 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCI4A: Semantic Component Interfaces for Agents Empowering Web Automation
Jan 21, 2026While Large Language Models demonstrate remarkable proficiency in high-level semantic planning, they remain limited in handling fine-grained, low-level web component manipulations. To address this limitation, extensive research has focused on enhancing model grounding capabilities through techniques such as Reinforcement Learning. However, rather than compelling agents to adapt to human-centric interfaces, we propose constructing interaction interfaces specifically optimized for agents. This paper introduces Component Interface for Agent (CI4A), a semantic encapsulation mechanism that abstracts the complex interaction logic of UI components into a set of unified tool primitives accessible to agents. We implemented CI4A within Ant Design, an industrial-grade front-end framework, covering 23 categories of commonly used UI components. Furthermore, we developed a hybrid agent featuring an action space that dynamically updates according to the page state, enabling flexible invocation of available CI4A tools. Leveraging the CI4A-integrated Ant Design, we refactored and upgraded the WebArena benchmark to evaluate existing SoTA methods. Experimental results demonstrate that the CI4A-based agent significantly outperforms existing approaches, achieving a new SoTA task success rate of 86.3%, alongside substantial improvements in execution efficiency.
GRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping
Oct 25, 2025Recently, GRPO-based reinforcement learning has shown remarkable progress in optimizing flow-matching models, effectively improving their alignment with task-specific rewards. Within these frameworks, the policy update relies on importance-ratio clipping to constrain overconfident positive and negative gradients. However, in practice, we observe a systematic shift in the importance-ratio distribution-its mean falls below 1 and its variance differs substantially across timesteps. This left-shifted and inconsistent distribution prevents positive-advantage samples from entering the clipped region, causing the mechanism to fail in constraining overconfident positive updates. As a result, the policy model inevitably enters an implicit over-optimization stage-while the proxy reward continues to increase, essential metrics such as image quality and text-prompt alignment deteriorate sharply, ultimately making the learned policy impractical for real-world use. To address this issue, we introduce GRPO-Guard, a simple yet effective enhancement to existing GRPO frameworks. Our method incorporates ratio normalization, which restores a balanced and step-consistent importance ratio, ensuring that PPO clipping properly constrains harmful updates across denoising timesteps. In addition, a gradient reweighting strategy equalizes policy gradients over noise conditions, preventing excessive updates from particular timestep regions. Together, these designs act as a regulated clipping mechanism, stabilizing optimization and substantially mitigating implicit over-optimization without relying on heavy KL regularization. Extensive experiments on multiple diffusion backbones (e.g., SD3.5M, Flux.1-dev) and diverse proxy tasks demonstrate that GRPO-Guard significantly reduces over-optimization while maintaining or even improving generation quality.
WebNovelBench: Placing LLM Novelists on the Web Novel Distribution
May 20, 2025Robustly evaluating the long-form storytelling capabilities of Large Language Models (LLMs) remains a significant challenge, as existing benchmarks often lack the necessary scale, diversity, or objective measures. To address this, we introduce WebNovelBench, a novel benchmark specifically designed for evaluating long-form novel generation. WebNovelBench leverages a large-scale dataset of over 4,000 Chinese web novels, framing evaluation as a synopsis-to-story generation task. We propose a multi-faceted framework encompassing eight narrative quality dimensions, assessed automatically via an LLM-as-Judge approach. Scores are aggregated using Principal Component Analysis and mapped to a percentile rank against human-authored works. Our experiments demonstrate that WebNovelBench effectively differentiates between human-written masterpieces, popular web novels, and LLM-generated content. We provide a comprehensive analysis of 24 state-of-the-art LLMs, ranking their storytelling abilities and offering insights for future development. This benchmark provides a scalable, replicable, and data-driven methodology for assessing and advancing LLM-driven narrative generation.
WISA: World Simulator Assistant for Physics-Aware Text-to-Video Generation
Mar 11, 2025Recent rapid advancements in text-to-video (T2V) generation, such as SoRA and Kling, have shown great potential for building world simulators. However, current T2V models struggle to grasp abstract physical principles and generate videos that adhere to physical laws. This challenge arises primarily from a lack of clear guidance on physical information due to a significant gap between abstract physical principles and generation models. To this end, we introduce the World Simulator Assistant (WISA), an effective framework for decomposing and incorporating physical principles into T2V models. Specifically, WISA decomposes physical principles into textual physical descriptions, qualitative physical categories, and quantitative physical properties. To effectively embed these physical attributes into the generation process, WISA incorporates several key designs, including Mixture-of-Physical-Experts Attention (MoPA) and a Physical Classifier, enhancing the model's physics awareness. Furthermore, most existing datasets feature videos where physical phenomena are either weakly represented or entangled with multiple co-occurring processes, limiting their suitability as dedicated resources for learning explicit physical principles. We propose a novel video dataset, WISA-32K, collected based on qualitative physical categories. It consists of 32,000 videos, representing 17 physical laws across three domains of physics: dynamics, thermodynamics, and optics. Experimental results demonstrate that WISA can effectively enhance the compatibility of T2V models with real-world physical laws, achieving a considerable improvement on the VideoPhy benchmark. The visual exhibitions of WISA and WISA-32K are available in the https://360cvgroup.github.io/WISA/.
CatV2TON: Taming Diffusion Transformers for Vision-Based Virtual Try-On with Temporal Concatenation
Jan 20, 2025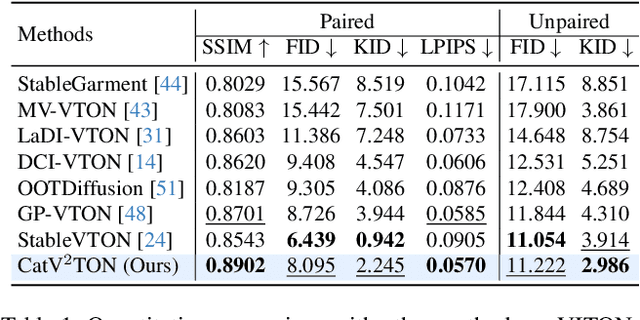
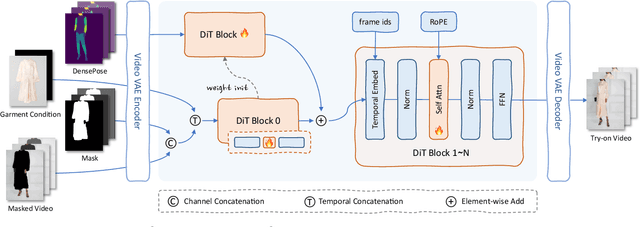
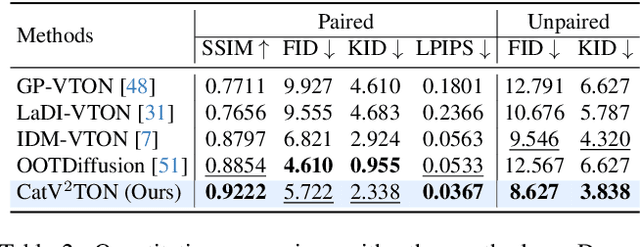
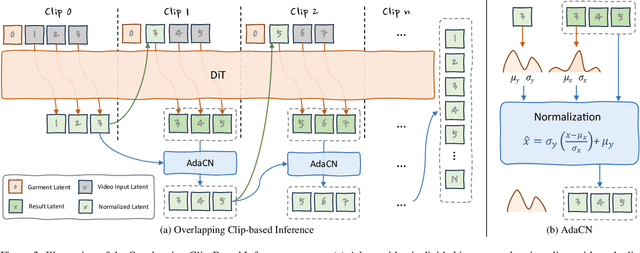
Virtual try-on (VTON) technology has gained attention due to its potential to transform online retail by enabling realistic clothing visualization of images and videos. However, most existing methods struggle to achieve high-quality results across image and video try-on tasks, especially in long video scenarios. In this work, we introduce CatV2TON, a simple and effective vision-based virtual try-on (V2TON) method that supports both image and video try-on tasks with a single diffusion transformer model. By temporally concatenating garment and person inputs and training on a mix of image and video datasets, CatV2TON achieves robust try-on performance across static and dynamic settings. For efficient long-video generation, we propose an overlapping clip-based inference strategy that uses sequential frame guidance and Adaptive Clip Normalization (AdaCN) to maintain temporal consistency with reduced resource demands. We also present ViViD-S, a refined video try-on dataset, achieved by filtering back-facing frames and applying 3D mask smoothing for enhanced temporal consistency. Comprehensive experiments demonstrate that CatV2TON outperforms existing methods in both image and video try-on tasks, offering a versatile and reliable solution for realistic virtual try-ons across diverse scenarios.
Dynamic Try-On: Taming Video Virtual Try-on with Dynamic Attention Mechanism
Dec 13, 2024



Video try-on stands as a promising area for its tremendous real-world potential. Previous research on video try-on has primarily focused on transferring product clothing images to videos with simple human poses, while performing poorly with complex movements. To better preserve clothing details, those approaches are armed with an additional garment encoder, resulting in higher computational resource consumption. The primary challenges in this domain are twofold: (1) leveraging the garment encoder's capabilities in video try-on while lowering computational requirements; (2) ensuring temporal consistency in the synthesis of human body parts, especially during rapid movements. To tackle these issues, we propose a novel video try-on framework based on Diffusion Transformer(DiT), named Dynamic Try-On. To reduce computational overhead, we adopt a straightforward approach by utilizing the DiT backbone itself as the garment encoder and employing a dynamic feature fusion module to store and integrate garment features. To ensure temporal consistency of human body parts, we introduce a limb-aware dynamic attention module that enforces the DiT backbone to focus on the regions of human limbs during the denoising process. Extensive experiments demonstrate the superiority of Dynamic Try-On in generating stable and smooth try-on results, even for videos featuring complicated human postures.
VITON-DiT: Learning In-the-Wild Video Try-On from Human Dance Videos via Diffusion Transformers
May 28, 2024
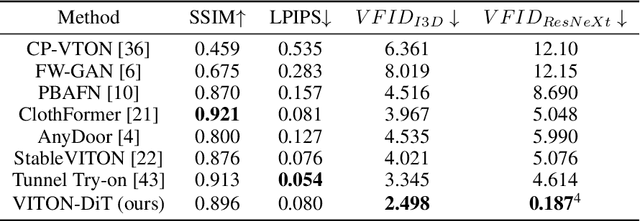
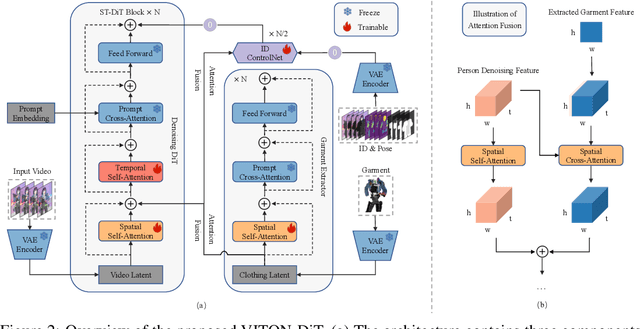
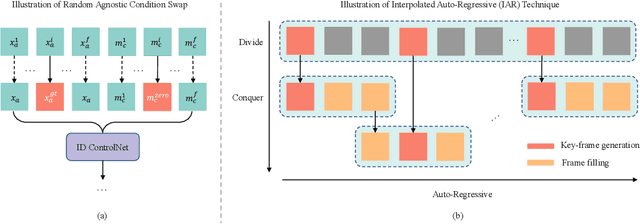
Video try-on stands as a promising area for its tremendous real-world potential. Prior works are limited to transferring product clothing images onto person videos with simple poses and backgrounds, while underperforming on casually captured videos. Recently, Sora revealed the scalability of Diffusion Transformer (DiT) in generating lifelike videos featuring real-world scenarios. Inspired by this, we explore and propose the first DiT-based video try-on framework for practical in-the-wild applications, named VITON-DiT. Specifically, VITON-DiT consists of a garment extractor, a Spatial-Temporal denoising DiT, and an identity preservation ControlNet. To faithfully recover the clothing details, the extracted garment features are fused with the self-attention outputs of the denoising DiT and the ControlNet. We also introduce novel random selection strategies during training and an Interpolated Auto-Regressive (IAR) technique at inference to facilitate long video generation. Unlike existing attempts that require the laborious and restrictive construction of a paired training dataset, severely limiting their scalability, VITON-DiT alleviates this by relying solely on unpaired human dance videos and a carefully designed multi-stage training strategy. Furthermore, we curate a challenging benchmark dataset to evaluate the performance of casual video try-on. Extensive experiments demonstrate the superiority of VITON-DiT in generating spatio-temporal consistent try-on results for in-the-wild videos with complicated human poses.
ABODE-Net: An Attention-based Deep Learning Model for Non-intrusive Building Occupancy Detection Using Smart Meter Data
Dec 21, 2022Occupancy information is useful for efficient energy management in the building sector. The massive high-resolution electrical power consumption data collected by smart meters in the advanced metering infrastructure (AMI) network make it possible to infer buildings' occupancy status in a non-intrusive way. In this paper, we propose a deep leaning model called ABODE-Net which employs a novel Parallel Attention (PA) block for building occupancy detection using smart meter data. The PA block combines the temporal, variable, and channel attention modules in a parallel way to signify important features for occupancy detection. We adopt two smart meter datasets widely used for building occupancy detection in our performance evaluation. A set of state-of-the-art shallow machine learning and deep learning models are included for performance comparison. The results show that ABODE-Net significantly outperforms other models in all experimental cases, which proves its validity as a solution for non-intrusive building occupancy detection.