center on functions related to the joint optimization of control and communication. We then delve into the intricacies of the multitimescale decision process inherent in joint optimization in VDTN, specifically investigating the dynamic interplay between control and communication. To facilitate the joint optimization, we define two Value of Information (VoI) concepts rooted in control performance. Subsequently, utilizing VoI as a bridge between control and communication, we introduce a novel joint optimization framework, which involves iterative processing of two Deep Reinforcement Learning (DRL) modules corresponding to control and communication to derive the optimal policy. Finally, we conduct simulations of the proposed framework applied to a platoon scenario to demonstrate its effectiveness in ensu
Learning Value of Information towards Joint Communication and Control in 6G V2X
May 11, 2025As Cellular Vehicle-to-Everything (C-V2X) evolves towards future sixth-generation (6G) networks, Connected Autonomous Vehicles (CAVs) are emerging to become a key application. Leveraging data-driven Machine Learning (ML), especially Deep Reinforcement Learning (DRL), is expected to significantly enhance CAV decision-making in both vehicle control and V2X communication under uncertainty. These two decision-making processes are closely intertwined, with the value of information (VoI) acting as a crucial bridge between them. In this paper, we introduce Sequential Stochastic Decision Process (SSDP) models to define and assess VoI, demonstrating their application in optimizing communication systems for CAVs. Specifically, we formally define the SSDP model and demonstrate that the MDP model is a special case of it. The SSDP model offers a key advantage by explicitly representing the set of information that can enhance decision-making when available. Furthermore, as current research on VoI remains fragmented, we propose a systematic VoI modeling framework grounded in the MDP, Reinforcement Learning (RL) and Optimal Control theories. We define different categories of VoI and discuss their corresponding estimation methods. Finally, we present a structured approach to leverage the various VoI metrics for optimizing the ``When", ``What", and ``How" to communicate problems. For this purpose, SSDP models are formulated with VoI-associated reward functions derived from VoI-based optimization objectives. While we use a simple vehicle-following control problem to illustrate the proposed methodology, it holds significant potential to facilitate the joint optimization of stochastic, sequential control and communication decisions in a wide range of networked control systems.
Can Knowledge Improve Security? A Coding-Enhanced Jamming Approach for Semantic Communication
May 06, 2025As semantic communication (SemCom) attracts growing attention as a novel communication paradigm, ensuring the security of transmitted semantic information over open wireless channels has become a critical issue. However, traditional encryption methods often introduce significant additional communication overhead to maintain stability, and conventional learning-based secure SemCom methods typically rely on a channel capacity advantage for the legitimate receiver, which is challenging to guarantee in real-world scenarios. In this paper, we propose a coding-enhanced jamming method that eliminates the need to transmit a secret key by utilizing shared knowledge-potentially part of the training set of the SemCom system-between the legitimate receiver and the transmitter. Specifically, we leverage the shared private knowledge base to generate a set of private digital codebooks in advance using neural network (NN)-based encoders. For each transmission, we encode the transmitted data into digital sequence Y1 and associate Y1 with a sequence randomly picked from the private codebook, denoted as Y2, through superposition coding. Here, Y1 serves as the outer code and Y2 as the inner code. By optimizing the power allocation between the inner and outer codes, the legitimate receiver can reconstruct the transmitted data using successive decoding with the index of Y2 shared, while the eavesdropper' s decoding performance is severely degraded, potentially to the point of random guessing. Experimental results demonstrate that our method achieves comparable security to state-of-the-art approaches while significantly improving the reconstruction performance of the legitimate receiver by more than 1 dB across varying channel signal-to-noise ratios (SNRs) and compression ratios.
Enhancing the Security of Semantic Communication via Knowledge-Aided Coding and Jamming
May 01, 2025As semantic communication (SemCom) emerges as a promising communication paradigm, ensuring the security of semantic information over open wireless channels has become crucial. Traditional encryption methods introduce considerable communication overhead, while existing learning-based secure SemCom schemes often rely on a channel capacity advantage for the legitimate receiver, which is challenging to guarantee in practice. In this paper, we propose a coding-enhanced jamming approach that eliminates the need to transmit a secret key by utilizing shared knowledge between the legitimate receiver and the transmitter. We generate private codebooks with neural network (NN)-based encoders, using them to encode data into a sequence Y1, which is then superposed with a sequence Y2 drawn from the private codebook. By optimizing the power allocation between the two sequences, the legitimate receiver can successfully decode the data, while the eavesdropper' s performance is significantly degraded, potentially to the point of random guessing. Experimental results demonstrate that our method achieves comparable security to state-of-the-art approaches while significantly improving the reconstruction performance of the legitimate receiver by more than 1 dB across varying channel signal-to-noise ratios (SNRs) and compression ratios.
A Coding-Enhanced Jamming Approach for Secure Semantic Communication over Wiretap Channels
Apr 23, 2025As semantic communication (SemCom) gains increasing attention as a novel communication paradigm, ensuring the security of transmitted semantic information over open wireless channels becomes crucial. Existing secure SemCom solutions often lack explicit control over security. To address this, we propose a coding-enhanced jamming approach for secure SemCom over wiretap channels. This approach integrates deep joint source and channel coding (DeepJSCC) with neural network-based digital modulation, enabling controlled jamming through two-layer superposition coding. The outer constellation sequence encodes the source image, while the inner constellation sequence, derived from a secret image, acts as the jamming signal. By minimizing the mutual information between the outer and inner constellation sequences, the jamming effect is enhanced. The jamming signal is superposed on the outer constellation sequence, preventing the eavesdropper from recovering the source image. The power allocation coefficient (PAC) in the superposition coding can be adjusted to control system security. Experiments show that our approach matches existing methods in security while significantly improving reconstruction performance across varying channel signal-to-noise ratios (SNRs) and compression ratios.
Towards Intelligent Transportation with Pedestrians and Vehicles In-the-Loop: A Surveillance Video-Assisted Federated Digital Twin Framework
Mar 06, 2025In intelligent transportation systems (ITSs), incorporating pedestrians and vehicles in-the-loop is crucial for developing realistic and safe traffic management solutions. However, there is falls short of simulating complex real-world ITS scenarios, primarily due to the lack of a digital twin implementation framework for characterizing interactions between pedestrians and vehicles at different locations in different traffic environments. In this article, we propose a surveillance video assisted federated digital twin (SV-FDT) framework to empower ITSs with pedestrians and vehicles in-the-loop. Specifically, SVFDT builds comprehensive pedestrian-vehicle interaction models by leveraging multi-source traffic surveillance videos. Its architecture consists of three layers: (i) the end layer, which collects traffic surveillance videos from multiple sources; (ii) the edge layer, responsible for semantic segmentation-based visual understanding, twin agent-based interaction modeling, and local digital twin system (LDTS) creation in local regions; and (iii) the cloud layer, which integrates LDTSs across different regions to construct a global DT model in realtime. We analyze key design requirements and challenges and present core guidelines for SVFDT's system implementation. A testbed evaluation demonstrates its effectiveness in optimizing traffic management. Comparisons with traditional terminal-server frameworks highlight SV-FDT's advantages in mirroring delays, recognition accuracy, and subjective evaluation. Finally, we identify some open challenges and discuss future research directions.
Edge-Assisted Accelerated Cooperative Sensing for CAVs: Task Placement and Resource Allocation
Nov 27, 2024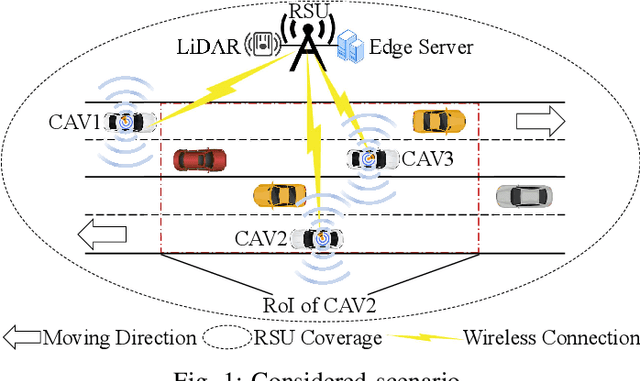
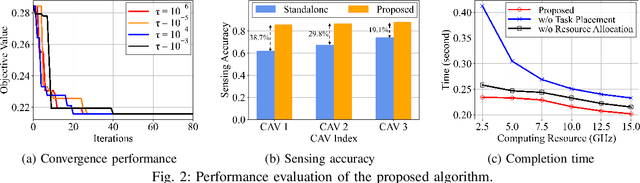
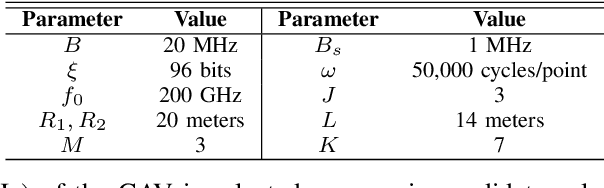
In this paper, we propose a novel road side unit (RSU)-assisted cooperative sensing scheme for connected autonomous vehicles (CAVs), with the objective to reduce completion time of sensing tasks. Specifically, LiDAR sensing data of both RSU and CAVs are selectively fused to improve sensing accuracy, and computing resources therein are cooperatively utilized to process tasks in real time. To this end, for each task, we decide whether to compute it at the CAV or at the RSU and allocate resources accordingly. We first formulate a joint task placement and resource allocation problem for minimizing the total task completion time while satisfying sensing accuracy constraint. We then decouple the problem into two subproblems and propose a two-layer algorithm to solve them. The outer layer first makes task placement decision based on the Gibbs sampling theory, while the inner layer makes spectrum and computing resource allocation decisions via greedy-based and convex optimization subroutines, respectively. Simulation results based on the autonomous driving simulator CARLA demonstrate the effectiveness of the proposed scheme in reducing total task completion time, comparing to benchmark schemes.
Spatial-Temporal Attention Model for Traffic State Estimation with Sparse Internet of Vehicles
Jul 10, 2024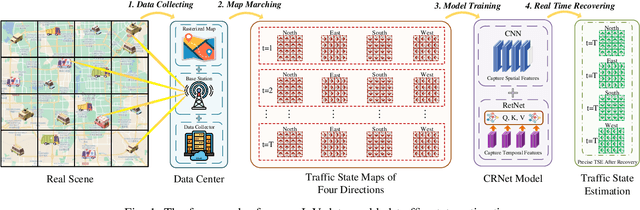
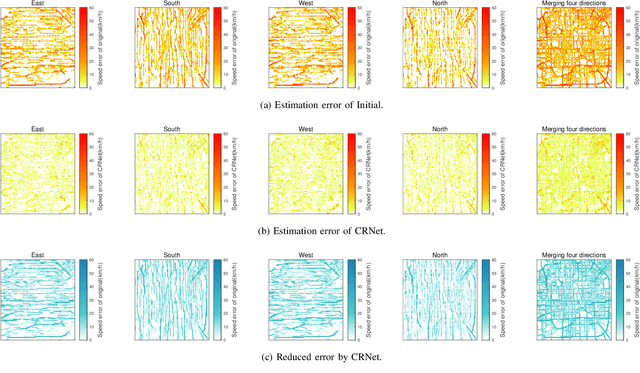
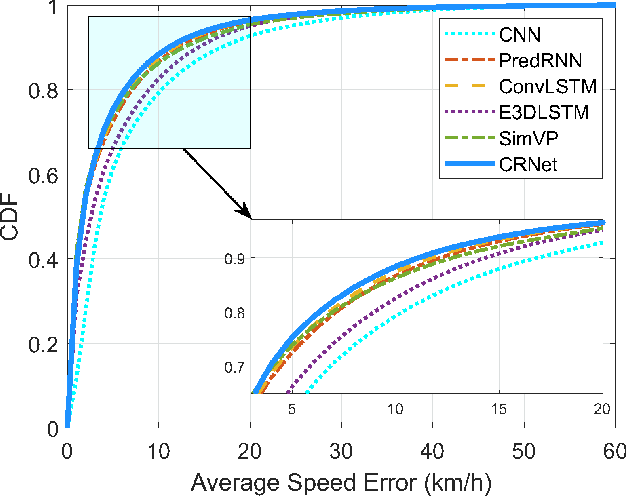

The growing number of connected vehicles offers an opportunity to leverage internet of vehicles (IoV) data for traffic state estimation (TSE) which plays a crucial role in intelligent transportation systems (ITS). By utilizing only a portion of IoV data instead of the entire dataset, the significant overheads associated with collecting and processing large amounts of data can be avoided. In this paper, we introduce a novel framework that utilizes sparse IoV data to achieve cost-effective TSE. Particularly, we propose a novel spatial-temporal attention model called the convolutional retentive network (CRNet) to improve the TSE accuracy by mining spatial-temporal traffic state correlations. The model employs the convolutional neural network (CNN) for spatial correlation aggregation and the retentive network (RetNet) based on the attention mechanism to extract temporal correlations. Extensive simulations on a real-world IoV dataset validate the advantage of the proposed TSE approach in achieving accurate TSE using sparse IoV data, demonstrating its cost effectiveness and practicality for real-world applications.
Integration of Mixture of Experts and Multimodal Generative AI in Internet of Vehicles: A Survey
Apr 25, 2024
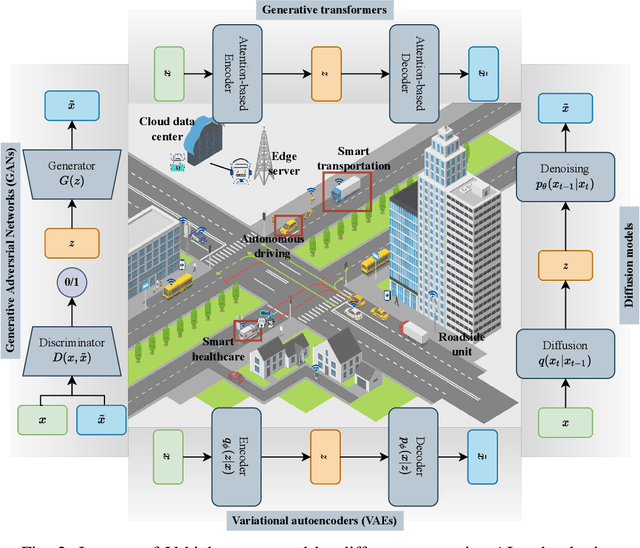
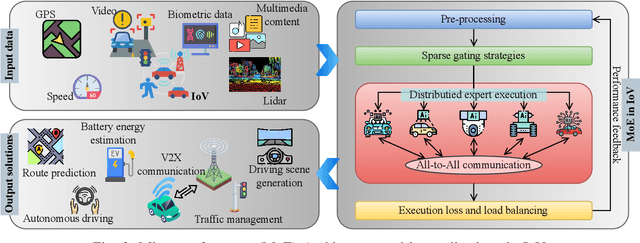
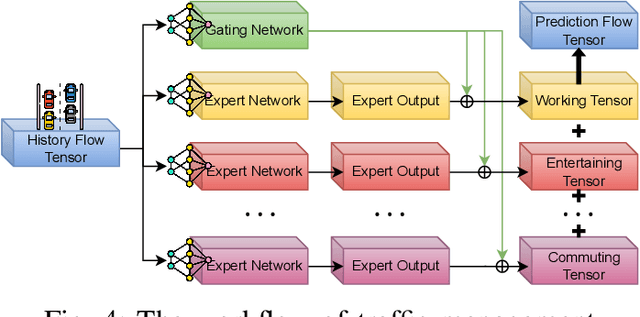
Generative AI (GAI) can enhance the cognitive, reasoning, and planning capabilities of intelligent modules in the Internet of Vehicles (IoV) by synthesizing augmented datasets, completing sensor data, and making sequential decisions. In addition, the mixture of experts (MoE) can enable the distributed and collaborative execution of AI models without performance degradation between connected vehicles. In this survey, we explore the integration of MoE and GAI to enable Artificial General Intelligence in IoV, which can enable the realization of full autonomy for IoV with minimal human supervision and applicability in a wide range of mobility scenarios, including environment monitoring, traffic management, and autonomous driving. In particular, we present the fundamentals of GAI, MoE, and their interplay applications in IoV. Furthermore, we discuss the potential integration of MoE and GAI in IoV, including distributed perception and monitoring, collaborative decision-making and planning, and generative modeling and simulation. Finally, we present several potential research directions for facilitating the integration.