 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Manager: Parallel Agent Loop for Long-form Deep Research
Jan 25, 2026Long-form deep research requires multi-faceted investigations over extended horizons to get a comprehensive report. When handling such complex tasks, existing agents manage context at the subtask level to overcome linear context accumulation and information loss. However, they still adhere to a single context window and sequential execution paradigm, which results in mutual interference and blocking behavior, restricting scalability and adaptability. To address this issue, this paper introduces Self-Manager, a parallel agent loop that enables asynchronous and concurrent execution. The main thread can create multiple subthreads, each with its own isolated context, and manage them iteratively through Thread Control Blocks, allowing for more focused and flexible parallel agent execution. To assess its effectiveness, we benchmark Self-Manager on DeepResearch Bench, where it consistently outperforms existing single-agent loop baselines across all metrics. Furthermore, we conduct extensive analytical experiments to demonstrate the necessity of Self-Manager's design choices, as well as its advantages in contextual capacity, efficiency, and generalization.
RAVine: Reality-Aligned Evaluation for Agentic Search
Jul 22, 2025

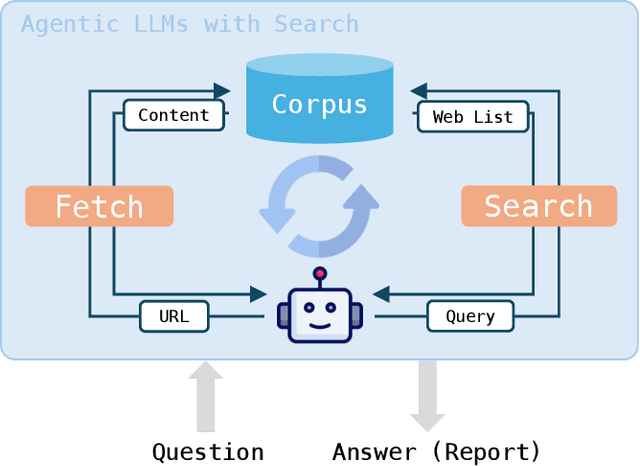
Agentic search, as a more autonomous and adaptive paradigm of retrieval augmentation, is driving the evolution of intelligent search systems. However, existing evaluation frameworks fail to align well with the goals of agentic search. First, the complex queries commonly used in current benchmarks often deviate from realistic user search scenarios. Second, prior approaches tend to introduce noise when extracting ground truth for end-to-end evaluations, leading to distorted assessments at a fine-grained level. Third, most current frameworks focus solely on the quality of final answers, neglecting the evaluation of the iterative process inherent to agentic search. To address these limitations, we propose RAVine -- a Reality-Aligned eValuation framework for agentic LLMs with search. RAVine targets multi-point queries and long-form answers that better reflect user intents, and introduces an attributable ground truth construction strategy to enhance the accuracy of fine-grained evaluation. Moreover, RAVine examines model's interaction with search tools throughout the iterative process, and accounts for factors of efficiency. We benchmark a series of models using RAVine and derive several insights, which we hope will contribute to advancing the development of agentic search systems. The code and datasets are available at https://github.com/SwordFaith/RAVine.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Towards Unsupervised Eye-Region Segmentation for Eye Tracking
Oct 08, 2024



Finding the eye and parsing out the parts (e.g. pupil and iris) is a key prerequisite for image-based eye tracking, which has become an indispensable module in today's head-mounted VR/AR devices. However, a typical route for training a segmenter requires tedious handlabeling. In this work, we explore an unsupervised way. First, we utilize priors of human eye and extract signals from the image to establish rough clues indicating the eye-region structure. Upon these sparse and noisy clues, a segmentation network is trained to gradually identify the precise area for each part. To achieve accurate parsing of the eye-region, we first leverage the pretrained foundation model Segment Anything (SAM) in an automatic way to refine the eye indications. Then, the learning process is designed in an end-to-end manner following progressive and prior-aware principle. Experiments show that our unsupervised approach can easily achieve 90% (the pupil and iris) and 85% (the whole eye-region) of the performances under supervised learning.
CondSeg: Ellipse Estimation of Pupil and Iris via Conditioned Segmentation
Aug 30, 2024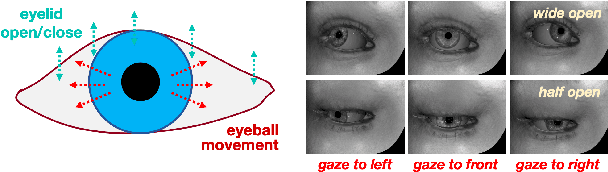

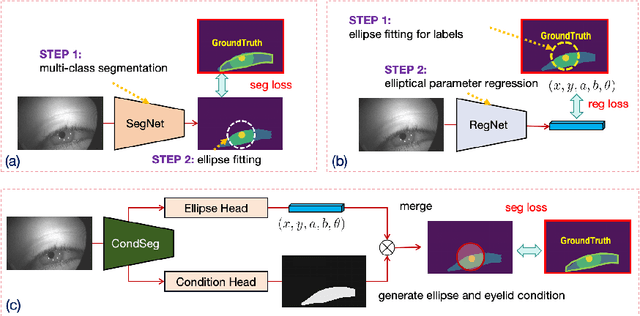

Parsing of eye components (i.e. pupil, iris and sclera) is fundamental for eye tracking and gaze estimation for AR/VR products. Mainstream approaches tackle this problem as a multi-class segmentation task, providing only visible part of pupil/iris, other methods regress elliptical parameters using human-annotated full pupil/iris parameters. In this paper, we consider two priors: projected full pupil/iris circle can be modelled with ellipses (ellipse prior), and the visibility of pupil/iris is controlled by openness of eye-region (condition prior), and design a novel method CondSeg to estimate elliptical parameters of pupil/iris directly from segmentation labels, without explicitly annotating full ellipses, and use eye-region mask to control the visibility of estimated pupil/iris ellipses. Conditioned segmentation loss is used to optimize the parameters by transforming parameterized ellipses into pixel-wise soft masks in a differentiable way. Our method is tested on public datasets (OpenEDS-2019/-2020) and shows competitive results on segmentation metrics, and provides accurate elliptical parameters for further applications of eye tracking simultaneously.
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Apr 09, 2024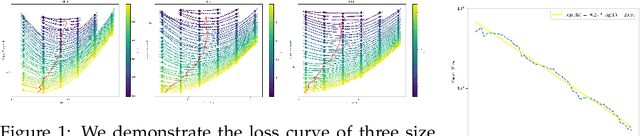


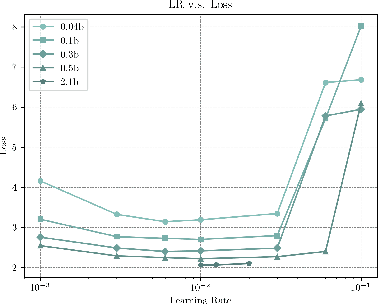
The burgeoning interest in developing Large Language Models (LLMs) with up to trillion parameters has been met with concerns regarding resource efficiency and practical expense, particularly given the immense cost of experimentation. This scenario underscores the importance of exploring the potential of Small Language Models (SLMs) as a resource-efficient alternative. In this context, we introduce MiniCPM, specifically the 1.2B and 2.4B non-embedding parameter variants, not only excel in their respective categories but also demonstrate capabilities on par with 7B-13B LLMs. While focusing on SLMs, our approach exhibits scalability in both model and data dimensions for future LLM research. Regarding model scaling, we employ extensive model wind tunnel experiments for stable and optimal scaling. For data scaling, we introduce a Warmup-Stable-Decay (WSD) learning rate scheduler (LRS), conducive to continuous training and domain adaptation. We present an in-depth analysis of the intriguing training dynamics that occurred in the WSD LRS. With WSD LRS, we are now able to efficiently study data-model scaling law without extensive retraining experiments on both axes of model and data, from which we derive the much higher compute optimal data-model ratio than Chinchilla Optimal. Additionally, we introduce MiniCPM family, including MiniCPM-DPO, MiniCPM-MoE and MiniCPM-128K, whose excellent performance further cementing MiniCPM's foundation in diverse SLM applications. MiniCPM models are available publicly at https://github.com/OpenBMB/MiniCPM .
OCEAN: An Openspace Collision-free Trajectory Planner for Autonomous Parking Based on ADMM
Mar 08, 2024



In this paper, we propose an Openspace Collision-freE trAjectory plaNner (OCEAN) for autonomous parking. OCEAN is an optimization-based trajectory planner accelerated by Alternating Direction Method of Multiplier (ADMM) with enhanced computational efficiency and robustness, and is suitable for all scenes with few dynamic obstacles. Starting from a hierarchical optimization-based collision avoidance framework, the trajectory planning problem is first warm-started by a collision-free Hybrid A* trajectory, then the collision avoidance trajectory planning problem is reformulated as a smooth and convex dual form, and solved by ADMM in parallel. The optimization variables are carefully split into several groups so that ADMM sub-problems are formulated as Quadratic Programming (QP), Sequential Quadratic Programming (SQP),and Second Order Cone Programming (SOCP) problems that can be efficiently and robustly solved. We validate our method both in hundreds of simulation scenarios and hundreds of hours of public parking areas. The results show that the proposed method has better system performance compared with other benchmarks.
MTS-DVGAN: Anomaly Detection in Cyber-Physical Systems using a Dual Variational Generative Adversarial Network
Nov 04, 2023

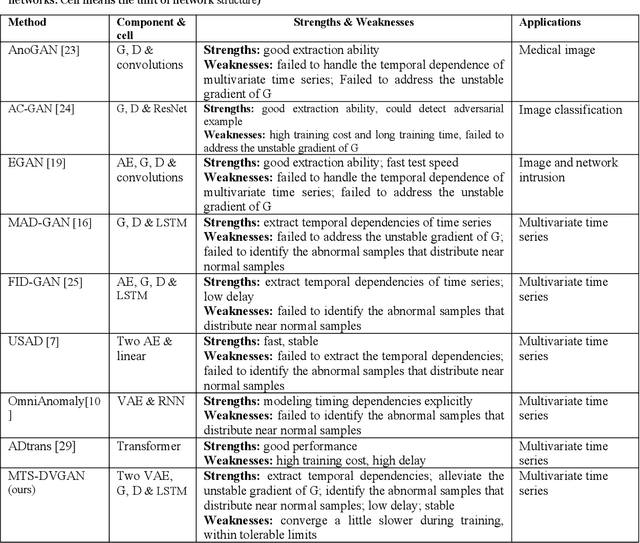
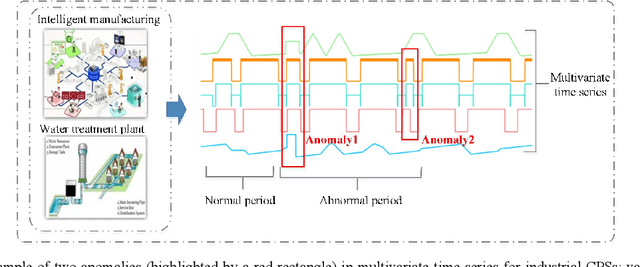
Deep generative models are promising in detecting novel cyber-physical attacks, mitigating the vulnerability of Cyber-physical systems (CPSs) without relying on labeled information. Nonetheless, these generative models face challenges in identifying attack behaviors that closely resemble normal data, or deviate from the normal data distribution but are in close proximity to the manifold of the normal cluster in latent space. To tackle this problem, this article proposes a novel unsupervised dual variational generative adversarial model named MST-DVGAN, to perform anomaly detection in multivariate time series data for CPS security. The central concept is to enhance the model's discriminative capability by widening the distinction between reconstructed abnormal samples and their normal counterparts. Specifically, we propose an augmented module by imposing contrastive constraints on the reconstruction process to obtain a more compact embedding. Then, by exploiting the distribution property and modeling the normal patterns of multivariate time series, a variational autoencoder is introduced to force the generative adversarial network (GAN) to generate diverse samples. Furthermore, two augmented loss functions are designed to extract essential characteristics in a self-supervised manner through mutual guidance between the augmented samples and original samples. Finally, a specific feature center loss is introduced for the generator network to enhance its stability. Empirical experiments are conducted on three public datasets, namely SWAT, WADI and NSL_KDD. Comparing with the state-of-the-art methods, the evaluation results show that the proposed MTS-DVGAN is more stable and can achieve consistent performance improvement.
* 27 pages, 14 figures, 8 tables. Accepted by Computers & Security
IntTower: the Next Generation of Two-Tower Model for Pre-Ranking System
Oct 18, 2022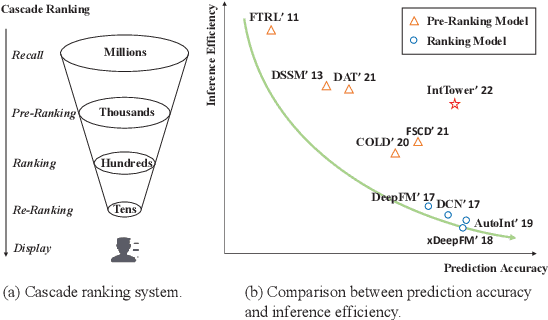
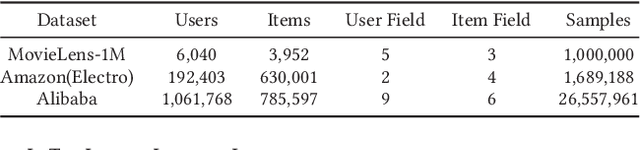
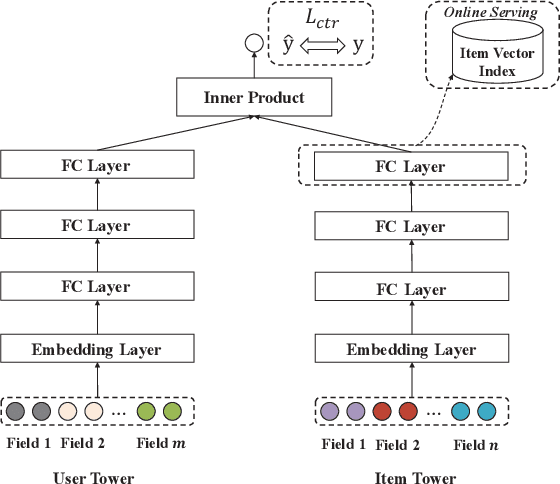
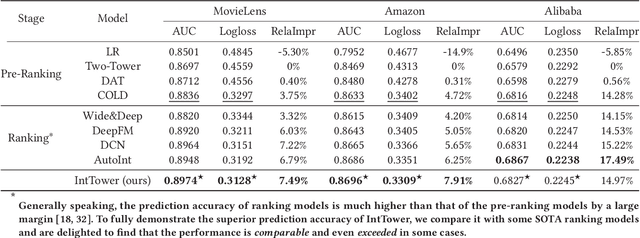
Scoring a large number of candidates precisely in several milliseconds is vital for industrial pre-ranking systems. Existing pre-ranking systems primarily adopt the \textbf{two-tower} model since the ``user-item decoupling architecture'' paradigm is able to balance the \textit{efficiency} and \textit{effectiveness}. However, the cost of high efficiency is the neglect of the potential information interaction between user and item towers, hindering the prediction accuracy critically. In this paper, we show it is possible to design a two-tower model that emphasizes both information interactions and inference efficiency. The proposed model, IntTower (short for \textit{Interaction enhanced Two-Tower}), consists of Light-SE, FE-Block and CIR modules. Specifically, lightweight Light-SE module is used to identify the importance of different features and obtain refined feature representations in each tower. FE-Block module performs fine-grained and early feature interactions to capture the interactive signals between user and item towers explicitly and CIR module leverages a contrastive interaction regularization to further enhance the interactions implicitly. Experimental results on three public datasets show that IntTower outperforms the SOTA pre-ranking models significantly and even achieves comparable performance in comparison with the ranking models. Moreover, we further verify the effectiveness of IntTower on a large-scale advertisement pre-ranking system. The code of IntTower is publicly available\footnote{https://github.com/archersama/IntTower}