 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Optimize Joint Source and RIS-assisted Channel Encoding for Multi-User Semantic Communication Systems
Mar 22, 2026In this paper, we explore a joint source and reconfigurable intelligent surface (RIS)-assisted channel encoding (JSRE) framework for multi-user semantic communications, where a deep neural network (DNN) extracts semantic features for all users and the RIS provides channel orthogonality, enabling a unified semantic encoding-decoding design. We aim to maximize the overall energy efficiency of semantic communications across all users by jointly optimizing the user scheduling, the RIS's phase shifts, and the semantic compression ratio. Although this joint optimization problem can be addressed using conventional deep reinforcement learning (DRL) methods, evaluating semantic similarity typically relies on extensive real environment interactions, which can incur heavy computational overhead during training. To address this challenge, we propose a truncated DRL (T-DRL) framework, where a DNN-based semantic similarity estimator is developed to rapidly estimate the similarity score. Moreover, the user scheduling strategy is tightly coupled with the semantic model configuration. To exploit this relationship, we further propose a semantic model caching mechanism that stores and reuses fine-tuned semantic models corresponding to different scheduling decisions. A Transformer-based actor network is employed within the DRL framework to dynamically generate action space conditioned on the current caching state. This avoids redundant retraining and further accelerates the convergence of the learning process. Numerical results demonstrate that the proposed JSRE framework significantly improves the system energy efficiency compared with the baseline methods. By training fewer semantic models, the proposed T-DRL framework significantly enhances the learning efficiency.
WebNovelBench: Placing LLM Novelists on the Web Novel Distribution
May 20, 2025Robustly evaluating the long-form storytelling capabilities of Large Language Models (LLMs) remains a significant challenge, as existing benchmarks often lack the necessary scale, diversity, or objective measures. To address this, we introduce WebNovelBench, a novel benchmark specifically designed for evaluating long-form novel generation. WebNovelBench leverages a large-scale dataset of over 4,000 Chinese web novels, framing evaluation as a synopsis-to-story generation task. We propose a multi-faceted framework encompassing eight narrative quality dimensions, assessed automatically via an LLM-as-Judge approach. Scores are aggregated using Principal Component Analysis and mapped to a percentile rank against human-authored works. Our experiments demonstrate that WebNovelBench effectively differentiates between human-written masterpieces, popular web novels, and LLM-generated content. We provide a comprehensive analysis of 24 state-of-the-art LLMs, ranking their storytelling abilities and offering insights for future development. This benchmark provides a scalable, replicable, and data-driven methodology for assessing and advancing LLM-driven narrative generation.
FlightGPT: Towards Generalizable and Interpretable UAV Vision-and-Language Navigation with Vision-Language Models
May 19, 2025Unmanned Aerial Vehicle (UAV) Vision-and-Language Navigation (VLN) is vital for applications such as disaster response, logistics delivery, and urban inspection. However, existing methods often struggle with insufficient multimodal fusion, weak generalization, and poor interpretability. To address these challenges, we propose FlightGPT, a novel UAV VLN framework built upon Vision-Language Models (VLMs) with powerful multimodal perception capabilities. We design a two-stage training pipeline: first, Supervised Fine-Tuning (SFT) using high-quality demonstrations to improve initialization and structured reasoning; then, Group Relative Policy Optimization (GRPO) algorithm, guided by a composite reward that considers goal accuracy, reasoning quality, and format compliance, to enhance generalization and adaptability. Furthermore, FlightGPT introduces a Chain-of-Thought (CoT)-based reasoning mechanism to improve decision interpretability. Extensive experiments on the city-scale dataset CityNav demonstrate that FlightGPT achieves state-of-the-art performance across all scenarios, with a 9.22\% higher success rate than the strongest baseline in unseen environments. Our implementation is publicly available.
Learning Joint Source-Channel Encoding in IRS-assisted Multi-User Semantic Communications
Apr 10, 2025In this paper, we investigate a joint source-channel encoding (JSCE) scheme in an intelligent reflecting surface (IRS)-assisted multi-user semantic communication system. Semantic encoding not only compresses redundant information, but also enhances information orthogonality in a semantic feature space. Meanwhile, the IRS can adjust the spatial orthogonality, enabling concurrent multi-user semantic communication in densely deployed wireless networks to improve spectrum efficiency. We aim to maximize the users' semantic throughput by jointly optimizing the users' scheduling, the IRS's passive beamforming, and the semantic encoding strategies. To tackle this non-convex problem, we propose an explainable deep neural network-driven deep reinforcement learning (XD-DRL) framework. Specifically, we employ a deep neural network (DNN) to serve as a joint source-channel semantic encoder, enabling transmitters to extract semantic features from raw images. By leveraging structural similarity, we assign some DNN weight coefficients as the IRS's phase shifts, allowing simultaneous optimization of IRS's passive beamforming and DNN training. Given the IRS's passive beamforming and semantic encoding strategies, user scheduling is optimized using the DRL method. Numerical results validate that our JSCE scheme achieves superior semantic throughput compared to the conventional schemes and efficiently reduces the semantic encoder's mode size in multi-user scenarios.
Towards Intelligent Transportation with Pedestrians and Vehicles In-the-Loop: A Surveillance Video-Assisted Federated Digital Twin Framework
Mar 06, 2025In intelligent transportation systems (ITSs), incorporating pedestrians and vehicles in-the-loop is crucial for developing realistic and safe traffic management solutions. However, there is falls short of simulating complex real-world ITS scenarios, primarily due to the lack of a digital twin implementation framework for characterizing interactions between pedestrians and vehicles at different locations in different traffic environments. In this article, we propose a surveillance video assisted federated digital twin (SV-FDT) framework to empower ITSs with pedestrians and vehicles in-the-loop. Specifically, SVFDT builds comprehensive pedestrian-vehicle interaction models by leveraging multi-source traffic surveillance videos. Its architecture consists of three layers: (i) the end layer, which collects traffic surveillance videos from multiple sources; (ii) the edge layer, responsible for semantic segmentation-based visual understanding, twin agent-based interaction modeling, and local digital twin system (LDTS) creation in local regions; and (iii) the cloud layer, which integrates LDTSs across different regions to construct a global DT model in realtime. We analyze key design requirements and challenges and present core guidelines for SVFDT's system implementation. A testbed evaluation demonstrates its effectiveness in optimizing traffic management. Comparisons with traditional terminal-server frameworks highlight SV-FDT's advantages in mirroring delays, recognition accuracy, and subjective evaluation. Finally, we identify some open challenges and discuss future research directions.
A Brain-Inspired Perception-Decision Driving Model Based on Neural Pathway Anatomical Alignment
Feb 22, 2025



In the realm of autonomous driving, conventional approaches for vehicle perception and decision-making primarily rely on sensor input and rule-based algorithms. However, these methodologies often suffer from lack of interpretability and robustness, particularly in intricate traffic scenarios. To tackle this challenge, we propose a novel brain-inspired driving (BID) framework. Diverging from traditional methods, our approach harnesses brain-inspired perception technology to achieve more efficient and robust environmental perception. Additionally, it employs brain-inspired decision-making techniques to facilitate intelligent decision-making. The experimental results show that the performance has been significantly improved across various autonomous driving tasks and achieved the end-to-end autopilot successfully. This contribution not only advances interpretability and robustness but also offers fancy insights and methodologies for further advancing autonomous driving technology.
BAN: Neuroanatomical Aligning in Auditory Recognition between Artificial Neural Network and Human Cortex
Feb 21, 2025

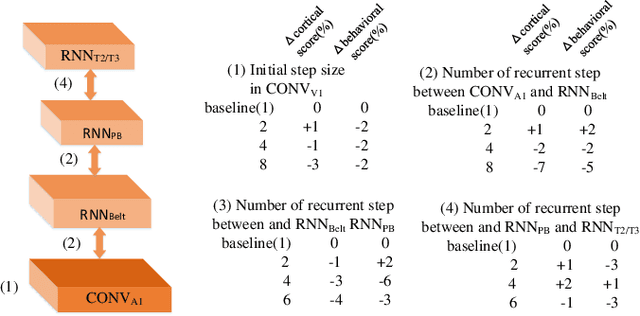

Drawing inspiration from neurosciences, artificial neural networks (ANNs) have evolved from shallow architectures to highly complex, deep structures, yielding exceptional performance in auditory recognition tasks. However, traditional ANNs often struggle to align with brain regions due to their excessive depth and lack of biologically realistic features, like recurrent connection. To address this, a brain-like auditory network (BAN) is introduced, which incorporates four neuroanatomically mapped areas and recurrent connection, guided by a novel metric called the brain-like auditory score (BAS). BAS serves as a benchmark for evaluating the similarity between BAN and human auditory recognition pathway. We further propose that specific areas in the cerebral cortex, mainly the middle and medial superior temporal (T2/T3) areas, correspond to the designed network structure, drawing parallels with the brain's auditory perception pathway. Our findings suggest that the neuroanatomical similarity in the cortex and auditory classification abilities of the ANN are well-aligned. In addition to delivering excellent performance on a music genre classification task, the BAN demonstrates a high BAS score. In conclusion, this study presents BAN as a recurrent, brain-inspired ANN, representing the first model that mirrors the cortical pathway of auditory recognition.
STURE: Spatial-Temporal Mutual Representation Learning for Robust Data Association in Online Multi-Object Tracking
Jan 19, 2022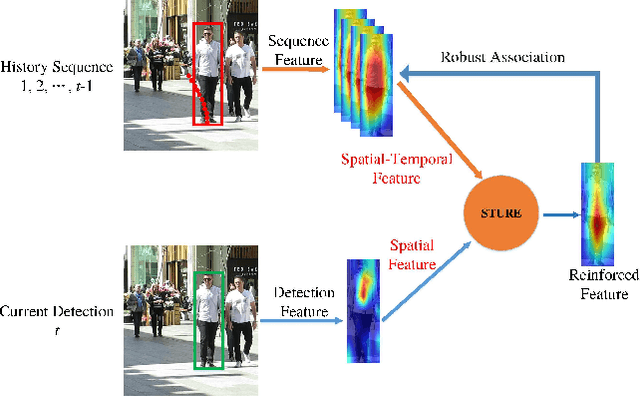
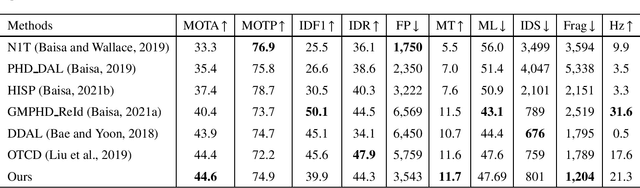
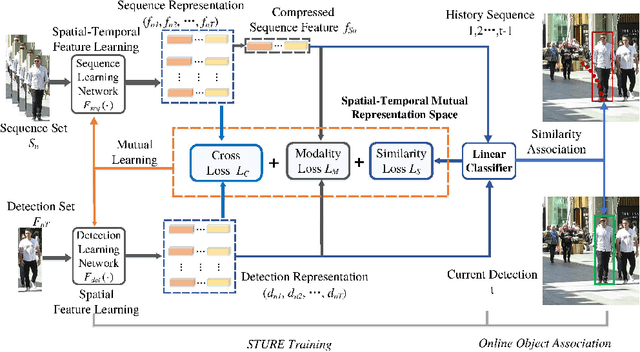
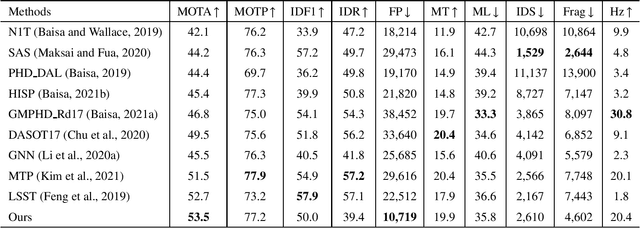
Online multi-object tracking (MOT) is a longstanding task for computer vision and intelligent vehicle platform. At present, the main paradigm is tracking-by-detection, and the main difficulty of this paradigm is how to associate the current candidate detection with the historical tracklets. However, in the MOT scenarios, each historical tracklet is composed of an object sequence, while each candidate detection is just a flat image, which lacks the temporal features of the object sequence. The feature difference between current candidate detection and historical tracklets makes the object association much harder. Therefore, we propose a Spatial-Temporal Mutual {Representation} Learning (STURE) approach which learns spatial-temporal representations between current candidate detection and historical sequence in a mutual representation space. For the historical trackelets, the detection learning network is forced to match the representations of sequence learning network in a mutual representation space. The proposed approach is capable of extracting more distinguishing detection and sequence representations by using various designed losses in object association. As a result, spatial-temporal feature is learned mutually to reinforce the current detection features, and the feature difference can be relieved. To prove the robustness of the STURE, it is applied to the public MOT challenge benchmarks and performs well compared with various state-of-the-art online MOT trackers based on identity-preserving metrics.
SPANN: Highly-efficient Billion-scale Approximate Nearest Neighbor Search
Nov 05, 2021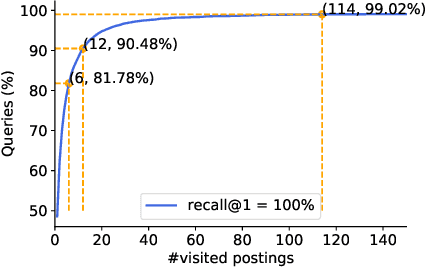

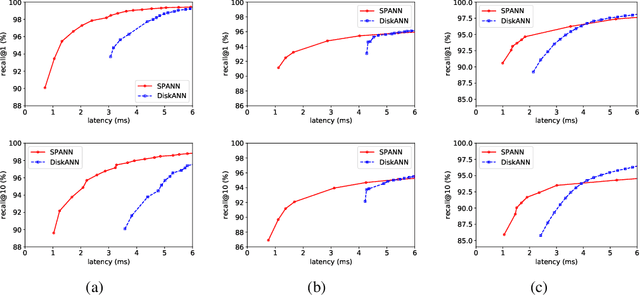

The in-memory algorithms for approximate nearest neighbor search (ANNS) have achieved great success for fast high-recall search, but are extremely expensive when handling very large scale database. Thus, there is an increasing request for the hybrid ANNS solutions with small memory and inexpensive solid-state drive (SSD). In this paper, we present a simple but efficient memory-disk hybrid indexing and search system, named SPANN, that follows the inverted index methodology. It stores the centroid points of the posting lists in the memory and the large posting lists in the disk. We guarantee both disk-access efficiency (low latency) and high recall by effectively reducing the disk-access number and retrieving high-quality posting lists. In the index-building stage, we adopt a hierarchical balanced clustering algorithm to balance the length of posting lists and augment the posting list by adding the points in the closure of the corresponding clusters. In the search stage, we use a query-aware scheme to dynamically prune the access of unnecessary posting lists. Experiment results demonstrate that SPANN is 2$\times$ faster than the state-of-the-art ANNS solution DiskANN to reach the same recall quality $90\%$ with same memory cost in three billion-scale datasets. It can reach $90\%$ recall@1 and recall@10 in just around one millisecond with only 32GB memory cost. Code is available at: {\footnotesize\color{blue}{\url{https://github.com/microsoft/SPTAG}}}.
MIRA: Leveraging Multi-Intention Co-click Information in Web-scale Document Retrieval using Deep Neural Networks
Jul 03, 2020
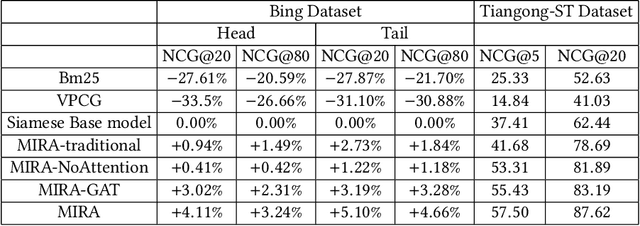
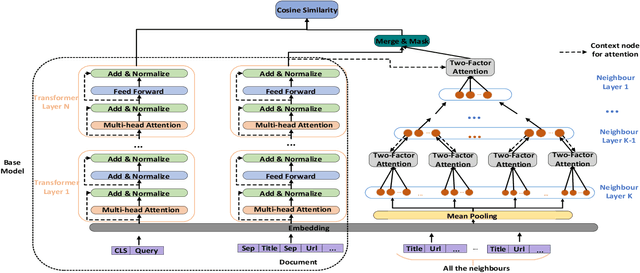
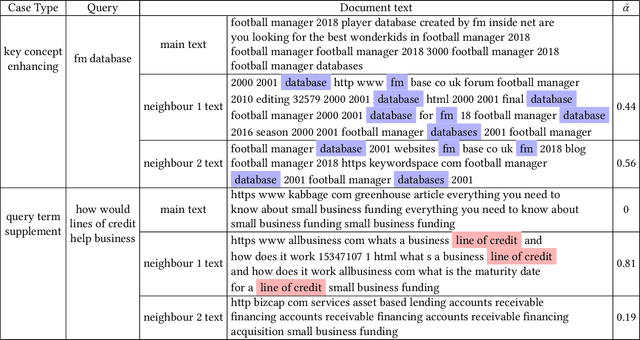
We study the problem of deep recall model in industrial web search, which is, given a user query, retrieve hundreds of most relevance documents from billions of candidates. The common framework is to train two encoding models based on neural embedding which learn the distributed representations of queries and documents separately and match them in the latent semantic space. However, all the exiting encoding models only leverage the information of the document itself, which is often not sufficient in practice when matching with query terms, especially for the hard tail queries. In this work we aim to leverage the additional information for each document from its co-click neighbour to help document retrieval. The challenges include how to effectively extract information and eliminate noise when involving co-click information in deep model while meet the demands of billion-scale data size for real time online inference. To handle the noise in co-click relations, we firstly propose a web-scale Multi-Intention Co-click document Graph(MICG) which builds the co-click connections between documents on click intention level but not on document level. Then we present an encoding framework MIRA based on Bert and graph attention networks which leverages a two-factor attention mechanism to aggregate neighbours. To meet the online latency requirements, we only involve neighbour information in document side, which can save the time-consuming query neighbor search in real time serving. We conduct extensive offline experiments on both public dataset and private web-scale dataset from two major commercial search engines demonstrating the effectiveness and scalability of the proposed method compared with several baselines. And a further case study reveals that co-click relations mainly help improve web search quality from two aspects: key concept enhancing and query term complementary.