 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamFit: Garment-Centric Human Generation via a Lightweight Anything-Dressing Encoder
Dec 23, 2024



Diffusion models for garment-centric human generation from text or image prompts have garnered emerging attention for their great application potential. However, existing methods often face a dilemma: lightweight approaches, such as adapters, are prone to generate inconsistent textures; while finetune-based methods involve high training costs and struggle to maintain the generalization capabilities of pretrained diffusion models, limiting their performance across diverse scenarios. To address these challenges, we propose DreamFit, which incorporates a lightweight Anything-Dressing Encoder specifically tailored for the garment-centric human generation. DreamFit has three key advantages: (1) \textbf{Lightweight training}: with the proposed adaptive attention and LoRA modules, DreamFit significantly minimizes the model complexity to 83.4M trainable parameters. (2)\textbf{Anything-Dressing}: Our model generalizes surprisingly well to a wide range of (non-)garments, creative styles, and prompt instructions, consistently delivering high-quality results across diverse scenarios. (3) \textbf{Plug-and-play}: DreamFit is engineered for smooth integration with any community control plugins for diffusion models, ensuring easy compatibility and minimizing adoption barriers. To further enhance generation quality, DreamFit leverages pretrained large multi-modal models (LMMs) to enrich the prompt with fine-grained garment descriptions, thereby reducing the prompt gap between training and inference. We conduct comprehensive experiments on both $768 \times 512$ high-resolution benchmarks and in-the-wild images. DreamFit surpasses all existing methods, highlighting its state-of-the-art capabilities of garment-centric human generation.
Dynamic Try-On: Taming Video Virtual Try-on with Dynamic Attention Mechanism
Dec 13, 2024



Video try-on stands as a promising area for its tremendous real-world potential. Previous research on video try-on has primarily focused on transferring product clothing images to videos with simple human poses, while performing poorly with complex movements. To better preserve clothing details, those approaches are armed with an additional garment encoder, resulting in higher computational resource consumption. The primary challenges in this domain are twofold: (1) leveraging the garment encoder's capabilities in video try-on while lowering computational requirements; (2) ensuring temporal consistency in the synthesis of human body parts, especially during rapid movements. To tackle these issues, we propose a novel video try-on framework based on Diffusion Transformer(DiT), named Dynamic Try-On. To reduce computational overhead, we adopt a straightforward approach by utilizing the DiT backbone itself as the garment encoder and employing a dynamic feature fusion module to store and integrate garment features. To ensure temporal consistency of human body parts, we introduce a limb-aware dynamic attention module that enforces the DiT backbone to focus on the regions of human limbs during the denoising process. Extensive experiments demonstrate the superiority of Dynamic Try-On in generating stable and smooth try-on results, even for videos featuring complicated human postures.
VITON-DiT: Learning In-the-Wild Video Try-On from Human Dance Videos via Diffusion Transformers
May 28, 2024
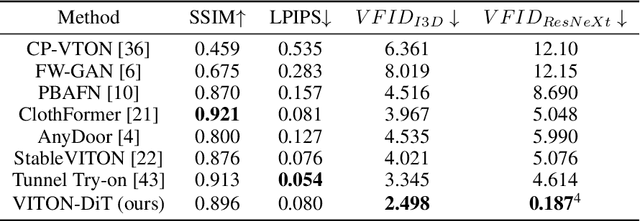
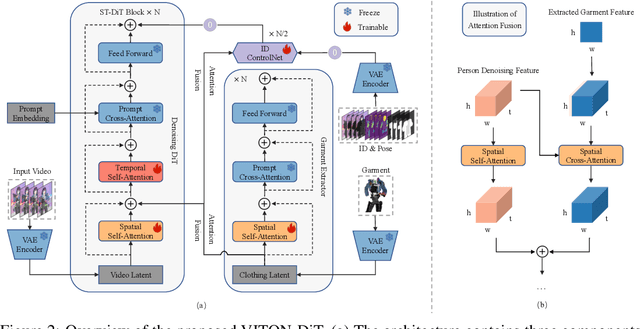
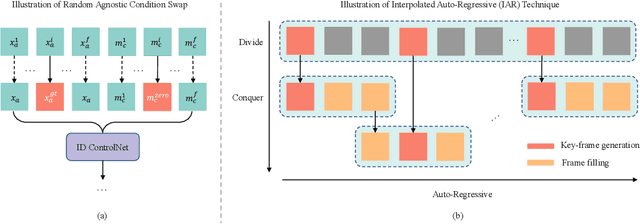
Video try-on stands as a promising area for its tremendous real-world potential. Prior works are limited to transferring product clothing images onto person videos with simple poses and backgrounds, while underperforming on casually captured videos. Recently, Sora revealed the scalability of Diffusion Transformer (DiT) in generating lifelike videos featuring real-world scenarios. Inspired by this, we explore and propose the first DiT-based video try-on framework for practical in-the-wild applications, named VITON-DiT. Specifically, VITON-DiT consists of a garment extractor, a Spatial-Temporal denoising DiT, and an identity preservation ControlNet. To faithfully recover the clothing details, the extracted garment features are fused with the self-attention outputs of the denoising DiT and the ControlNet. We also introduce novel random selection strategies during training and an Interpolated Auto-Regressive (IAR) technique at inference to facilitate long video generation. Unlike existing attempts that require the laborious and restrictive construction of a paired training dataset, severely limiting their scalability, VITON-DiT alleviates this by relying solely on unpaired human dance videos and a carefully designed multi-stage training strategy. Furthermore, we curate a challenging benchmark dataset to evaluate the performance of casual video try-on. Extensive experiments demonstrate the superiority of VITON-DiT in generating spatio-temporal consistent try-on results for in-the-wild videos with complicated human poses.
Fashion Matrix: Editing Photos by Just Talking
Jul 25, 2023



The utilization of Large Language Models (LLMs) for the construction of AI systems has garnered significant attention across diverse fields. The extension of LLMs to the domain of fashion holds substantial commercial potential but also inherent challenges due to the intricate semantic interactions in fashion-related generation. To address this issue, we developed a hierarchical AI system called Fashion Matrix dedicated to editing photos by just talking. This system facilitates diverse prompt-driven tasks, encompassing garment or accessory replacement, recoloring, addition, and removal. Specifically, Fashion Matrix employs LLM as its foundational support and engages in iterative interactions with users. It employs a range of Semantic Segmentation Models (e.g., Grounded-SAM, MattingAnything, etc.) to delineate the specific editing masks based on user instructions. Subsequently, Visual Foundation Models (e.g., Stable Diffusion, ControlNet, etc.) are leveraged to generate edited images from text prompts and masks, thereby facilitating the automation of fashion editing processes. Experiments demonstrate the outstanding ability of Fashion Matrix to explores the collaborative potential of functionally diverse pre-trained models in the domain of fashion editing.
GP-VTON: Towards General Purpose Virtual Try-on via Collaborative Local-Flow Global-Parsing Learning
Mar 24, 2023Image-based Virtual Try-ON aims to transfer an in-shop garment onto a specific person. Existing methods employ a global warping module to model the anisotropic deformation for different garment parts, which fails to preserve the semantic information of different parts when receiving challenging inputs (e.g, intricate human poses, difficult garments). Moreover, most of them directly warp the input garment to align with the boundary of the preserved region, which usually requires texture squeezing to meet the boundary shape constraint and thus leads to texture distortion. The above inferior performance hinders existing methods from real-world applications. To address these problems and take a step towards real-world virtual try-on, we propose a General-Purpose Virtual Try-ON framework, named GP-VTON, by developing an innovative Local-Flow Global-Parsing (LFGP) warping module and a Dynamic Gradient Truncation (DGT) training strategy. Specifically, compared with the previous global warping mechanism, LFGP employs local flows to warp garments parts individually, and assembles the local warped results via the global garment parsing, resulting in reasonable warped parts and a semantic-correct intact garment even with challenging inputs.On the other hand, our DGT training strategy dynamically truncates the gradient in the overlap area and the warped garment is no more required to meet the boundary constraint, which effectively avoids the texture squeezing problem. Furthermore, our GP-VTON can be easily extended to multi-category scenario and jointly trained by using data from different garment categories. Extensive experiments on two high-resolution benchmarks demonstrate our superiority over the existing state-of-the-art methods.
PASTA-GAN++: A Versatile Framework for High-Resolution Unpaired Virtual Try-on
Jul 27, 2022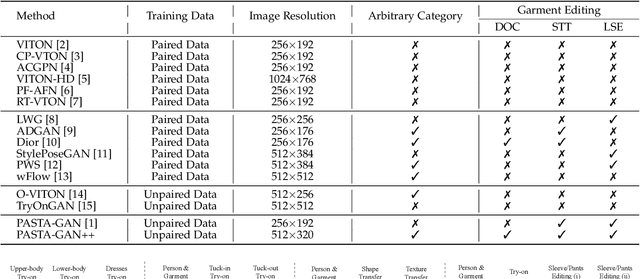

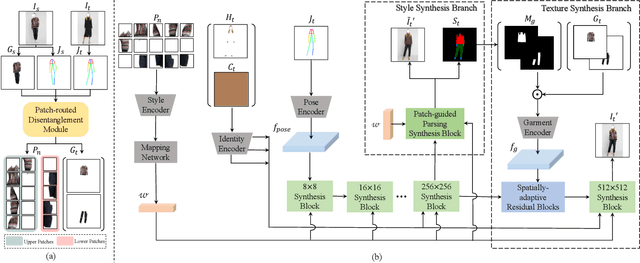

Image-based virtual try-on is one of the most promising applications of human-centric image generation due to its tremendous real-world potential. In this work, we take a step forwards to explore versatile virtual try-on solutions, which we argue should possess three main properties, namely, they should support unsupervised training, arbitrary garment categories, and controllable garment editing. To this end, we propose a characteristic-preserving end-to-end network, the PAtch-routed SpaTially-Adaptive GAN++ (PASTA-GAN++), to achieve a versatile system for high-resolution unpaired virtual try-on. Specifically, our PASTA-GAN++ consists of an innovative patch-routed disentanglement module to decouple the intact garment into normalized patches, which is capable of retaining garment style information while eliminating the garment spatial information, thus alleviating the overfitting issue during unsupervised training. Furthermore, PASTA-GAN++ introduces a patch-based garment representation and a patch-guided parsing synthesis block, allowing it to handle arbitrary garment categories and support local garment editing. Finally, to obtain try-on results with realistic texture details, PASTA-GAN++ incorporates a novel spatially-adaptive residual module to inject the coarse warped garment feature into the generator. Extensive experiments on our newly collected UnPaired virtual Try-on (UPT) dataset demonstrate the superiority of PASTA-GAN++ over existing SOTAs and its ability for controllable garment editing.
Dressing in the Wild by Watching Dance Videos
Mar 29, 2022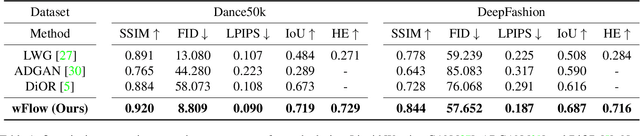
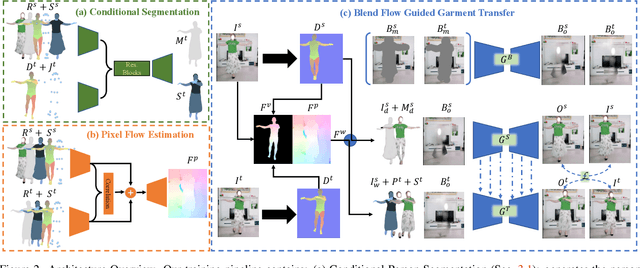
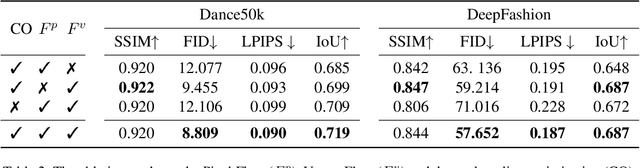
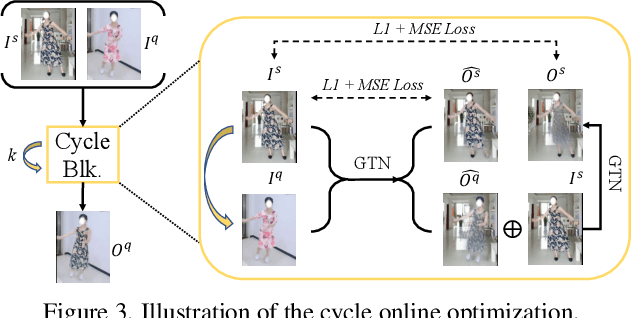
While significant progress has been made in garment transfer, one of the most applicable directions of human-centric image generation, existing works overlook the in-the-wild imagery, presenting severe garment-person misalignment as well as noticeable degradation in fine texture details. This paper, therefore, attends to virtual try-on in real-world scenes and brings essential improvements in authenticity and naturalness especially for loose garment (e.g., skirts, formal dresses), challenging poses (e.g., cross arms, bent legs), and cluttered backgrounds. Specifically, we find that the pixel flow excels at handling loose garments whereas the vertex flow is preferred for hard poses, and by combining their advantages we propose a novel generative network called wFlow that can effectively push up garment transfer to in-the-wild context. Moreover, former approaches require paired images for training. Instead, we cut down the laboriousness by working on a newly constructed large-scale video dataset named Dance50k with self-supervised cross-frame training and an online cycle optimization. The proposed Dance50k can boost real-world virtual dressing by covering a wide variety of garments under dancing poses. Extensive experiments demonstrate the superiority of our wFlow in generating realistic garment transfer results for in-the-wild images without resorting to expensive paired datasets.
Towards Scalable Unpaired Virtual Try-On via Patch-Routed Spatially-Adaptive GAN
Nov 20, 2021
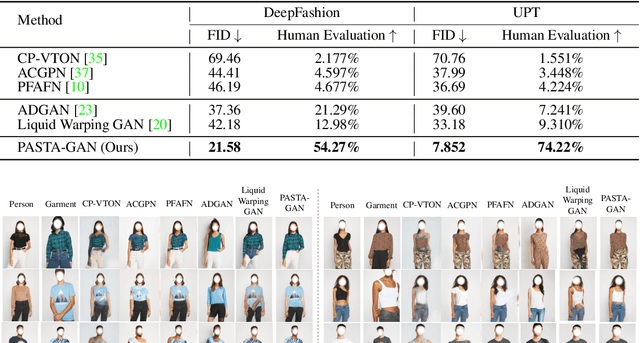
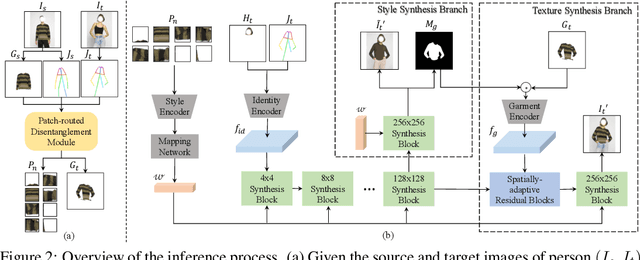

Image-based virtual try-on is one of the most promising applications of human-centric image generation due to its tremendous real-world potential. Yet, as most try-on approaches fit in-shop garments onto a target person, they require the laborious and restrictive construction of a paired training dataset, severely limiting their scalability. While a few recent works attempt to transfer garments directly from one person to another, alleviating the need to collect paired datasets, their performance is impacted by the lack of paired (supervised) information. In particular, disentangling style and spatial information of the garment becomes a challenge, which existing methods either address by requiring auxiliary data or extensive online optimization procedures, thereby still inhibiting their scalability. To achieve a \emph{scalable} virtual try-on system that can transfer arbitrary garments between a source and a target person in an unsupervised manner, we thus propose a texture-preserving end-to-end network, the PAtch-routed SpaTially-Adaptive GAN (PASTA-GAN), that facilitates real-world unpaired virtual try-on. Specifically, to disentangle the style and spatial information of each garment, PASTA-GAN consists of an innovative patch-routed disentanglement module for successfully retaining garment texture and shape characteristics. Guided by the source person keypoints, the patch-routed disentanglement module first decouples garments into normalized patches, thus eliminating the inherent spatial information of the garment, and then reconstructs the normalized patches to the warped garment complying with the target person pose. Given the warped garment, PASTA-GAN further introduces novel spatially-adaptive residual blocks that guide the generator to synthesize more realistic garment details.
M3D-VTON: A Monocular-to-3D Virtual Try-On Network
Aug 11, 2021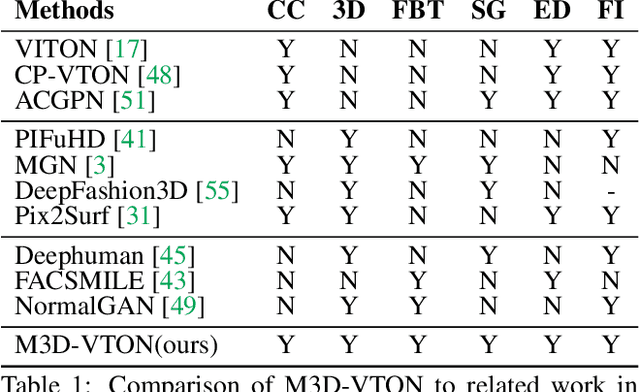
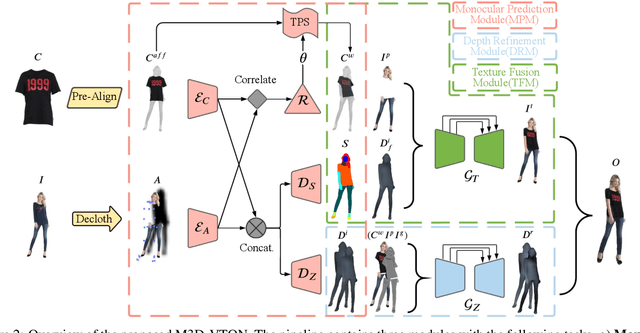
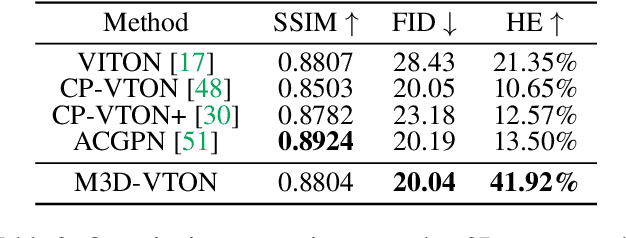
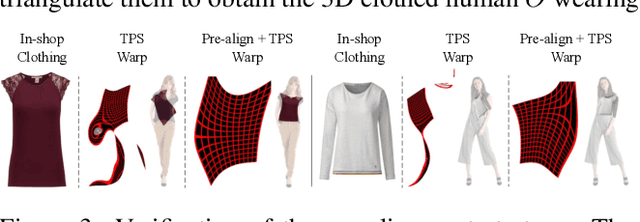
Virtual 3D try-on can provide an intuitive and realistic view for online shopping and has a huge potential commercial value. However, existing 3D virtual try-on methods mainly rely on annotated 3D human shapes and garment templates, which hinders their applications in practical scenarios. 2D virtual try-on approaches provide a faster alternative to manipulate clothed humans, but lack the rich and realistic 3D representation. In this paper, we propose a novel Monocular-to-3D Virtual Try-On Network (M3D-VTON) that builds on the merits of both 2D and 3D approaches. By integrating 2D information efficiently and learning a mapping that lifts the 2D representation to 3D, we make the first attempt to reconstruct a 3D try-on mesh only taking the target clothing and a person image as inputs. The proposed M3D-VTON includes three modules: 1) The Monocular Prediction Module (MPM) that estimates an initial full-body depth map and accomplishes 2D clothes-person alignment through a novel two-stage warping procedure; 2) The Depth Refinement Module (DRM) that refines the initial body depth to produce more detailed pleat and face characteristics; 3) The Texture Fusion Module (TFM) that fuses the warped clothing with the non-target body part to refine the results. We also construct a high-quality synthesized Monocular-to-3D virtual try-on dataset, in which each person image is associated with a front and a back depth map. Extensive experiments demonstrate that the proposed M3D-VTON can manipulate and reconstruct the 3D human body wearing the given clothing with compelling details and is more efficient than other 3D approaches.
WAS-VTON: Warping Architecture Search for Virtual Try-on Network
Aug 01, 2021
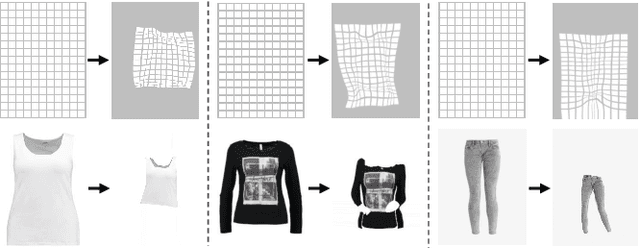

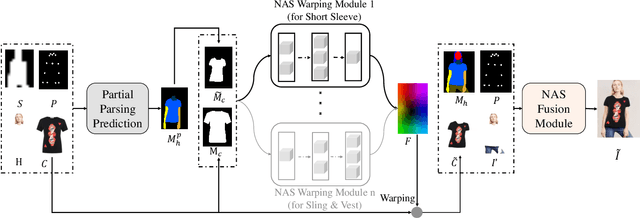
Despite recent progress on image-based virtual try-on, current methods are constraint by shared warping networks and thus fail to synthesize natural try-on results when faced with clothing categories that require different warping operations. In this paper, we address this problem by finding clothing category-specific warping networks for the virtual try-on task via Neural Architecture Search (NAS). We introduce a NAS-Warping Module and elaborately design a bilevel hierarchical search space to identify the optimal network-level and operation-level flow estimation architecture. Given the network-level search space, containing different numbers of warping blocks, and the operation-level search space with different convolution operations, we jointly learn a combination of repeatable warping cells and convolution operations specifically for the clothing-person alignment. Moreover, a NAS-Fusion Module is proposed to synthesize more natural final try-on results, which is realized by leveraging particular skip connections to produce better-fused features that are required for seamlessly fusing the warped clothing and the unchanged person part. We adopt an efficient and stable one-shot searching strategy to search the above two modules. Extensive experiments demonstrate that our WAS-VTON significantly outperforms the previous fixed-architecture try-on methods with more natural warping results and virtual try-on results.