 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unsupervised Eye-Region Segmentation for Eye Tracking
Oct 08, 2024



Finding the eye and parsing out the parts (e.g. pupil and iris) is a key prerequisite for image-based eye tracking, which has become an indispensable module in today's head-mounted VR/AR devices. However, a typical route for training a segmenter requires tedious handlabeling. In this work, we explore an unsupervised way. First, we utilize priors of human eye and extract signals from the image to establish rough clues indicating the eye-region structure. Upon these sparse and noisy clues, a segmentation network is trained to gradually identify the precise area for each part. To achieve accurate parsing of the eye-region, we first leverage the pretrained foundation model Segment Anything (SAM) in an automatic way to refine the eye indications. Then, the learning process is designed in an end-to-end manner following progressive and prior-aware principle. Experiments show that our unsupervised approach can easily achieve 90% (the pupil and iris) and 85% (the whole eye-region) of the performances under supervised learning.
Ground-roll Separation From Land Seismic Records Based on Convolutional Neural Network
Sep 05, 2024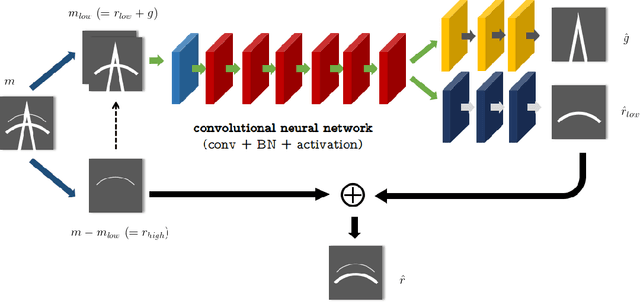
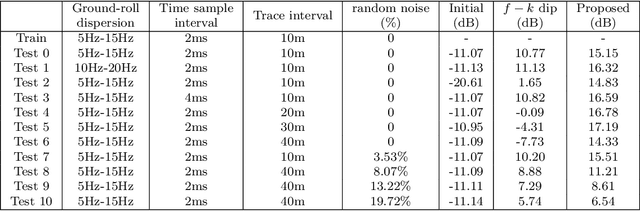
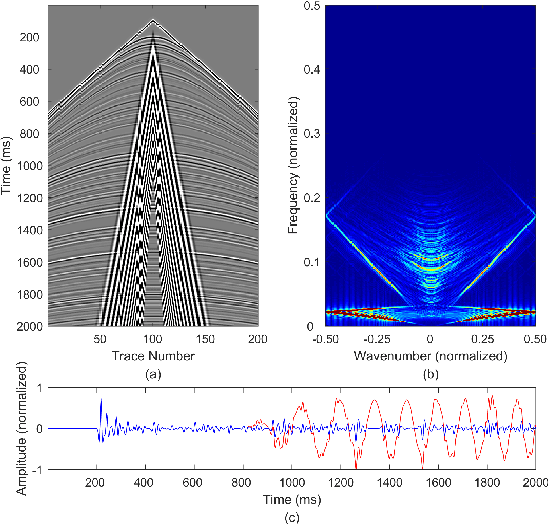
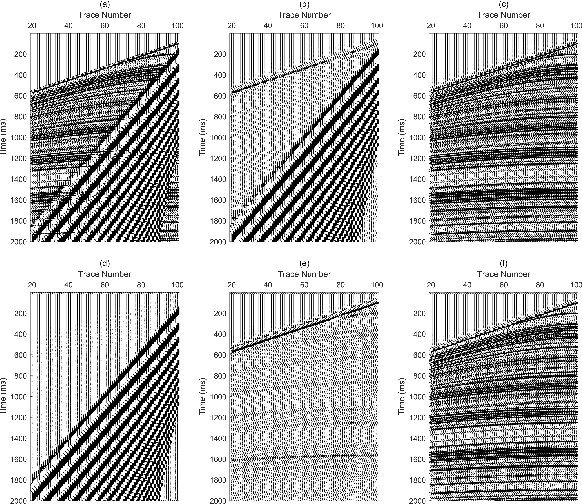
Ground-roll wave is a common coherent noise in land field seismic data. This Rayleigh-type surface wave usually has low frequency, low apparent velocity, and high amplitude, therefore obscures the reflection events of seismic shot gathers. Commonly used techniques focus on the differences of ground-roll and reflection in transformed domain such as $f-k$ domain, wavelet domain, or curvelet domain. These approaches use a series of fixed atoms or bases to transform the data in time-space domain into transformed domain to separate different waveforms, thus tend to suffer from the complexity for a delicate design of the parameters of the transform domain filter. To deal with these problems, a novel way is proposed to separate ground-roll from reflections using convolutional neural network (CNN) model based method to learn to extract the features of ground-roll and reflections automatically based on training data. In the proposed method, low-pass filtered seismic data which is contaminated by ground-roll wave is used as input of CNN, and then outputs both ground-roll component and low-frequency part of reflection component simultaneously. Discriminative loss is applied together with similarity loss in the training process to enhance the similarity to their train labels as well as the difference between the two outputs. Experiments are conducted on both synthetic and real data, showing that CNN based method can separate ground roll from reflections effectively, and has generalization ability to a certain extent.
CondSeg: Ellipse Estimation of Pupil and Iris via Conditioned Segmentation
Aug 30, 2024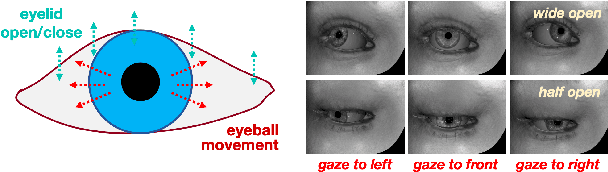

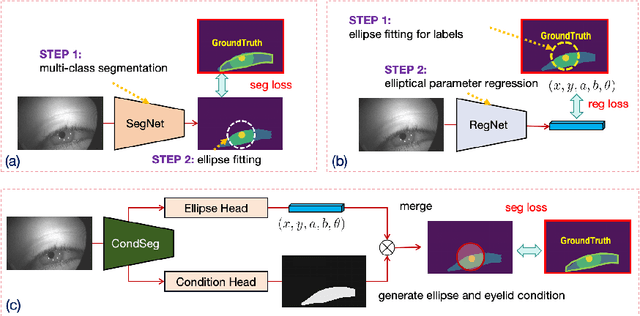

Parsing of eye components (i.e. pupil, iris and sclera) is fundamental for eye tracking and gaze estimation for AR/VR products. Mainstream approaches tackle this problem as a multi-class segmentation task, providing only visible part of pupil/iris, other methods regress elliptical parameters using human-annotated full pupil/iris parameters. In this paper, we consider two priors: projected full pupil/iris circle can be modelled with ellipses (ellipse prior), and the visibility of pupil/iris is controlled by openness of eye-region (condition prior), and design a novel method CondSeg to estimate elliptical parameters of pupil/iris directly from segmentation labels, without explicitly annotating full ellipses, and use eye-region mask to control the visibility of estimated pupil/iris ellipses. Conditioned segmentation loss is used to optimize the parameters by transforming parameterized ellipses into pixel-wise soft masks in a differentiable way. Our method is tested on public datasets (OpenEDS-2019/-2020) and shows competitive results on segmentation metrics, and provides accurate elliptical parameters for further applications of eye tracking simultaneously.
A Deep CNN Model for Ringing Effect Attenuation of Vibroseis Data
Aug 03, 2024



In the field of exploration geophysics, seismic vibrator is one of the widely used seismic sources to acquire seismic data, which is usually named vibroseis. "Ringing effect" is a common problem in vibroseis data processing due to the limited frequency bandwidth of the vibrator, which degrades the performance of first-break picking. In this paper, we proposed a novel deringing model for vibroseis data using deep convolutional neural network (CNN). In this model we use end-to-end training strategy to obtain the deringed data directly, and skip connections to improve model training process and preserve the details of vibroseis data. For real vibroseis deringing task we synthesize training data and corresponding labels from real vibroseis data and utilize them to train the deep CNN model. Experiments are conducted both on synthetic data and real vibroseis data. The experiment results show that deep CNN model can attenuate the ringing effect effectively and expand the bandwidth of vibroseis data. The STA/LTA ratio method for first-break picking also shows improvement on deringed vibroseis data using deep CNN model.
1st Workshop on Maritime Computer Vision 2023: Challenge Results
Nov 28, 2022

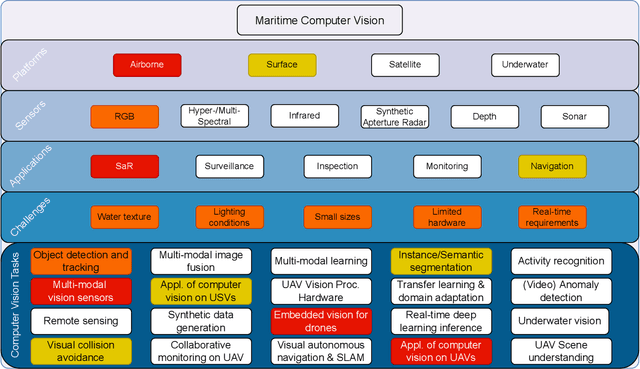
The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
ELSR: Extreme Low-Power Super Resolution Network For Mobile Devices
Aug 31, 2022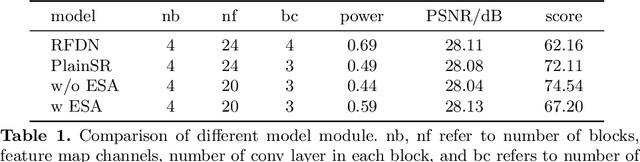
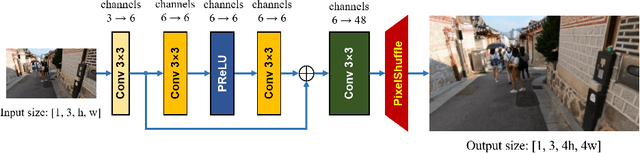
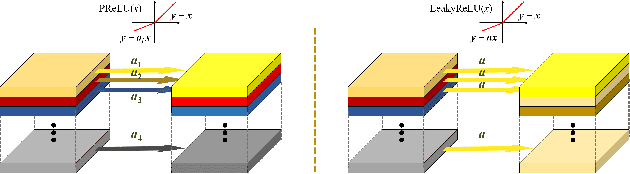

With the popularity of mobile devices, e.g., smartphone and wearable devices, lighter and faster model is crucial for the application of video super resolution. However, most previous lightweight models tend to concentrate on reducing lantency of model inference on desktop GPU, which may be not energy efficient in current mobile devices. In this paper, we proposed Extreme Low-Power Super Resolution (ELSR) network which only consumes a small amount of energy in mobile devices. Pretraining and finetuning methods are applied to boost the performance of the extremely tiny model. Extensive experiments show that our method achieves a excellent balance between restoration quality and power consumption. Finally, we achieve a competitive score of 90.9 with PSNR 27.34 dB and power 0.09 W/30FPS on the target MediaTek Dimensity 9000 plantform, ranking 1st place in the Mobile AI & AIM 2022 Real-Time Video Super-Resolution Challenge.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022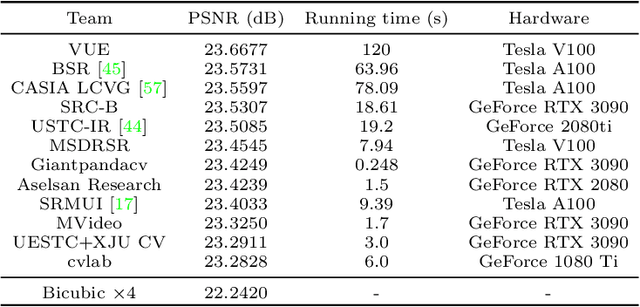
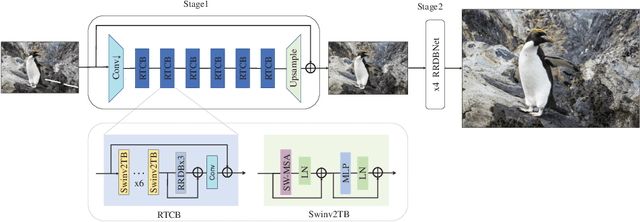

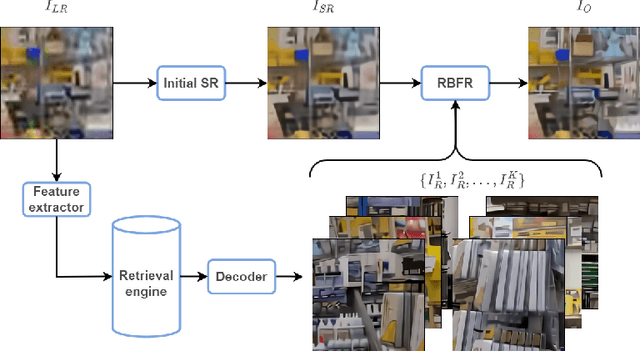
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
Exploring Inter-frequency Guidance of Image for Lightweight Gaussian Denoising
Dec 22, 2021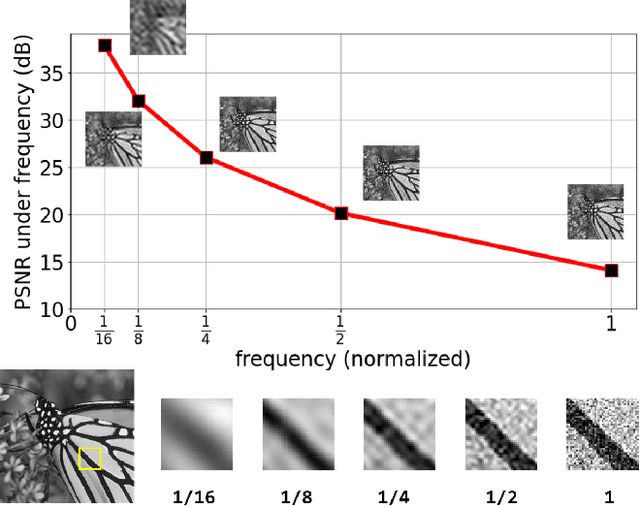

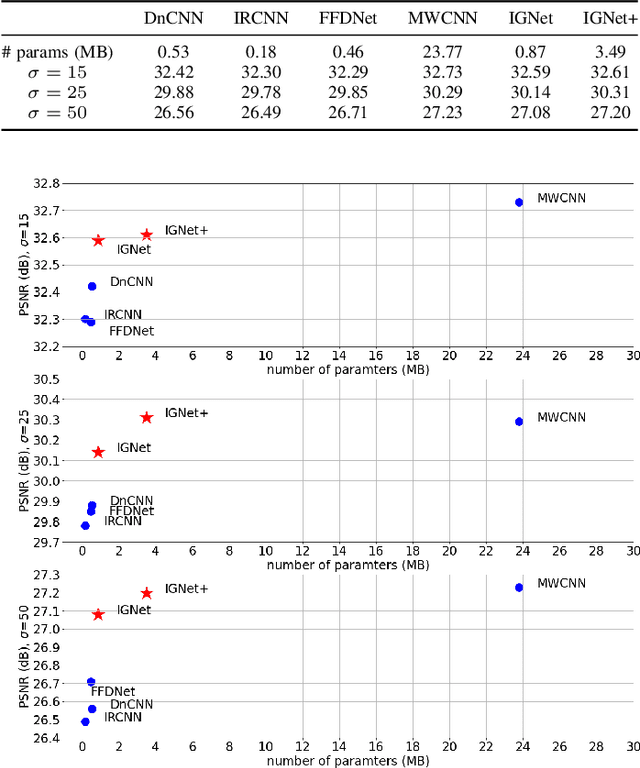
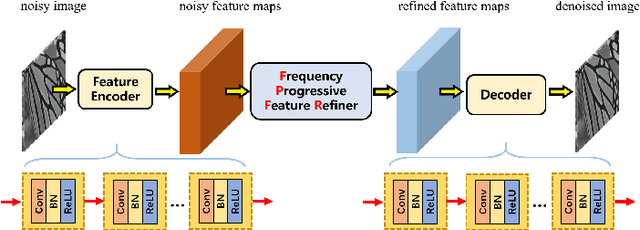
Image denoising is of vital importance in many imaging or computer vision related areas. With the convolutional neural networks showing strong capability in computer vision tasks, the performance of image denoising has also been brought up by CNN based methods. Though CNN based image denoisers show promising results on this task, most of the current CNN based methods try to learn the mapping from noisy image to clean image directly, which lacks the explicit exploration of prior knowledge of images and noises. Natural images are observed to obey the reciprocal power law, implying the low-frequency band of image tend to occupy most of the energy. Thus in the condition of AGWN (additive gaussian white noise) deterioration, low-frequency band tend to preserve a higher PSNR than high-frequency band. Considering the spatial morphological consistency of different frequency bands, low-frequency band with more fidelity can be used as a guidance to refine the more contaminated high-frequency bands. Based on this thought, we proposed a novel network architecture denoted as IGNet, in order to refine the frequency bands from low to high in a progressive manner. Firstly, it decomposes the feature maps into high- and low-frequency subbands using DWT (discrete wavelet transform) iteratively, and then each low band features are used to refine the high band features. Finally, the refined feature maps are processed by a decoder to recover the clean result. With this design, more inter-frequency prior and information are utilized, thus the model size can be lightened while still perserves competitive results. Experiments on several public datasets show that our model obtains competitive performance comparing with other state-of-the-art methods yet with a lightweight structure.