 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Foundational Monocular Depth Estimators to Fisheye Cameras with Calibration Tokens
Aug 06, 2025We propose a method to extend foundational monocular depth estimators (FMDEs), trained on perspective images, to fisheye images. Despite being trained on tens of millions of images, FMDEs are susceptible to the covariate shift introduced by changes in camera calibration (intrinsic, distortion) parameters, leading to erroneous depth estimates. Our method aligns the distribution of latent embeddings encoding fisheye images to those of perspective images, enabling the reuse of FMDEs for fisheye cameras without retraining or finetuning. To this end, we introduce a set of Calibration Tokens as a light-weight adaptation mechanism that modulates the latent embeddings for alignment. By exploiting the already expressive latent space of FMDEs, we posit that modulating their embeddings avoids the negative impact of artifacts and loss introduced in conventional recalibration or map projection to a canonical reference frame in the image space. Our method is self-supervised and does not require fisheye images but leverages publicly available large-scale perspective image datasets. This is done by recalibrating perspective images to fisheye images, and enforcing consistency between their estimates during training. We evaluate our approach with several FMDEs, on both indoors and outdoors, where we consistently improve over state-of-the-art methods using a single set of tokens for both. Code available at: https://github.com/JungHeeKim29/calibration-token.
UnCLe: Unsupervised Continual Learning of Depth Completion
Oct 23, 2024



We propose UnCLe, a standardized benchmark for Unsupervised Continual Learning of a multimodal depth estimation task: Depth completion aims to infer a dense depth map from a pair of synchronized RGB image and sparse depth map. We benchmark depth completion models under the practical scenario of unsupervised learning over continuous streams of data. Existing methods are typically trained on a static, or stationary, dataset. However, when adapting to novel non-stationary distributions, they "catastrophically forget" previously learned information. UnCLe simulates these non-stationary distributions by adapting depth completion models to sequences of datasets containing diverse scenes captured from distinct domains using different visual and range sensors. We adopt representative methods from continual learning paradigms and translate them to enable unsupervised continual learning of depth completion. We benchmark these models for indoor and outdoor and investigate the degree of catastrophic forgetting through standard quantitative metrics. Furthermore, we introduce model inversion quality as an additional measure of forgetting. We find that unsupervised continual learning of depth completion is an open problem, and we invite researchers to leverage UnCLe as a development platform.
Portrait3D: Text-Guided High-Quality 3D Portrait Generation Using Pyramid Representation and GANs Prior
Apr 16, 2024
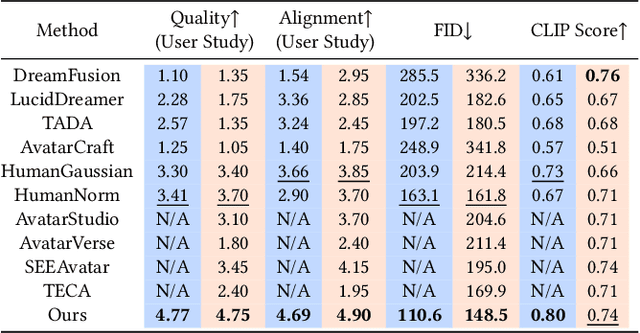
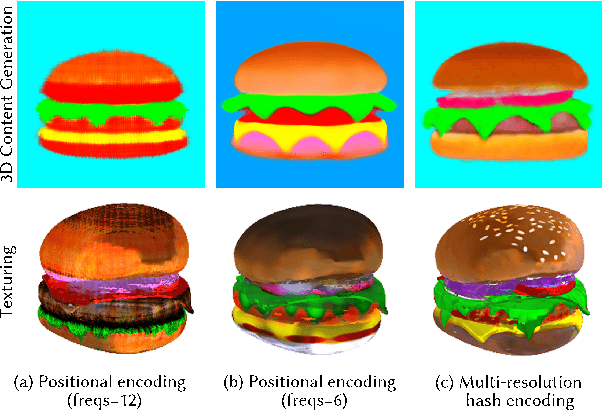
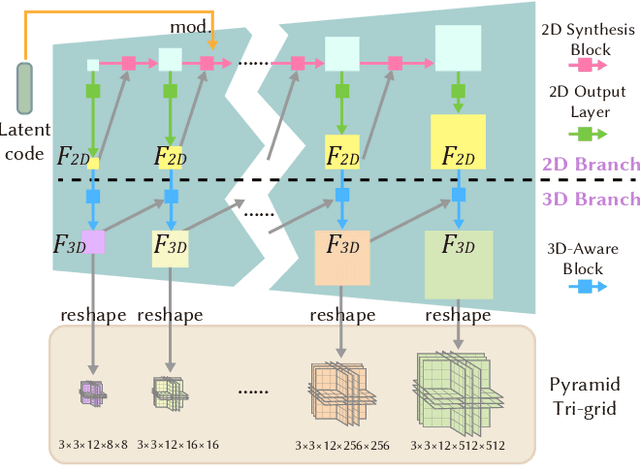
Existing neural rendering-based text-to-3D-portrait generation methods typically make use of human geometry prior and diffusion models to obtain guidance. However, relying solely on geometry information introduces issues such as the Janus problem, over-saturation, and over-smoothing. We present Portrait3D, a novel neural rendering-based framework with a novel joint geometry-appearance prior to achieve text-to-3D-portrait generation that overcomes the aforementioned issues. To accomplish this, we train a 3D portrait generator, 3DPortraitGAN-Pyramid, as a robust prior. This generator is capable of producing 360{\deg} canonical 3D portraits, serving as a starting point for the subsequent diffusion-based generation process. To mitigate the "grid-like" artifact caused by the high-frequency information in the feature-map-based 3D representation commonly used by most 3D-aware GANs, we integrate a novel pyramid tri-grid 3D representation into 3DPortraitGAN-Pyramid. To generate 3D portraits from text, we first project a randomly generated image aligned with the given prompt into the pre-trained 3DPortraitGAN-Pyramid's latent space. The resulting latent code is then used to synthesize a pyramid tri-grid. Beginning with the obtained pyramid tri-grid, we use score distillation sampling to distill the diffusion model's knowledge into the pyramid tri-grid. Following that, we utilize the diffusion model to refine the rendered images of the 3D portrait and then use these refined images as training data to further optimize the pyramid tri-grid, effectively eliminating issues with unrealistic color and unnatural artifacts. Our experimental results show that Portrait3D can produce realistic, high-quality, and canonical 3D portraits that align with the prompt.
Binding Touch to Everything: Learning Unified Multimodal Tactile Representations
Jan 31, 2024



The ability to associate touch with other modalities has huge implications for humans and computational systems. However, multimodal learning with touch remains challenging due to the expensive data collection process and non-standardized sensor outputs. We introduce UniTouch, a unified tactile model for vision-based touch sensors connected to multiple modalities, including vision, language, and sound. We achieve this by aligning our UniTouch embeddings to pretrained image embeddings already associated with a variety of other modalities. We further propose learnable sensor-specific tokens, allowing the model to learn from a set of heterogeneous tactile sensors, all at the same time. UniTouch is capable of conducting various touch sensing tasks in the zero-shot setting, from robot grasping prediction to touch image question answering. To the best of our knowledge, UniTouch is the first to demonstrate such capabilities. Project page: https://cfeng16.github.io/UniTouch/