 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
Learning-based Regularization for Cardiac Strain Analysis with Ability for Domain Adaptation
Jul 12, 2018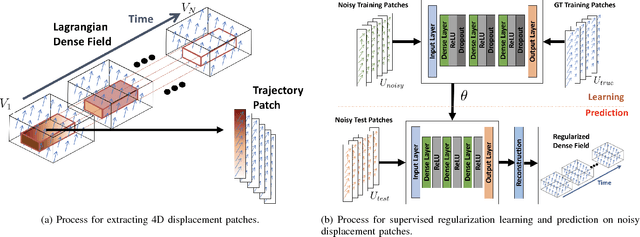
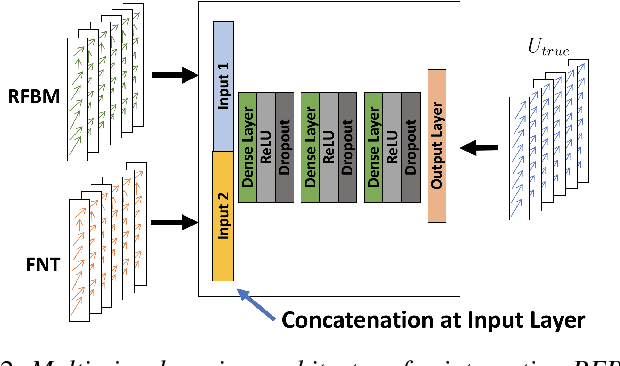
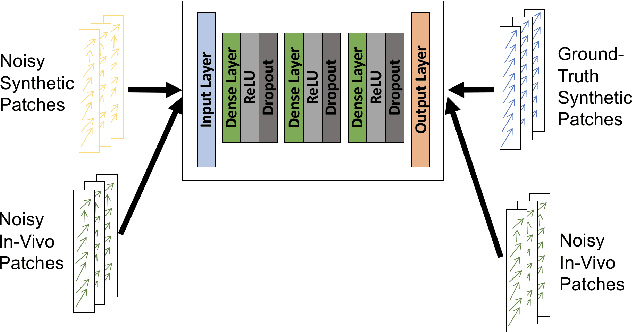
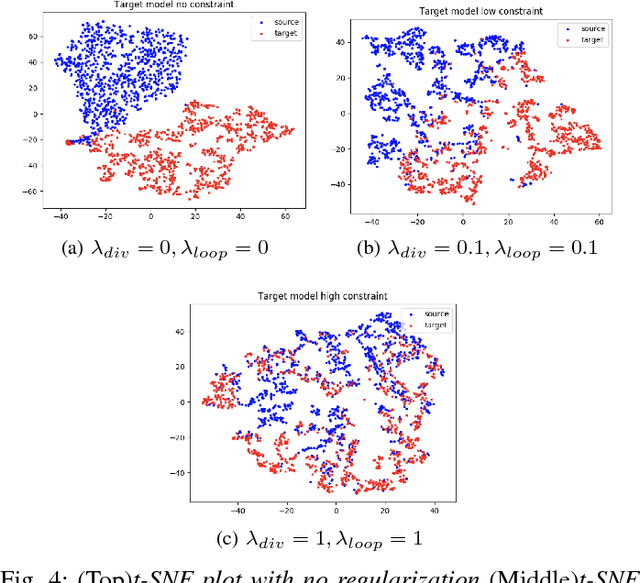
Reliable motion estimation and strain analysis using 3D+time echocardiography (4DE) for localization and characterization of myocardial injury is valuable for early detection and targeted interventions. However, motion estimation is difficult due to the low-SNR that stems from the inherent image properties of 4DE, and intelligent regularization is critical for producing reliable motion estimates. In this work, we incorporated the notion of domain adaptation into a supervised neural network regularization framework. We first propose an unsupervised autoencoder network with biomechanical constraints for learning a latent representation that is shown to have more physiologically plausible displacements. We extended this framework to include a supervised loss term on synthetic data and showed the effects of biomechanical constraints on the network's ability for domain adaptation. We validated both the autoencoder and semi-supervised regularization method on in vivo data with implanted sonomicrometers. Finally, we showed the ability of our semi-supervised learning regularization approach to identify infarcted regions using estimated regional strain maps with good agreement to manually traced infarct regions from postmortem excised hearts.
Flow Network Tracking for Spatiotemporal and Periodic Point Matching: Applied to Cardiac Motion Analysis
Jul 09, 2018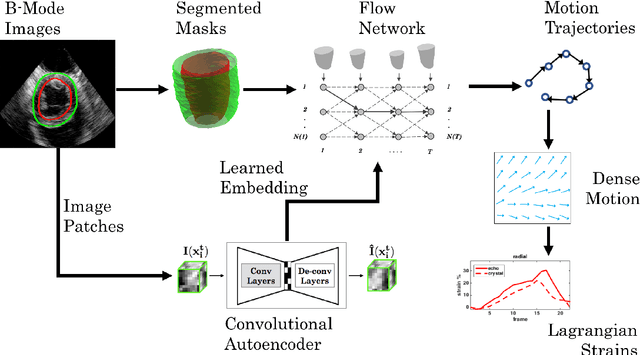

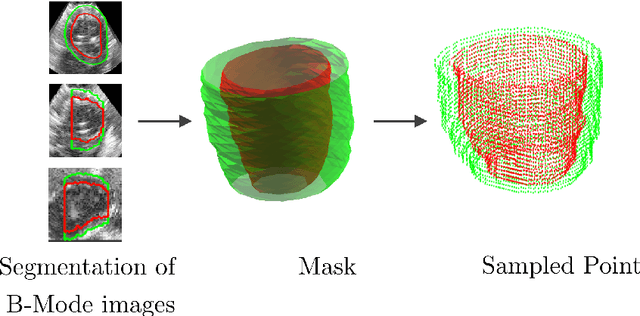
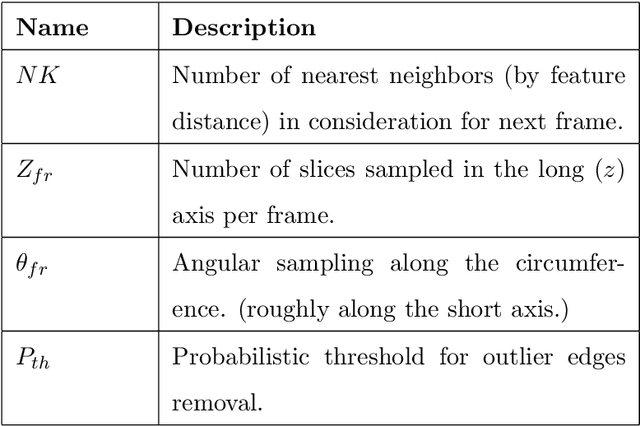
The accurate quantification of left ventricular (LV) deformation/strain shows significant promise for quantitatively assessing cardiac function for use in diagnosis and therapy planning (Jasaityte et al., 2013). However, accurate estimation of the displacement of myocardial tissue and hence LV strain has been challenging due to a variety of issues, including those related to deriving tracking tokens from images and following tissue locations over the entire cardiac cycle. In this work, we propose a point matching scheme where correspondences are modeled as flow through a graphical network. Myocardial surface points are set up as nodes in the network and edges define neighborhood relationships temporally. The novelty lies in the constraints that are imposed on the matching scheme, which render the correspondences one-to-one through the entire cardiac cycle, and not just two consecutive frames. The constraints also encourage motion to be cyclic, which is an important characteristic of LV motion. We validate our method by applying it to the estimation of quantitative LV displacement and strain estimation using 8 synthetic and 8 open-chested canine 4D echocardiographic image sequences, the latter with sonomicrometric crystals implanted on the LV wall. We were able to achieve excellent tracking accuracy on the synthetic dataset and observed a good correlation with crystal-based strains on the in-vivo data.
Generative Encoder-Decoder Models for Task-Oriented Spoken Dialog Systems with Chatting Capability
Jun 26, 2017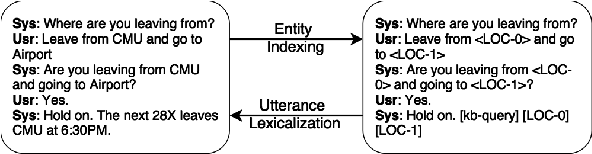


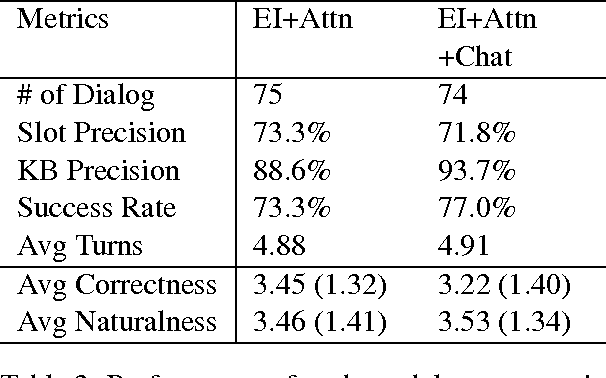
Generative encoder-decoder models offer great promise in developing domain-general dialog systems. However, they have mainly been applied to open-domain conversations. This paper presents a practical and novel framework for building task-oriented dialog systems based on encoder-decoder models. This framework enables encoder-decoder models to accomplish slot-value independent decision-making and interact with external databases. Moreover, this paper shows the flexibility of the proposed method by interleaving chatting capability with a slot-filling system for better out-of-domain recovery. The models were trained on both real-user data from a bus information system and human-human chat data. Results show that the proposed framework achieves good performance in both offline evaluation metrics and in task success rate with human users.