 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRA: Leveraging Multi-Intention Co-click Information in Web-scale Document Retrieval using Deep Neural Networks
Jul 03, 2020
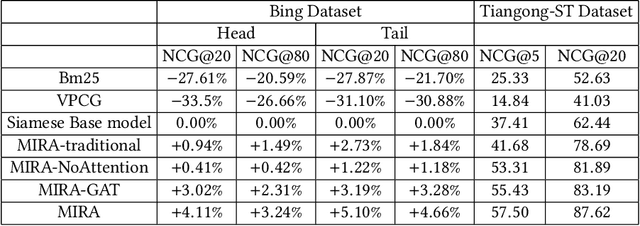
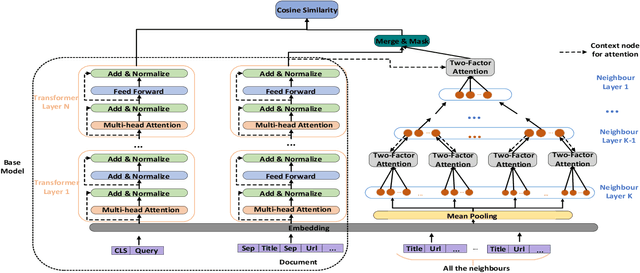
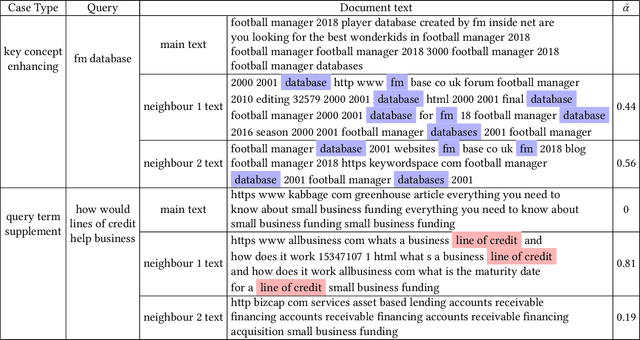
We study the problem of deep recall model in industrial web search, which is, given a user query, retrieve hundreds of most relevance documents from billions of candidates. The common framework is to train two encoding models based on neural embedding which learn the distributed representations of queries and documents separately and match them in the latent semantic space. However, all the exiting encoding models only leverage the information of the document itself, which is often not sufficient in practice when matching with query terms, especially for the hard tail queries. In this work we aim to leverage the additional information for each document from its co-click neighbour to help document retrieval. The challenges include how to effectively extract information and eliminate noise when involving co-click information in deep model while meet the demands of billion-scale data size for real time online inference. To handle the noise in co-click relations, we firstly propose a web-scale Multi-Intention Co-click document Graph(MICG) which builds the co-click connections between documents on click intention level but not on document level. Then we present an encoding framework MIRA based on Bert and graph attention networks which leverages a two-factor attention mechanism to aggregate neighbours. To meet the online latency requirements, we only involve neighbour information in document side, which can save the time-consuming query neighbor search in real time serving. We conduct extensive offline experiments on both public dataset and private web-scale dataset from two major commercial search engines demonstrating the effectiveness and scalability of the proposed method compared with several baselines. And a further case study reveals that co-click relations mainly help improve web search quality from two aspects: key concept enhancing and query term complementary.