 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust and Task-Invariant Functional Representation from fMRI through Siamese Self-Supervised Learning
May 27, 2026Functional magnetic resonance imaging (fMRI) is a powerful tool for investigating human brain function. However, the high cost of data acquisition and the inherent subjectivity of psychiatric rating scales often lead to datasets with small sample sizes and variable label quality, especially when targeting a specific neurological condition. Combined with the inherently high dimensionality of fMRI data, these limitations substantially increase the risk of model overfitting. Recent years have seen growing interest in developing fMRI foundation models by combining multiple datasets; however, the computational resources needed for pretraining and fine-tuning are often prohibitive. We show that a lightweight self-supervised framework yields representations that generalize across diverse downstream tasks, outperforming fully supervised baselines and approaching the performance of large-scale models. We introduce BrainSimSiam, a data-efficient self-supervised representation learning framework that leverages positive-only data pairs to learn robust and generalizable features. We demonstrate that the learned representations achieve strong performance across multiple downstream classification and regression tasks, highlighting the potential of BrainSimSiam for data-limited neuroimaging applications.
FM-fMRI: Event Conditioned Flow Matching for Rest-to-Task fMRI Time-Series Synthesis
May 26, 2026Task-based fMRI provides a direct readout of task-evoked neural dynamics, but it is expensive and difficult to acquire at scale, motivating rest-to-task synthesis from widely available resting-state fMRI (rsfMRI). We propose FM-fMRI, an event-conditioned flow-matching model that learns a continuous-time conditional vector field to generate task ROI time series from a subject's rsfMRI and the task event information. The formulation enables fast ODE-based sampling and flexible conditioning over heterogeneous event schedules. Rather than optimizing for pointwise reconstruction, we evaluated generated signals using complementary criteria that probe temporal and spectral structure, subject and group-level connectome consistency, and distributional alignment. On the public Human Connectome Project and internal BioPoint autism cohort, FM-fMRI achieves the strongest spectral and connectivity agreement and improved distribution-level matching over conditional diffusion, generative adversarial networks (GANs), and variational autoencoders (VAEs) baselines. Furthermore, we augment the BioPoint cohort by synthesizing task-fMRI ROI time series with our method, improving downstream autism classification and demonstrating practical utility in data-limited clinical settings. The code will be available on GitHub.
BioFact-MoE: Biologically Factorized Mixture of Experts for Vision-Language Prognostic Modeling in Hepatocellular Carcinoma
May 25, 2026Hepatocellular carcinoma (HCC) is biologically heterogeneous, shaped by the interplay between hepatic functional reserve and tumor-related oncologic factors; thus, similar survival outcomes may reflect fundamentally different underlying biological processes. Prognostic modeling in HCC is informed by rich multimodal information from multiparametric MRI and radiology reports from routine clinical practice. Existing prognostic vision-language models (VLMs) learn a single entangled latent representation that blends hepatic and tumor-related factors, limiting both accuracy and biological interpretability. We present BioFact-MoE, a biologically factorized Mixture of Experts (MoE) framework that explicitly decomposes liver and tumor factors via biologically supervised experts within a residual MoE survival architecture. On a HCC cohort of N=588 patients (pretrained on 4,582 3D MRI image-report pairs), BioFact-MoE consistently improves survival prediction over all baselines across time horizons, achieving 12-, 18-, and 24-month AUCs of 75.33%, 75.85%, and 73.96%. Beyond scalar risk prediction, gated expert weights enable phenotype-aware risk stratification. Pathway-informed gating uncovers clinically meaningful treatment-associated survival heterogeneity. In held-out validation, hepatic and tumor embeddings show selective associations with liver function and tumor burden markers, respectively (p<0.05), without supervision. The code is available at https://github.com/jy-639/BioFact-MoE.
Progressive Test Time Energy Adaptation for Medical Image Segmentation
Mar 20, 2025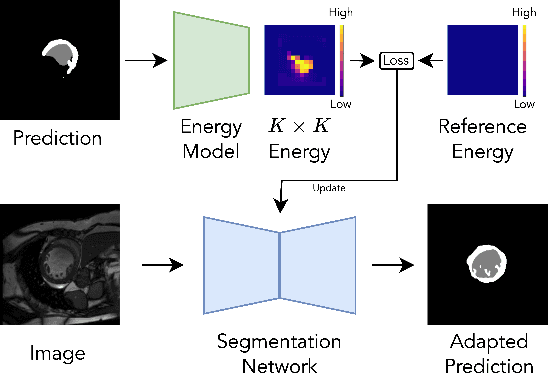
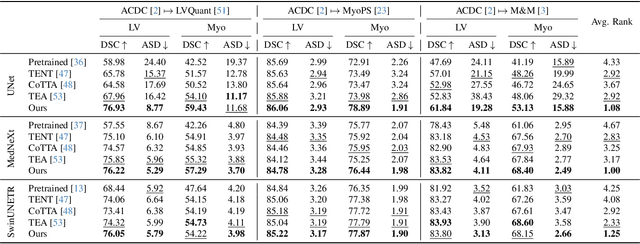
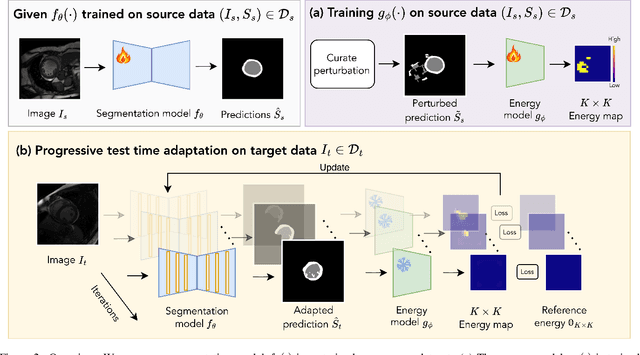
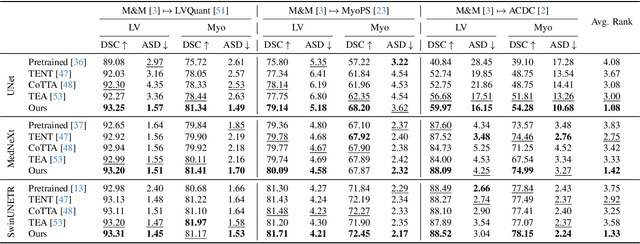
We propose a model-agnostic, progressive test-time energy adaptation approach for medical image segmentation. Maintaining model performance across diverse medical datasets is challenging, as distribution shifts arise from inconsistent imaging protocols and patient variations. Unlike domain adaptation methods that require multiple passes through target data - impractical in clinical settings - our approach adapts pretrained models progressively as they process test data. Our method leverages a shape energy model trained on source data, which assigns an energy score at the patch level to segmentation maps: low energy represents in-distribution (accurate) shapes, while high energy signals out-of-distribution (erroneous) predictions. By minimizing this energy score at test time, we refine the segmentation model to align with the target distribution. To validate the effectiveness and adaptability, we evaluated our framework on eight public MRI (bSSFP, T1- and T2-weighted) and X-ray datasets spanning cardiac, spinal cord, and lung segmentation. We consistently outperform baselines both quantitatively and qualitatively.
Causal Modeling of fMRI Time-series for Interpretable Autism Spectrum Disorder Classification
Feb 21, 2025
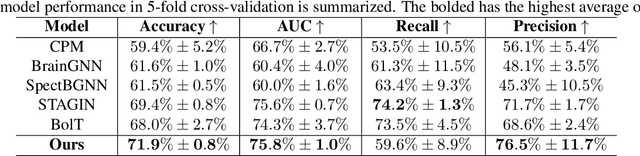
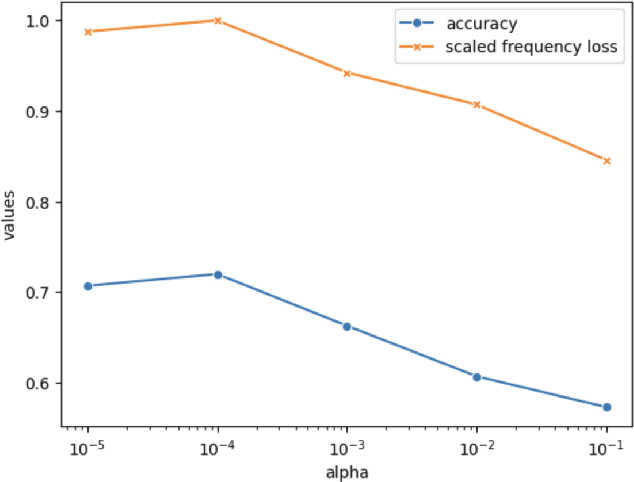
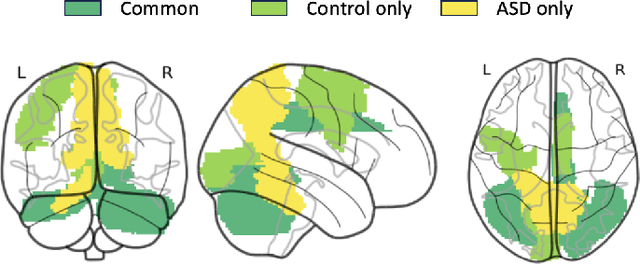
Autism spectrum disorder (ASD) is a neurological and developmental disorder that affects social and communicative behaviors. It emerges in early life and is generally associated with lifelong disabilities. Thus, accurate and early diagnosis could facilitate treatment outcomes for those with ASD. Functional magnetic resonance imaging (fMRI) is a useful tool that measures changes in brain signaling to facilitate our understanding of ASD. Much effort is being made to identify ASD biomarkers using various connectome-based machine learning and deep learning classifiers. However, correlation-based models cannot capture the non-linear interactions between brain regions. To solve this problem, we introduce a causality-inspired deep learning model that uses time-series information from fMRI and captures causality among ROIs useful for ASD classification. The model is compared with other baseline and state-of-the-art models with 5-fold cross-validation on the ABIDE dataset. We filtered the dataset by choosing all the images with mean FD less than 15mm to ensure data quality. Our proposed model achieved the highest average classification accuracy of 71.9% and an average AUC of 75.8%. Moreover, the inter-ROI causality interpretation of the model suggests that the left precuneus, right precuneus, and cerebellum are placed in the top 10 ROIs in inter-ROI causality among the ASD population. In contrast, these ROIs are not ranked in the top 10 in the control population. We have validated our findings with the literature and found that abnormalities in these ROIs are often associated with ASD.
Enhancing Uncertainty Estimation in Semantic Segmentation via Monte-Carlo Frequency Dropout
Jan 20, 2025



Monte-Carlo (MC) Dropout provides a practical solution for estimating predictive distributions in deterministic neural networks. Traditional dropout, applied within the signal space, may fail to account for frequency-related noise common in medical imaging, leading to biased predictive estimates. A novel approach extends Dropout to the frequency domain, allowing stochastic attenuation of signal frequencies during inference. This creates diverse global textural variations in feature maps while preserving structural integrity -- a factor we hypothesize and empirically show is contributing to accurately estimating uncertainties in semantic segmentation. We evaluated traditional MC-Dropout and the MC-frequency Dropout in three segmentation tasks involving different imaging modalities: (i) prostate zones in biparametric MRI, (ii) liver tumors in contrast-enhanced CT, and (iii) lungs in chest X-ray scans. Our results show that MC-Frequency Dropout improves calibration, convergence, and semantic uncertainty, thereby improving prediction scrutiny, boundary delineation, and has the potential to enhance medical decision-making.
Rate-In: Information-Driven Adaptive Dropout Rates for Improved Inference-Time Uncertainty Estimation
Dec 10, 2024



Accurate uncertainty estimation is crucial for deploying neural networks in risk-sensitive applications such as medical diagnosis. Monte Carlo Dropout is a widely used technique for approximating predictive uncertainty by performing stochastic forward passes with dropout during inference. However, using static dropout rates across all layers and inputs can lead to suboptimal uncertainty estimates, as it fails to adapt to the varying characteristics of individual inputs and network layers. Existing approaches optimize dropout rates during training using labeled data, resulting in fixed inference-time parameters that cannot adjust to new data distributions, compromising uncertainty estimates in Monte Carlo simulations. In this paper, we propose Rate-In, an algorithm that dynamically adjusts dropout rates during inference by quantifying the information loss induced by dropout in each layer's feature maps. By treating dropout as controlled noise injection and leveraging information-theoretic principles, Rate-In adapts dropout rates per layer and per input instance without requiring ground truth labels. By quantifying the functional information loss in feature maps, we adaptively tune dropout rates to maintain perceptual quality across diverse medical imaging tasks and architectural configurations. Our extensive empirical study on synthetic data and real-world medical imaging tasks demonstrates that Rate-In improves calibration and sharpens uncertainty estimates compared to fixed or heuristic dropout rates without compromising predictive performance. Rate-In offers a practical, unsupervised, inference-time approach to optimizing dropout for more reliable predictive uncertainty estimation in critical applications.
STNAGNN: Spatiotemporal Node Attention Graph Neural Network for Task-based fMRI Analysis
Jun 17, 2024Task-based fMRI uses actions or stimuli to trigger task-specific brain responses and measures them using BOLD contrast. Despite the significant task-induced spatiotemporal brain activation fluctuations, most studies on task-based fMRI ignore the task context information aligned with fMRI and consider task-based fMRI a coherent sequence. In this paper, we show that using the task structures as data-driven guidance is effective for spatiotemporal analysis. We propose STNAGNN, a GNN-based spatiotemporal architecture, and validate its performance in an autism classification task. The trained model is also interpreted for identifying autism-related spatiotemporal brain biomarkers.
TAI-GAN: A Temporally and Anatomically Informed Generative Adversarial Network for early-to-late frame conversion in dynamic cardiac PET inter-frame motion correction
Feb 14, 2024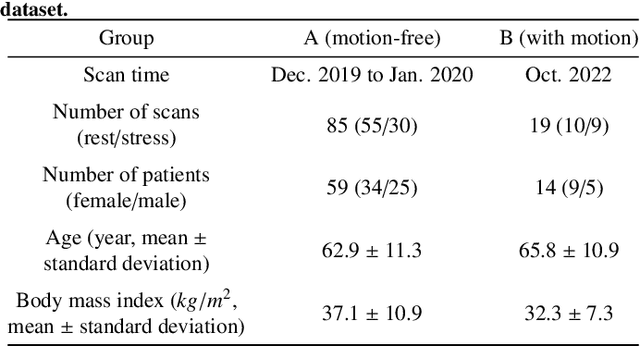
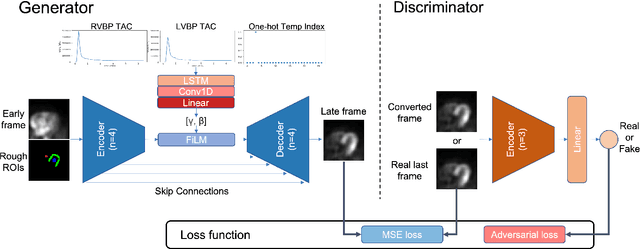
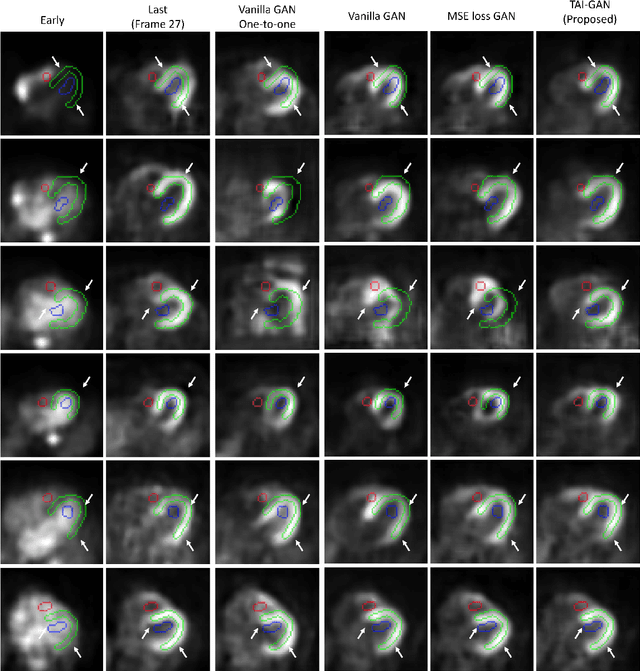
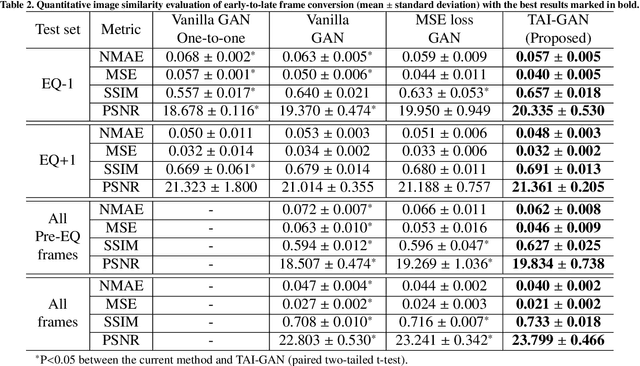
Inter-frame motion in dynamic cardiac positron emission tomography (PET) using rubidium-82 (82-Rb) myocardial perfusion imaging impacts myocardial blood flow (MBF) quantification and the diagnosis accuracy of coronary artery diseases. However, the high cross-frame distribution variation due to rapid tracer kinetics poses a considerable challenge for inter-frame motion correction, especially for early frames where intensity-based image registration techniques often fail. To address this issue, we propose a novel method called Temporally and Anatomically Informed Generative Adversarial Network (TAI-GAN) that utilizes an all-to-one mapping to convert early frames into those with tracer distribution similar to the last reference frame. The TAI-GAN consists of a feature-wise linear modulation layer that encodes channel-wise parameters generated from temporal information and rough cardiac segmentation masks with local shifts that serve as anatomical information. Our proposed method was evaluated on a clinical 82-Rb PET dataset, and the results show that our TAI-GAN can produce converted early frames with high image quality, comparable to the real reference frames. After TAI-GAN conversion, the motion estimation accuracy and subsequent myocardial blood flow (MBF) quantification with both conventional and deep learning-based motion correction methods were improved compared to using the original frames.
Learning Sequential Information in Task-based fMRI for Synthetic Data Augmentation
Aug 29, 2023



Insufficiency of training data is a persistent issue in medical image analysis, especially for task-based functional magnetic resonance images (fMRI) with spatio-temporal imaging data acquired using specific cognitive tasks. In this paper, we propose an approach for generating synthetic fMRI sequences that can then be used to create augmented training datasets in downstream learning tasks. To synthesize high-resolution task-specific fMRI, we adapt the $\alpha$-GAN structure, leveraging advantages of both GAN and variational autoencoder models, and propose different alternatives in aggregating temporal information. The synthetic images are evaluated from multiple perspectives including visualizations and an autism spectrum disorder (ASD) classification task. The results show that the synthetic task-based fMRI can provide effective data augmentation in learning the ASD classification task.