 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Foundational Monocular Depth Estimators to Fisheye Cameras with Calibration Tokens
Aug 06, 2025We propose a method to extend foundational monocular depth estimators (FMDEs), trained on perspective images, to fisheye images. Despite being trained on tens of millions of images, FMDEs are susceptible to the covariate shift introduced by changes in camera calibration (intrinsic, distortion) parameters, leading to erroneous depth estimates. Our method aligns the distribution of latent embeddings encoding fisheye images to those of perspective images, enabling the reuse of FMDEs for fisheye cameras without retraining or finetuning. To this end, we introduce a set of Calibration Tokens as a light-weight adaptation mechanism that modulates the latent embeddings for alignment. By exploiting the already expressive latent space of FMDEs, we posit that modulating their embeddings avoids the negative impact of artifacts and loss introduced in conventional recalibration or map projection to a canonical reference frame in the image space. Our method is self-supervised and does not require fisheye images but leverages publicly available large-scale perspective image datasets. This is done by recalibrating perspective images to fisheye images, and enforcing consistency between their estimates during training. We evaluate our approach with several FMDEs, on both indoors and outdoors, where we consistently improve over state-of-the-art methods using a single set of tokens for both. Code available at: https://github.com/JungHeeKim29/calibration-token.
Radar-Guided Polynomial Fitting for Metric Depth Estimation
Mar 21, 2025



We propose PolyRad, a novel radar-guided depth estimation method that introduces polynomial fitting to transform scaleless depth predictions from pretrained monocular depth estimation (MDE) models into metric depth maps. Unlike existing approaches that rely on complex architectures or expensive sensors, our method is grounded in a simple yet fundamental insight: using polynomial coefficients predicted from cheap, ubiquitous radar data to adaptively adjust depth predictions non-uniformly across depth ranges. Although MDE models often infer reasonably accurate local depth structure within each object or local region, they may misalign these regions relative to one another, making a linear scale-and-shift transformation insufficient given three or more of these regions. In contrast, PolyRad generalizes beyond linear transformations and is able to correct such misalignments by introducing inflection points. Importantly, our polynomial fitting framework preserves structural consistency through a novel training objective that enforces monotonicity via first-derivative regularization. PolyRad achieves state-of-the-art performance on the nuScenes, ZJU-4DRadarCam, and View-of-Delft datasets, outperforming existing methods by 30.3% in MAE and 37.2% in RMSE.
Progressive Test Time Energy Adaptation for Medical Image Segmentation
Mar 20, 2025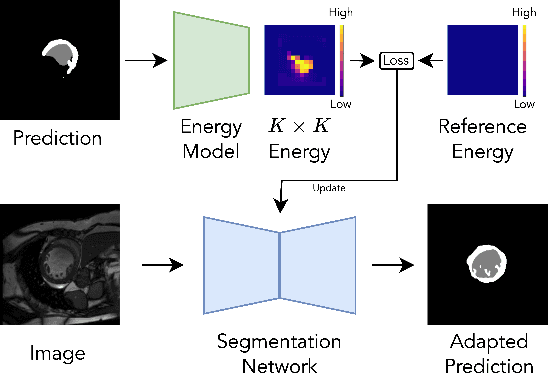
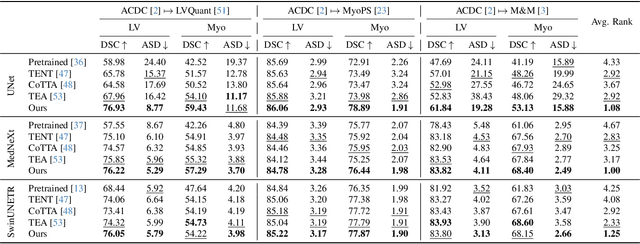
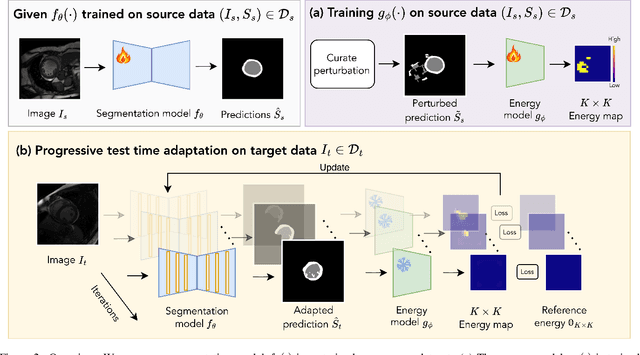
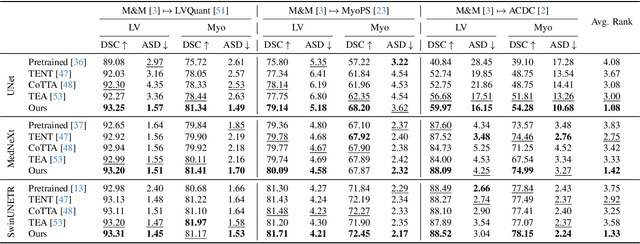
We propose a model-agnostic, progressive test-time energy adaptation approach for medical image segmentation. Maintaining model performance across diverse medical datasets is challenging, as distribution shifts arise from inconsistent imaging protocols and patient variations. Unlike domain adaptation methods that require multiple passes through target data - impractical in clinical settings - our approach adapts pretrained models progressively as they process test data. Our method leverages a shape energy model trained on source data, which assigns an energy score at the patch level to segmentation maps: low energy represents in-distribution (accurate) shapes, while high energy signals out-of-distribution (erroneous) predictions. By minimizing this energy score at test time, we refine the segmentation model to align with the target distribution. To validate the effectiveness and adaptability, we evaluated our framework on eight public MRI (bSSFP, T1- and T2-weighted) and X-ray datasets spanning cardiac, spinal cord, and lung segmentation. We consistently outperform baselines both quantitatively and qualitatively.
ProtoDepth: Unsupervised Continual Depth Completion with Prototypes
Mar 17, 2025



We present ProtoDepth, a novel prototype-based approach for continual learning of unsupervised depth completion, the multimodal 3D reconstruction task of predicting dense depth maps from RGB images and sparse point clouds. The unsupervised learning paradigm is well-suited for continual learning, as ground truth is not needed. However, when training on new non-stationary distributions, depth completion models will catastrophically forget previously learned information. We address forgetting by learning prototype sets that adapt the latent features of a frozen pretrained model to new domains. Since the original weights are not modified, ProtoDepth does not forget when test-time domain identity is known. To extend ProtoDepth to the challenging setting where the test-time domain identity is withheld, we propose to learn domain descriptors that enable the model to select the appropriate prototype set for inference. We evaluate ProtoDepth on benchmark dataset sequences, where we reduce forgetting compared to baselines by 52.2% for indoor and 53.2% for outdoor to achieve the state of the art.
TREND: Unsupervised 3D Representation Learning via Temporal Forecasting for LiDAR Perception
Dec 04, 2024



Labeling LiDAR point clouds is notoriously time-and-energy-consuming, which spurs recent unsupervised 3D representation learning methods to alleviate the labeling burden in LiDAR perception via pretrained weights. Almost all existing work focus on a single frame of LiDAR point cloud and neglect the temporal LiDAR sequence, which naturally accounts for object motion (and their semantics). Instead, we propose TREND, namely Temporal REndering with Neural fielD, to learn 3D representation via forecasting the future observation in an unsupervised manner. Unlike existing work that follows conventional contrastive learning or masked auto encoding paradigms, TREND integrates forecasting for 3D pre-training through a Recurrent Embedding scheme to generate 3D embedding across time and a Temporal Neural Field to represent the 3D scene, through which we compute the loss using differentiable rendering. To our best knowledge, TREND is the first work on temporal forecasting for unsupervised 3D representation learning. We evaluate TREND on downstream 3D object detection tasks on popular datasets, including NuScenes, Once and Waymo. Experiment results show that TREND brings up to 90% more improvement as compared to previous SOTA unsupervised 3D pre-training methods and generally improve different downstream models across datasets, demonstrating that indeed temporal forecasting brings improvement for LiDAR perception. Codes and models will be released.
UnCLe: Unsupervised Continual Learning of Depth Completion
Oct 23, 2024



We propose UnCLe, a standardized benchmark for Unsupervised Continual Learning of a multimodal depth estimation task: Depth completion aims to infer a dense depth map from a pair of synchronized RGB image and sparse depth map. We benchmark depth completion models under the practical scenario of unsupervised learning over continuous streams of data. Existing methods are typically trained on a static, or stationary, dataset. However, when adapting to novel non-stationary distributions, they "catastrophically forget" previously learned information. UnCLe simulates these non-stationary distributions by adapting depth completion models to sequences of datasets containing diverse scenes captured from distinct domains using different visual and range sensors. We adopt representative methods from continual learning paradigms and translate them to enable unsupervised continual learning of depth completion. We benchmark these models for indoor and outdoor and investigate the degree of catastrophic forgetting through standard quantitative metrics. Furthermore, we introduce model inversion quality as an additional measure of forgetting. We find that unsupervised continual learning of depth completion is an open problem, and we invite researchers to leverage UnCLe as a development platform.
RSA: Resolving Scale Ambiguities in Monocular Depth Estimators through Language Descriptions
Oct 03, 2024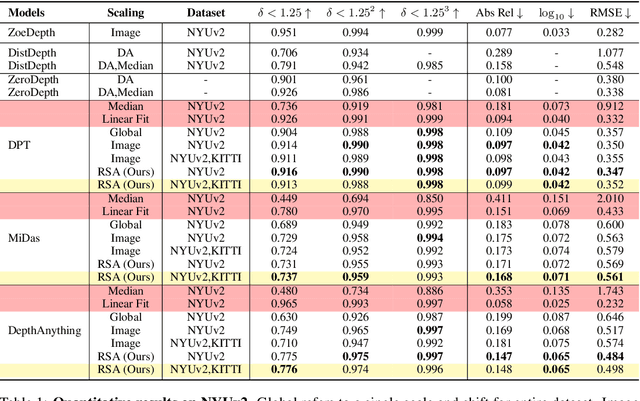
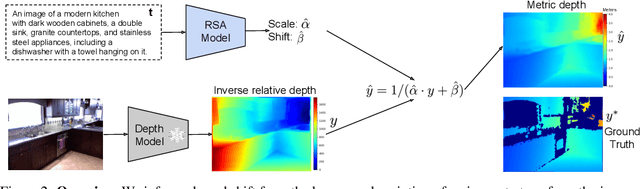
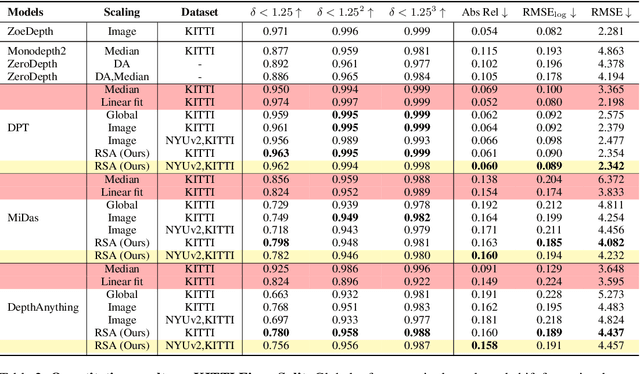

We propose a method for metric-scale monocular depth estimation. Inferring depth from a single image is an ill-posed problem due to the loss of scale from perspective projection during the image formation process. Any scale chosen is a bias, typically stemming from training on a dataset; hence, existing works have instead opted to use relative (normalized, inverse) depth. Our goal is to recover metric-scaled depth maps through a linear transformation. The crux of our method lies in the observation that certain objects (e.g., cars, trees, street signs) are typically found or associated with certain types of scenes (e.g., outdoor). We explore whether language descriptions can be used to transform relative depth predictions to those in metric scale. Our method, RSA, takes as input a text caption describing objects present in an image and outputs the parameters of a linear transformation which can be applied globally to a relative depth map to yield metric-scaled depth predictions. We demonstrate our method on recent general-purpose monocular depth models on indoors (NYUv2) and outdoors (KITTI). When trained on multiple datasets, RSA can serve as a general alignment module in zero-shot settings. Our method improves over common practices in aligning relative to metric depth and results in predictions that are comparable to an upper bound of fitting relative depth to ground truth via a linear transformation.
NeuroBind: Towards Unified Multimodal Representations for Neural Signals
Jul 19, 2024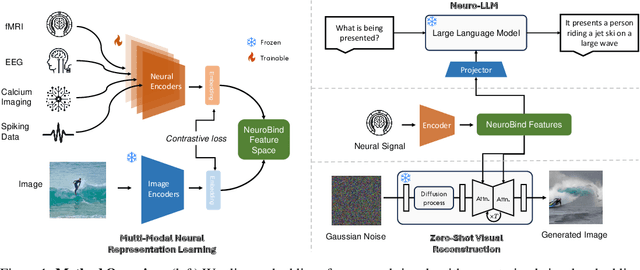
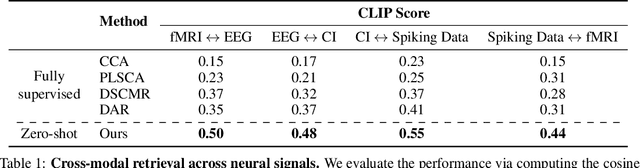

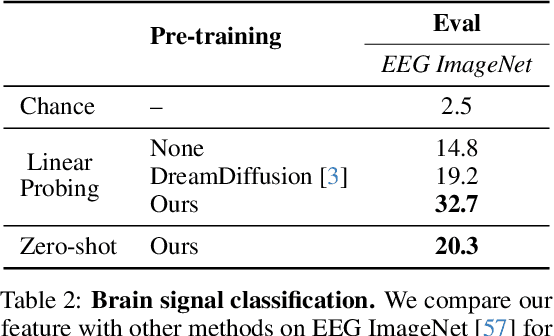
Understanding neural activity and information representation is crucial for advancing knowledge of brain function and cognition. Neural activity, measured through techniques like electrophysiology and neuroimaging, reflects various aspects of information processing. Recent advances in deep neural networks offer new approaches to analyzing these signals using pre-trained models. However, challenges arise due to discrepancies between different neural signal modalities and the limited scale of high-quality neural data. To address these challenges, we present NeuroBind, a general representation that unifies multiple brain signal types, including EEG, fMRI, calcium imaging, and spiking data. To achieve this, we align neural signals in these image-paired neural datasets to pre-trained vision-language embeddings. Neurobind is the first model that studies different neural modalities interconnectedly and is able to leverage high-resource modality models for various neuroscience tasks. We also showed that by combining information from different neural signal modalities, NeuroBind enhances downstream performance, demonstrating the effectiveness of the complementary strengths of different neural modalities. As a result, we can leverage multiple types of neural signals mapped to the same space to improve downstream tasks, and demonstrate the complementary strengths of different neural modalities. This approach holds significant potential for advancing neuroscience research, improving AI systems, and developing neuroprosthetics and brain-computer interfaces.
All-day Depth Completion
May 27, 2024



We propose a method for depth estimation under different illumination conditions, i.e., day and night time. As photometry is uninformative in regions under low-illumination, we tackle the problem through a multi-sensor fusion approach, where we take as input an additional synchronized sparse point cloud (i.e., from a LiDAR) projected onto the image plane as a sparse depth map, along with a camera image. The crux of our method lies in the use of the abundantly available synthetic data to first approximate the 3D scene structure by learning a mapping from sparse to (coarse) dense depth maps along with their predictive uncertainty - we term this, SpaDe. In poorly illuminated regions where photometric intensities do not afford the inference of local shape, the coarse approximation of scene depth serves as a prior; the uncertainty map is then used with the image to guide refinement through an uncertainty-driven residual learning (URL) scheme. The resulting depth completion network leverages complementary strengths from both modalities - depth is sparse but insensitive to illumination and in metric scale, and image is dense but sensitive with scale ambiguity. SpaDe can be used in a plug-and-play fashion, which allows for 25% improvement when augmented onto existing methods to preprocess sparse depth. We demonstrate URL on the nuScenes dataset where we improve over all baselines by an average 11.65% in all-day scenarios, 11.23% when tested specifically for daytime, and 13.12% for nighttime scenes.
WorDepth: Variational Language Prior for Monocular Depth Estimation
Apr 05, 2024



Three-dimensional (3D) reconstruction from a single image is an ill-posed problem with inherent ambiguities, i.e. scale. Predicting a 3D scene from text description(s) is similarly ill-posed, i.e. spatial arrangements of objects described. We investigate the question of whether two inherently ambiguous modalities can be used in conjunction to produce metric-scaled reconstructions. To test this, we focus on monocular depth estimation, the problem of predicting a dense depth map from a single image, but with an additional text caption describing the scene. To this end, we begin by encoding the text caption as a mean and standard deviation; using a variational framework, we learn the distribution of the plausible metric reconstructions of 3D scenes corresponding to the text captions as a prior. To "select" a specific reconstruction or depth map, we encode the given image through a conditional sampler that samples from the latent space of the variational text encoder, which is then decoded to the output depth map. Our approach is trained alternatingly between the text and image branches: in one optimization step, we predict the mean and standard deviation from the text description and sample from a standard Gaussian, and in the other, we sample using a (image) conditional sampler. Once trained, we directly predict depth from the encoded text using the conditional sampler. We demonstrate our approach on indoor (NYUv2) and outdoor (KITTI) scenarios, where we show that language can consistently improve performance in both.